
NLP技术也能帮助程序分析?
陈立庚
讲述:子阳大小:2.28M时长:04:58
众所周知,在机器学习领域中,计算机视觉、自然语言处理和语音识别的技术已经发展的非常成熟,都已经有非常好的效果。同时,在系统安全领域,也有非常多的研究者,正在尝试使用非常大量的数据进行分析,以完成一些人类难以完成的挑战。
以程序分析为例,从源码,经过编译获得中间语言、汇编码,再到二进制,最终进行运行,是一个很复杂的过程,而研究者就希望反向从二进制获得更多和源码直接相关的信息,以达成自身的研究目的,这就是所谓的“逆向工程”。然而,在逆向工程中,本身就具有非常多的问题,常常让研究者头疼不已。
二进制相似度是在程序分析中非常重要的一环,其应用范围非常广泛,如果知道相应的程序相似度,对于代码克隆检测、恶意程序检测都能起到良好的辅助,甚至决定性的作用。然而程序在进行商用的过程中,为了防止源码被逆向工程轻易获取到,混淆和信息的缺失是非常常见的。在 19 年 S&P(CCF-A)上,出现了一个很有意思的工程,其利用了 NLP 领域中 PV-DM 的算法,巧妙的进行了迁移,解决了二进制相似度比较中,混淆和信息缺失的问题。
具体而言,同一段源码通过不同的编译选项,可以获得不同结构的二进制形态。也就是编译结果完全不同,这使得传统或现有的方法处理起来十分棘手。因此需要有比较好的方法,既能够将结构化信息保留,又能够将语义信息提取出来。
首先,由于同一类的操作数或操作符“距离”都比较接近,也就应证了其语义特征比较接近。通过比较传统的方法,比如 wrod2vec,已经可以比较好的解决这一类的问题。
除了解决语义的问题,仍有二进制结构性的问题亟待解决,如何将混淆和非混淆的二进制进行相似度的对比,是一个很难的问题。好在 NLP 领域已经有类似问题的解决方案了,就是 PV-DM。其核心思想就是多存储一个和段落相关的字段,以获得结构化的信息。
虽然,在英文的自然语言领域,其文本和汇编语言非常相近,但是也不能直接套用 PV-DM 用于汇编语言的处理,但是有很多可以借鉴的地方,是可以帮助这样的问题进行建模的。
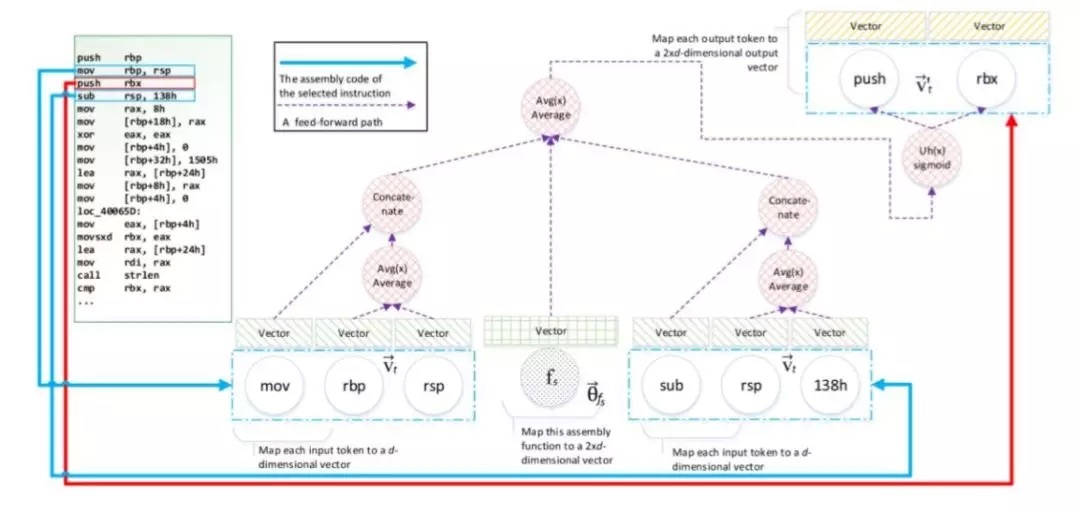
以图中的这段示例代码为例,我们的目标是对“push rbx”这段代码进行向量化,借鉴 PV-DM 算法的思想,我们通过对于上下文的获取,即“mov rbp,rsp”和“sub rsp,138h”的向量,对应获得两段向量,并分别对它们这段汇编语句中的两个操作数对应的向量取平均值,再拼接上操作符对应的向量。分别完成对于这两段汇编语句向量化操作之后,再通过对于核心语句的映射关系之后,对这三段汇编语句取向量平均值,再通过 sigmoid 函数,就可以获得最终的结果,以此获得最终的向量表示。
众所周知的是,一段相同的源码经过 O2 和 O3 的编译,其二进制的表现可能比较类似,是因为 O3 比 O2 多出的编译选项,且条件相对苛刻一些。但是对比经过 O0 和 O3 编译的源码,那相似度人眼都难以分辨,不仅仅是表现在整体的大小,同时也表现在 basicblock 的个数,以及内在的逻辑。
而基于 PV-DM 的新型表示方式,有非常有效的结果,可以同时体现其语义和结构化信息。更令人惊喜的是,当经过 LLVM 等工具的混淆之后,其相似度的检出率还是比较高,且能与其竞争的方法仅有原始的 PV-DM 方法,可见其对于原有结构化信息的还原程度之高。
相比之下,对于商用化软件经常存在混淆的情况,然而优化等级是可以进行预先判断的。可见,对于这样的二进制相似度对比问题,更应该把基于混淆的问题进行解决。当人们能对进行过混淆的二进制进行相似度对比的时候,就有更多的场景可以应用了。例如本文中,还对公开的漏洞数据库进行了检索对比,也有不错的发现。对于不同编译器、不同优化等级、不同工程中的 heartbleed 漏洞均有不同程度的检出,也给之后的漏洞检测工作带来了新的启发。
以上就是今天的内容,希望对你有所帮助。
本文转载自公众号 SIGAI(ID:SIGAICN)。

公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结
该免费文章来自《极客视点》,如需阅读全部文章,
请先领取课程
请先领取课程
免费领取
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论