
如何选择适合你的深度学习模型?
Suleiman Khan
讲述:丁婵大小:2.61M时长:05:41
谷歌 BERT 以及其它基于 Transformer 的模型近来席卷整个 NLP 领域,并在多项任务中全面超越原有最强技术方案。最近,谷歌又对 BERT 进行了多项改进,迎来一系列相当强势的提升。在本文中,我们将共同探讨各类 BERT 相关模型的相似与不同,希望帮助你结合自身需求找到最理想的选项。
1.BERT
这是一种双向 Transformer,旨在利用大量未标记文本数据进行预训练,从而学习并掌握某种语言表达形式。更重要的是,这种表达形式还可以针对特定机器学习任务进行进一步调优。虽然 BERT 在多项任务中都带来了超越以往最强 NLP 技术的实际表现,但其性能的提升,主要还是归功于双向 Transformer、掩蔽语言模型与下一结构预测(Next Structure Prediction),外加谷歌本身强大的数据资源与计算能力。
最近,NLP 业界又出现了多种旨在改进 BERT 预测指标或计算速度的新方法,但却始终难以同时达成这两大提升目标。其中 XLNet 与 RoBERTa 推动性能更上一层楼,而 DistilBERT 则改善了推理速度。下图为各种方法之间的特性比对,你可以点击文档进行查看。
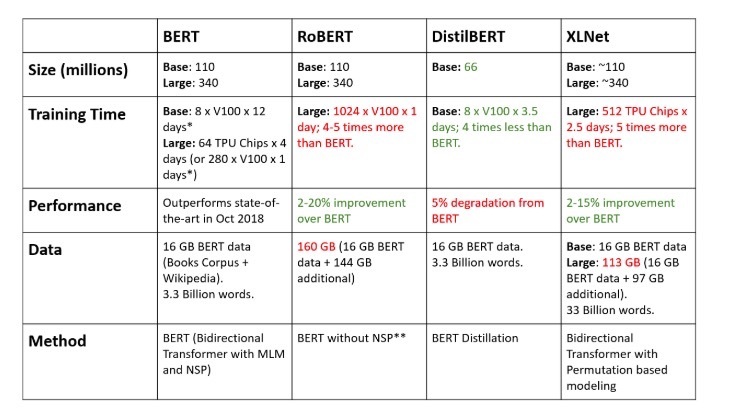
2.XLNet
这是一种大型双向 Transformer,采用的是一种经过改进的训练方法。这种训练方法能够利用规模更大的数据集与更强的计算能力在 20 项语言任务中获得优于 BERT 的预测指标。
为了改进训练方法,XLNet 还引入了转换语言建模,其中所有标记都按照随机顺序进行预测。这就与 BERT 的掩蔽语言模型形成了鲜明对比。具体来讲,BERT 只预测文本中的掩蔽部分(占比仅为 15%)。这种方法也颠覆了传统语言模型当中,所有标记皆按顺序进行预测的惯例。新的方法帮助模型掌握了双向关系,从而更好地处理单词之间的关联与衔接方式。此外该方法还采用 Transformer XL 作为基础架构,以便在非排序训练场景下同样带来良好的性能表现。
3.RoBERTa(A Robustly Optimized BERT Pretraining Approach)
RoBERTa 是 Facebook 公司推出的,经过健壮性优化的 BERT 改进方案。从本质上讲,RobERTa 在 BERT 的基础上进行了再次训练,并在改善训练方法之余将数据总量与计算资源提升了 10 倍。
为了优化训练过程,RoBERTa 移除了 BERT 预训练中的下一语句预测(NSP)任务,转而采用动态掩蔽以实现训练轮次中的掩蔽标记变更。此外,Facebook 还证实,更大批准的训练规模确实能够提升模型性能。
更重要的是,RoBERTa 利用 160 GB 文本进行预训练,其中包括 16 GB 文本语料库以及 BERT 所使用的英文版维基百科。其余部分则包括 CommonCrawl News 数据集(包含 6300 万篇文章,总计 76 GB)、Web 文本语料库(38 GB)以及来自 Common Crawl 的故事素材(31 GB)。这一素材组合在 1024 个 V100 Tesla 上运行了整整一天,共同为 RoBERTa 提供了坚实的预训练基础。
在另一方面,为了缩短 BERT 及相关模型的计算(训练、预测)时长,合乎逻辑的尝试自然是选择规模较小的网络以获得类似的性能。目前的剪枝、蒸馏与量化方法都能实现这种效果,但也都会在一定程度上降低预测性能。
4.DistilBERT
它对 BERT 的一套蒸馏(近似)版本进行学习,性能可达 BERT 的约 95%,但所使用的参数总量仅为 BERT 的一半。具体来讲,DistilBERT 放弃了其中的标记类型与池化层,因此总层数仅相当于谷歌 BERT 的一半。DistilBER 采用了蒸馏技术,即利用多个较小的神经网络共同构成大型神经网络。其中的原理在于,如果要训练一套大型神经网络,不妨先利用小型神经网络预估其完整的输出分布。这种方式有点类似于后验近似。正因为存在这样的相似性,DistilBERT 自然也用到了贝叶斯统计中用于后验近似的关键优化函数之一——Kulback Leiber 散度。
到底该用哪种方法?
如果你希望获得更快的推理速度,并能够接受在预测精度方面的一点点妥协,那么 DistilBERT 应该是最合适的选项。但是,如果你高度关注预测性能,那么 Facebook 的 RoBERTa 才是理想方案。
从理论角度看,XLNet 基于排序的训练方法应该能够更好地处理依赖关系,并有望在长期运行中带来更好的性能表现。
然而谷歌 BERT 本身已经拥有相当强大的基准性能,因此如果你没有特别的需求,那么继续使用原始 BERT 模型也是个好主意。
总结
可以看到,大多数性能提升方式都专注于增加数据量、计算能力或者训练过程。虽然这些方法确有价值,但往往要求我们在计算与预测性能之间做出权衡。目前,我们真正需要探索的,显然是如何利用更少的数据与计算资源,帮助模型实现性能提升。

公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结
该免费文章来自《极客视点》,如需阅读全部文章,
请先领取课程
请先领取课程
免费领取
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论