
百度预训练模型ERNIE比BERT提升近10个点
高高
讲述:丁婵大小:5.44M时长:03:57
北京时间 12 月 10 日,百度预训练模型界 ERNIE 在自然语言处理领域权威数据集 GLUE 中登上榜首,并以 9 个任务平均得分首次突破 90 大关刷新该榜单历史,其超越微软 MTDNN-SMART, 谷歌 T5、ALBERT 等一众国际顶级预训练模型。
众所周知,通用语言理解评估基准 GLUE 是自然语言处理领域最权威的排行榜之一,由纽约大学、华盛顿大学、谷歌 DeepMind 等机构联合推出,以其涵盖大量不同类型的 NLP 任务,包括自然语言推断、语义相似度、问答匹配、情感分析等 9 大任务,成为衡量自然语言处理研究进展的行业标准。因此,吸引了谷歌、Facebook、微软等国际顶尖公司以及斯坦福大学、卡耐基·梅隆大学等顶尖大学参加。GLUE 排行榜的效果,在一定程度上成为了衡量各机构自然语言处理预训练技术水平最重要的指标之一。此次能够超越国际顶尖公司及高校荣登榜首,背后是百度 NLP 技术的长足积累。
2018 年底以来,以 BERT 为代表的预训练模型大幅提升了自然语言处理任务的基准效果,取得了显著技术突破,基于大规模数据的预训练技术在自然语言处理领域变得至关重要。众 AI 公司纷纷发力预训练领域,相继发布了 XLNet、RoBERTa、ALBERT、T5 等预训练模型。百度也先后发布了 ERNIE 1.0、ERNIE 2.0,在 16 个中英数据集上取得了当时的 SOTA。
从 GLUE 排行榜上来看,BERT 使用预训练加微调的方式,相对过往的基线成绩大幅提升各任务的效果,首次突破了 80 大关。XLNet、RoBERTa、T5、MTDNN-SMART 等模型则分布在 88-89 分范围,人类水平则是 87.1。
百度 ERNIE 此次登顶,成为首个突破 90 大关的模型,并在 CoLA、SST-2、QQP、WNLI 等数据集上达到 SOTA。相对 BERT 的 80.5 的成绩,提升近 10 个点,取得了显著的效果突破。以下为百度 ERNIE 2.0 原理示意图:
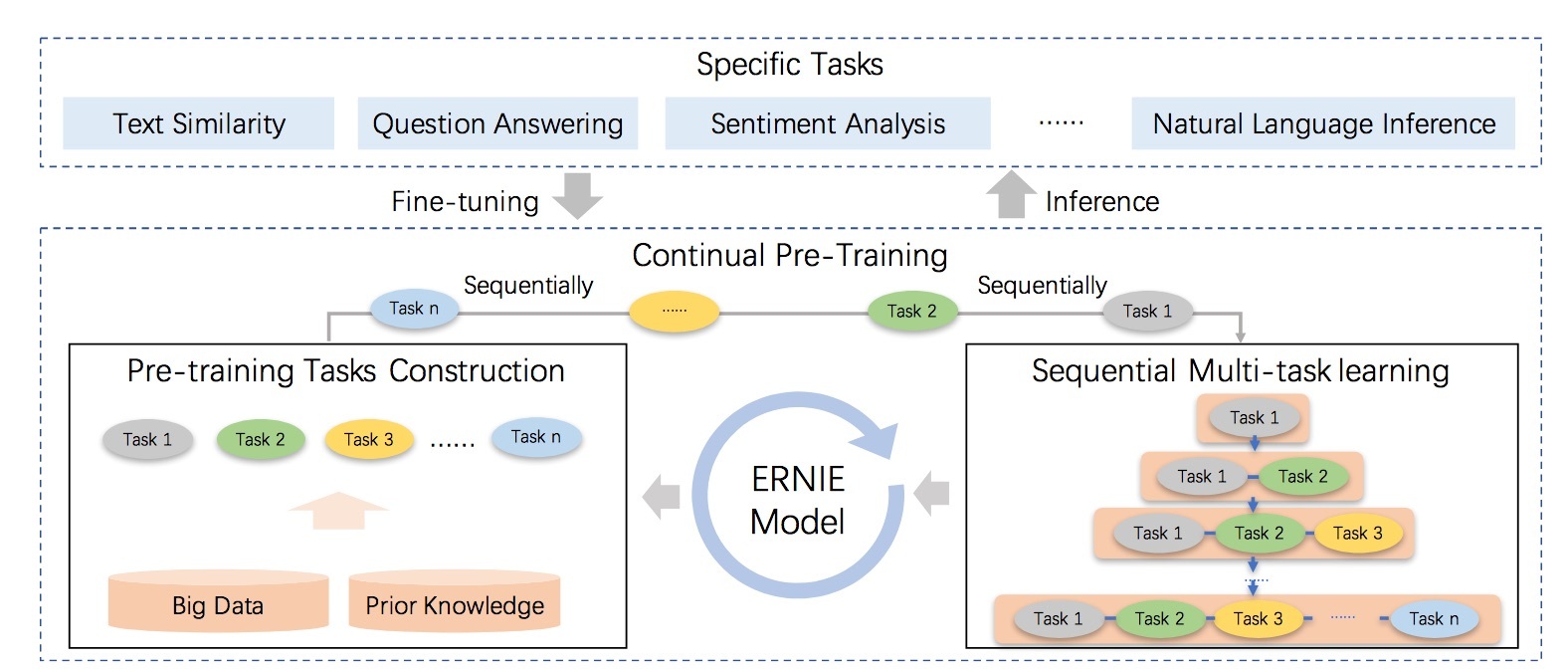
ERNIE 2.0 持续学习的语义理解框架, 支持增量引入不同角度的自定义预训练任务,通过多任务学习对模型进行训练更新,每当引入新任务时,该框架可在学习该任务的同时,不遗忘之前学到过的信息。
此次登顶的模型主要基于 ERNIE 2.0 持续学习语义理解框架下的系列优化。引入更多新预训练任务, 例如引入基于互信息的动态边界掩码算法。对预训练数据和模型结构也做了精细化调整。
同时,百度 ERNIE 2.0 的论文已被国际人工智能顶级学术会议 AAAI-2020 收录,AAAI-2020 将于 2020 年 2 月 7 日 -12 日在美国纽约举行, 届时百度的技术团队将会进一步展示近期的技术成果。
据悉,百度 ERNIE 预训练技术已广泛地应用于公司内外多个产品和技术场景,其在百度搜索、小度音箱、信息流推荐等一系列产品应用中提升技术效果和用户体验的同时也在逐步赋能各行各业。
以上就是今天的内容,希望对你有所帮助。

公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结
该免费文章来自《极客视点》,如需阅读全部文章,
请先领取课程
请先领取课程
免费领取
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论