
如何快速定位Redis热key?
极客时间编辑部
讲述:丁婵大小:8.45M时长:06:09
在 Redis 中,热 key 指的是那些在一段时间内访问频次比较高的键值,对系统稳定性和可用性造成影响,引发用户不满。因此,在日常的工作中,开发者需要着重避免这种情况的出现。近日,饿了么 CI 框架工具部后端专家韩亮在InfoQ分享了快速定位 Redis 热 key 的经验,供你参考。
可能的方案
热点 key 不可能完全避免,因此需要一种方法能够在出现问题的时候快速定位问题根源。如果要设计定位方案的话,可以从 Redis 请求路径上的节点来着手,比如在客户端、中间层和服务端,以下是业界常见的几种方案。
1. 客户端收集上报
改动 Redis SDK,记录每个请求,定时把收集到的数据上报,然后由统一的服务进行聚合计算。方案直观简单,但没法适应多语言架构,一方面多语言 SDK 对齐是个问题,另一方面后期 SDK 的维护升级会面临较大困难,成本很高。
2. 代理层收集上报
如果所有的 Redis 请求都经过代理的话,可以考虑改动 Proxy 代码进行收集,思路与客户端基本类似。该方案对使用方完全透明,能够解决客户端 SDK 的语言异构和版本升级问题,不过开发成本高。
3. Redis 数据定时扫描
Redis 在 4.0 版本之后添加了 Hotkeys 查找特性,但由于需要扫描整个 keyspace,实时性比较差,另外扫描耗时与 key 的数量正相关,如果 key 的数量比较多,耗时可能会非常长。
4. Redis 节点抓包解析
在可能存在热 key 的节点上 (流量倾斜判断),通过 TCPDump 抓取一段时间内的流量并上报,然后由一个外部的程序进行解析、聚合和计算。该方案无需侵入现有的 SDK 或者 Proxy 中间件,开发维护成本可控,但是,热 key 节点的网络流量和系统负载已经比较高了,抓包可能会使情况进一步恶化。
饿了么的选择
在饿了么内部,所有的 Redis 请求都是经过透明代理 Samaritan 的,并且该代理是由团队内部开发维护的,在代理层改造的成本完全受控,因此饿了么选择了方案二,即在代理层进行收集上报。
大的方向确定之后,需要考虑具体的细节,比如:
记录所有请求如何保证不占用过多的内存甚至 OOM ?
记录所有请求如何保证代理的性能,请求耗时不会有明显的上升?
针对第一个细节,既然只关心热 key 而不是要统计所有 key 的 Counter,那么就可以用 LFU 只保留访问频次最高的,对于第二个细节,则需要结合代理具体的实现去考虑。
下图是代理内部的实现方案,略去了一些无关的细节:
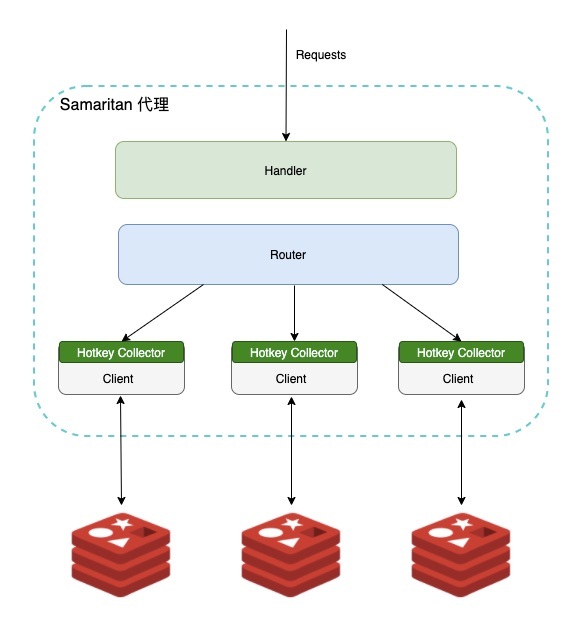
每个 Redis node 会创建与之对应的唯一 Client,其上的所有请求都采用 Pipeline 执行,每个 Client 内部都有自己的 Hotkey Collector,不同 Collector 间相互独立。
