
如何删除PB级重复数据?
极客时间编辑部
讲述:丁婵大小:2.68M时长:05:51
Mixpanel 通过网络从移动端、浏览器端和服务器端的客户接入了千万亿字节的事件数据。由于网络的不可靠性,客户可能会不断重复发送事件请求,直到他们收到来自 Mixpanel 的连接成功(200 OK)消息。虽然这种重试策略避免了数据丢失,但是在系统中创建了大量的重复事件。对这类重复事件的数据的分析也非常容易产生问题,因为它对所发生的事给出了一个不准确的描述,这也会导致 Mixpanel 偏离其它正在同步的客户端数据系统,如数据仓库。
近日,分布式系统工程师卡普里希·拉马钱德兰(Karthick Ramachandran)分享了他们公司 PB 级规模的事件数据去重解决方案,具体如下。
为解决这个问题,我们需要一个能够满足以下要求的方案:
可扩展性:能够扩展到百万事件 / 秒的接入量
低成本:为接入、存储和查询优化成本 / 性能负载
可追溯性:能够对任意发送的事件进行重复识别
可恢复性:保留重复数据从而在配置错误时可以回滚
可维护性:最小化运营负载
业界有很多富有创造性的方法来解决数据去重问题。其核心策略是在接入层构建一个能够去重的的基础设施。客户发送的每个事件都有一个唯一的 insert_id 属性标识。数据去重基础设施会将所有事件的 insert_id 保存一定期限,期间将会与每个新事件进行配对,以查找去重标识。键值通常是用存储的分片的 RocksDB 或 Cassandra。通过使用布隆过滤器来优化存储中的查找成本。这种架构能够确保在系统入口点就将重复内容清除。
但是,这种方法并不符合我们的要求,因为它除了具备扩展性,其他要求都不符合。因此,我们的方案是接入所有事件并在读取时去重,该方案也满足了前面所有的要求。每次查询时,通过构建一个包含所有 $insert_id 的哈希表可以很容易地在读取时实现去重;但是,这会给系统增加一些额外的开销。在详细介绍这个方案之前,让我们先回顾一下 Mixpanel 架构的几个关键技术。
其一,基于项目、用户和时间的分片。Mixpanel 的分析数据库 Arb 按照项目、用户和时间对数据文件进行了分片。这可以确保指定用户的所有数据都可以共同保存在一个位置,查询时也可以在相关的时间段同时覆盖多个用户。
其二,Lambda 架构。在 Arb 中,所有事件都被写入 AOF(只允许追加的文件),这些文件被周期性地索引(压缩)到后台的柱状文件中。AOF 在达到某个大小或时间阈值时,就会被索引。Arb 通过扫描小型的、实时的 AOF 和大型的、历史的、索引的文件,从而确保查询的实时性和高效性。
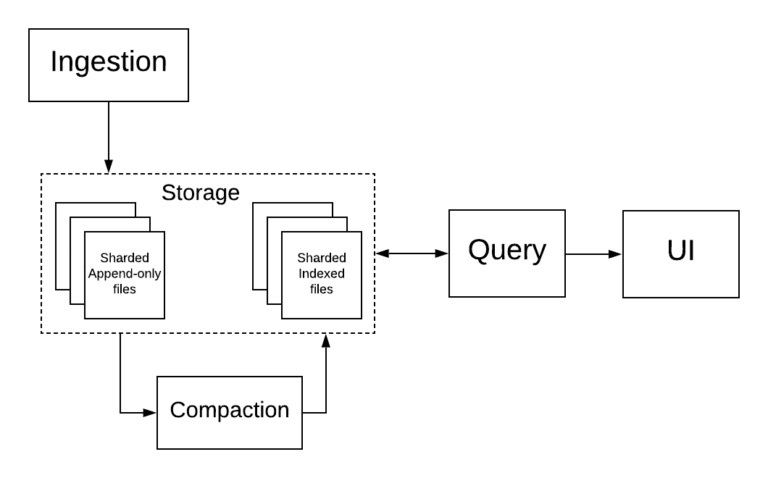
根据这些属性特征,我们可以在搜索空间中搜索项目、用户和日期的重复事件,即搜索单个 Arb 碎片;通过与 Lambda 架构一起摊销来最小化去重开销,从而维护查询的实时和高效。这帮助我们实现了一个满足所有要求的解决方案。
在 Mixpanel 的基础设施中,在索引和查询时都可以去重。
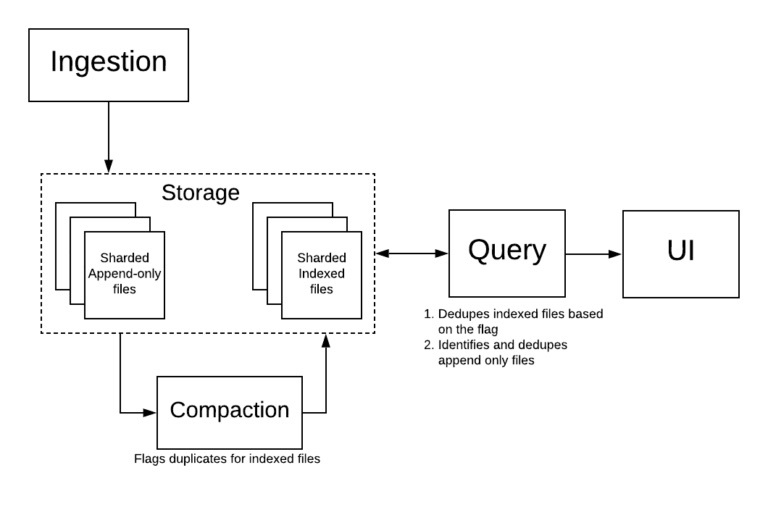
我们的索引器在内存中维护了一个 hashset,该 hashset 通过 $insert_id 保存了被索引文件中的所有事件。如果某个事件命中,则对该事件设置一个索引格式的重复标记位。这个过程的开销很小,毕竟索引是在细粒度分片级别进行的。
查询时,由于使用了 Lambda 架构,我们可以同时扫描索引文件和 AOF。对于索引文件,我们可以检查是否设置了重复位,如果设置了,则跳过处理事件。对于那些小的 AOF,查询可以对 $insert_id 基于散列去重,这样做既实时又高效。
我们从实验中发现,当索引含有 2% 重复的文件时会增加 4% 到 10% 的时间开销。但这并没有对用户体验产生直接影响,因为索引是一个离线过程。
对于查询时间,当额外读取一个事件的标志位时会增加大约 10ns 的时间。由于增加了额外的列,这使查询时间增加了近 2%。每读取 1000 万个事件会增加约 0.1 秒(100 毫秒)的时间开销。作为参考,由于采取了基于项目、用户和时间的分片,Mixpanel 目前最大的柱状文件包含大约 200 万个事件。我们认为在时间成本上的损失是完全可以接受的,因为我们在数据的保留期限和运营成本上都获得了更大的回报。
以上就是今天的内容,希望对你有所帮助。

公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结
该免费文章来自《极客视点》,如需阅读全部文章,
请先领取课程
请先领取课程
免费领取
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(1)
- 最新
- 精选
 feifei从内存开销以及速度来说,还是布隆过滤器更优
feifei从内存开销以及速度来说,还是布隆过滤器更优
收起评论