
金融巨头Capital One的无服务器实践
极客时间编辑部
讲述:丁婵大小:7.69M时长:05:36
你好,欢迎收听极客视点。
目前,Apache Spark 是处理大规模批处理和流数据的最快开源引擎之一,然而,金融巨头 Capital One 在运行 Apache Spark 多年后,因为 Apache Spark 越来越高的操作要求和维护成本,感到痛苦。为了找到一个更简单、维护少且高度可伸缩的模式, Capital One 围绕 Apache Spark 设计了一个无服务器流解决方案。Capital One 的软件工程总监维杰·班塔努尔(Vijay Bantanur)和高级软件工程师马哈尔希·贾(Maharshi Jha)发文介绍了他们的实践,InfoQ 中文站对其进行了编译,以下为班塔努尔和贾的叙述。
我们的无服务器流架构是基于事件驱动的微服务架构建模的,其中每个微服务使用消息总线彼此连接。
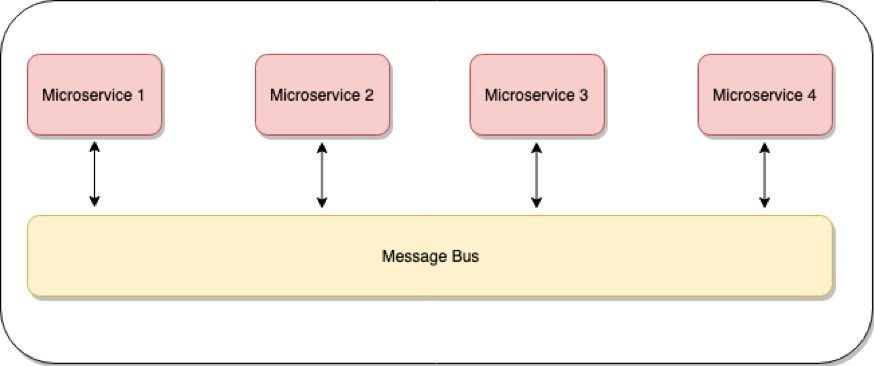
本质上,事件驱动的架构提供了我们需要的流解决方案的所有功能。基于云服务商提供的托管服务实现事件驱动架构,就可以构建无服务器的流解决方案。
对于上述模式,如果将托管服务如 AWS Lambda 作为微服务,AWS Kinesis 作为消息总线,就可以使用无服务器技术栈实现事件驱动的架构。
我们将整个架构分为三层——源、接收(Sink )和处理。
源:在这一层中,微服务只负责从源获取数据。可以将其视为事件进入流应用程序的入口。例如:从 Kafka 集群读取事件。
处理:该层负责处理从源层获得的事件。你还可以将其视为一个能拥有具体应用程序逻辑的层。例如:过滤事件或调用 API 来针对事件做出决策。你可以有一个或多个处理层来映射、缩减或增加你的消息。
接收:这是应用程序的最后一层,在这里对事件进行最后操作。例如:将事件存储到数据存储中,或者通过 API 调用触发其他进程。
下面是从消息驱动架构到 AWS 服务的映射。
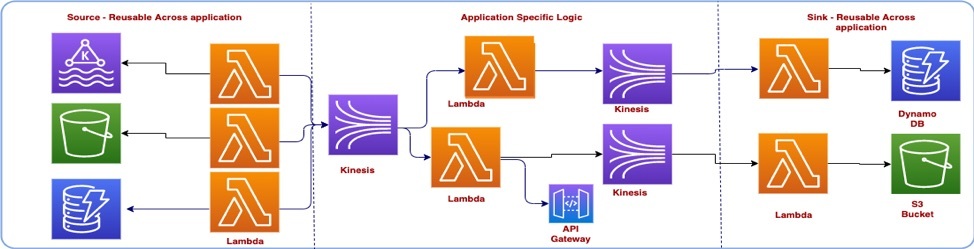
你可能会觉得有很多重复动作,特别是从 Lambda 到从 Kinesis 写 / 读的动作。不过你可以发挥创造力,针对重复的功能构建某种类型的库。
在 Capital One,我们构建了内部 SDK 来抽象重复任务。SDK 有以下特点:
从消息总线读写事件;
异常处理和重试 (阻塞和非阻塞);
秘密管理;
监控;
日志记录;
消息去重;
你可能在想,任何无服务器流解决方案都需要解决伸缩、节流、重用、容错和监控等问题。这是如何实现的呢?
伸缩
这种架构模式与天生可伸缩的云和服务相结合,让这一切成为了可能。
该模式使用 Lambdas 实现微服务,并通过 Kinesis 进行连接。我们只需要扩展具有高 TPS 的 Lambdas,随着消息被过滤掉,相应地调整规模配置。
按照设计,无服务器函数是可自动伸缩的。例如:如果你使用 Lambdas 和 Kinesis,你可以扩展 Kinesis,如果你的消息吞吐量从 2MB/ 秒增加到 4MB/ 秒,这也将扩展与 Kinesis 相关的 Lambda 函数。
限流
如果你的输入请求速率远高于下游所能支持的速率,则需要保存你的请求。在这里,消息总线持久化特性能帮助你,因为你只能选择一次可以处理的消息数量,并保存其他消息。
重用
如果可以构建 source 微服务和 sink 微服务,让它们不具有任何业务功能,并且是基于配置的,那么就可以供多个团队使用它们来消费事件。
例如:如果你能构建源函数,消费来自 Kafka 的事件,这些事件可以对主题名称、代理地址等进行配置,那么任何团队都可以根据需要使用该函数并将其部署到他们的栈中,而无需更改任何代码。
这些可以帮助你实现代码级的重用,另一种重用是流本身的重用。如果你为自己架构选择的消息总线是基于发布 / 订阅的总线,那么就可以有多个订阅者来访问相同事件。例如:你可以将事件 fan out 到两个微服务,而无需单独编写额外代码。
容错
如果你的后端服务出现错误,你可以将所有 / 失败的消息保存到消息总线中,然后重试,直到后端调用开始成功。
监控
作为 SDK 的一部分,记录元数据有效负载能帮助你实现跨不同功能的日志一致性。你还可以构建一个可重用的函数,该函数能将你的日志转发到首选的监控解决方案。
上述就是我们围绕 Apache Spark 设计的无服务器流解决方案。Spark 不是“银弹”,在 Capital One,我们使用多种多样的大数据工程工具,根据具体需要来选择使用哪款工具。
以上就是 Capital One 的无服务器实践,希望能给你带来参考价值。

公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结
该免费文章来自《极客视点》,如需阅读全部文章,
请先领取课程
请先领取课程
免费领取
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论