Hotkey Collector 包含 LFU Counter、Syncer 和 Etrace Client 三部分。LFU Counter 负责记录 key 的访问频次,Syncer 会定期将统计数据通过 Etrace Client 发送给远端的服务器。另外,为了避免向服务端发送过多无效的数据,内部会预先设置一个阈值,超过阈值的才发送到服务端。
按照预先的设计,就会有一个实时计算的服务去拉取 Etrace 上的数据,进行聚合计算得到当前的热点 key。但不幸的是代理中间件改造上线后的很长一段时间内,这个实时计算服务的开发都未被提上日程,主要是因为 ROI 低和维护成本高,因此在业务上如果要查热 key 就只能在 Etrace 上手动戳 event 碰运气。
由于使用起来很麻烦,用户在第一次体验之后基本就放弃了。当时急需解决用户体验和系统复杂度的问题,让该特性真正赋能业务。
最终的方案
对上述的方案进行优化,可以从以下两个方面入手:
如何在不增加实时计算组件提升成本的前提下高效地聚合数据?
如何提升用户体验,让用户方便地使用?
针对第一点,把聚合逻辑放在代理进程内,这样就不用再依赖任何外部组件,可以降低整个系统的复杂度和维护成本。而就易用性和使用体验上来说,如果聚合的数据在进程内,可以提供 Hotkey 类似的自定义命令,让用户通过 redis-cli 直接获取。最终的方案如下:
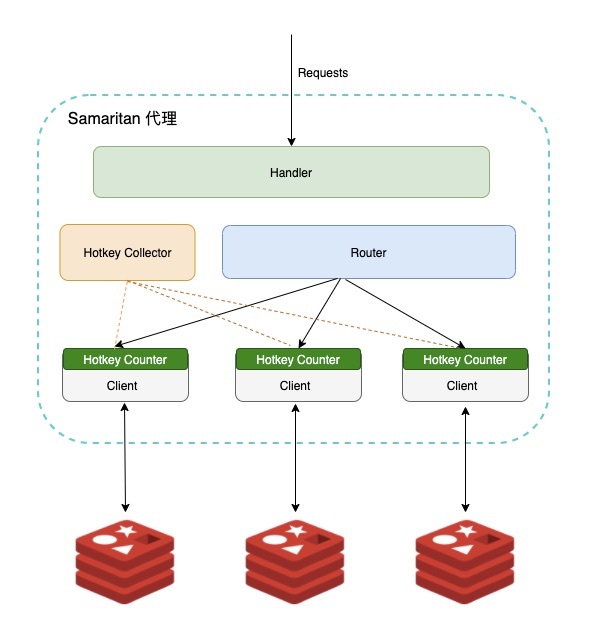
每个集群会有一个全局的 Hotkey Collector,每个 Client 上有自己独立的 Counter,Counter 依旧采用前面提到的 LFU 算法,Collector 会定时收集每个 Counter 的数据并进行聚合,聚合的时候不会使用真实的计数,而是使用概率计数,并且为了适应访问模式的变化,Counter 值会随着时间衰减,整体上与 Redis LFU 非常类似。
当前的方案虽然能够快速定位系统中的热 key,但并没有真正解决热 key 本身带来的问题,仍然需要业务方自行改造或者将那些热点 key 调度到单独的节点上,成本较高。此外,也需要不断优化内存、数据一致性和性能的问题,后续会考虑在代理内实现热点 key 的缓存。
以上就是今天的内容,希望对你有所帮助。
相关链接:热 key 实时收集功能开源代码

公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结
该免费文章来自《极客视点》,如需阅读全部文章,
请先领取课程
请先领取课程
免费领取
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(1)
- 最新
- 精选
 言十年PHP面试 会考这个1
言十年PHP面试 会考这个1
收起评论