
第45期 | 深入浅出数据库索引
池建强
讲述:池建强大小:15.02M时长:16:24
你好,这里是卖桃者说。今天是周五,给大家推荐一篇极客时间的付费文章,今天这篇出自丁奇的《MySQL 实战 45 讲》,内容是关于数据库索引的。MySQL 和数据库索引都是最常用到的技术,但是很多人用不好,希望这篇文章能够帮到你。下面是全文。
提到数据库索引,我想你并不陌生,在日常工作中会经常接触到。比如某一个 SQL 查询比较慢,分析完原因之后,你可能就会说“给某个字段加个索引吧”之类的解决方案。但到底什么是索引,索引又是如何工作的呢?今天就让我们一起来聊聊这个话题吧。
数据库索引的内容比较多,我分成了上下两篇文章。索引是数据库系统里面最重要的概念之一,所以我希望你能够耐心看完。在后面的实战文章中,我也会经常引用这两篇文章中提到的知识点,加深你对数据库索引的理解。
一句话简单来说,索引的出现其实就是为了提高数据查询的效率,就像书的目录一样。一本 500 页的书,如果你想快速找到其中的某一个知识点,在不借助目录的情况下,那我估计你可得找一会儿。同样,对于数据库的表而言,索引其实就是它的“目录”。
索引的常见模型
索引的出现是为了提高查询效率,但是实现索引的方式却有很多种,所以这里也就引入了索引模型的概念。可以用于提高读写效率的数据结构很多,这里我先给你介绍三种常见、也比较简单的数据结构,它们分别是哈希表、有序数组和搜索树。
下面我主要从使用的角度,为你简单分析一下这三种模型的区别。
哈希表是一种以键 - 值(key-value)存储数据的结构,我们只要输入待查找的值即 key,就可以找到其对应的值即 Value。哈希的思路很简单,把值放在数组里,用一个哈希函数把 key 换算成一个确定的位置,然后把 value 放在数组的这个位置。
不可避免地,多个 key 值经过哈希函数的换算,会出现同一个值的情况。处理这种情况的一种方法是,拉出一个链表。
假设,你现在维护着一个身份证信息和姓名的表,需要根据身份证号查找对应的名字,这时对应的哈希索引的示意图如下所示:
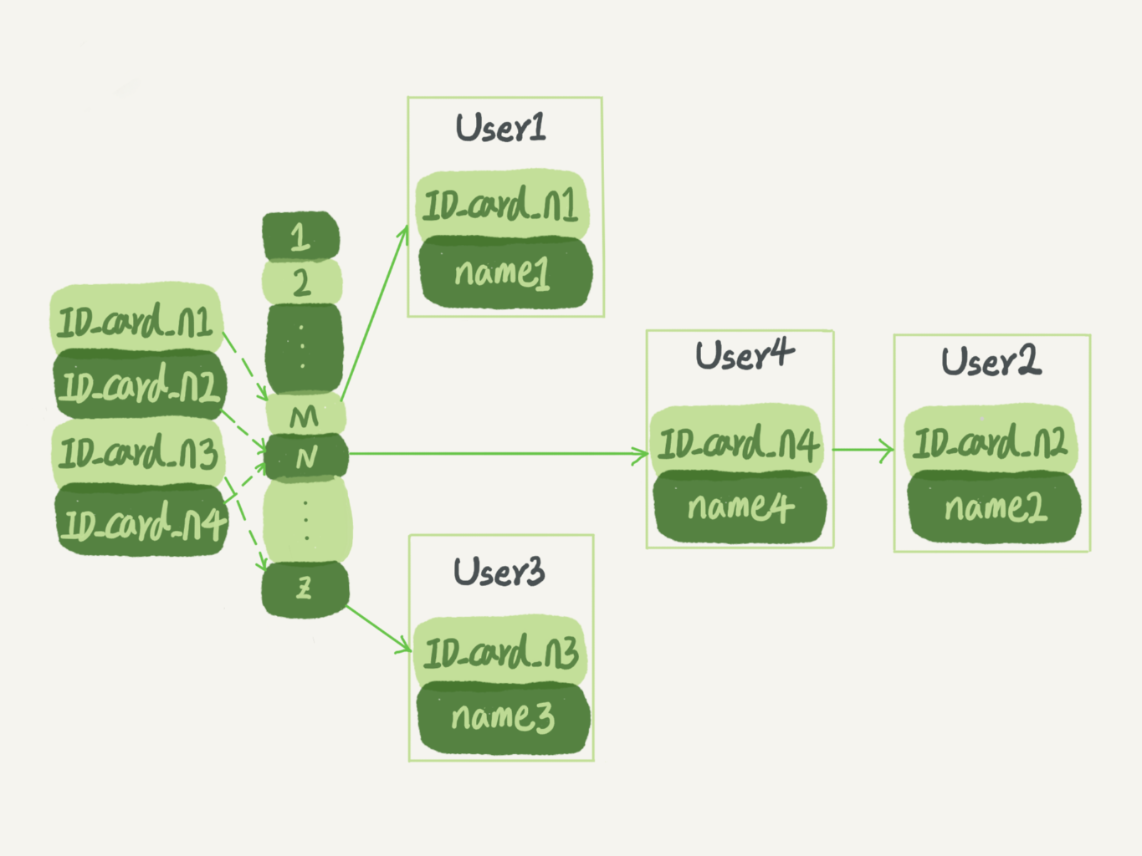
图 1 哈希表示意图
图中,User2 和 User4 根据身份证号算出来的值都是 N,但没关系,后面还跟了一个链表。假设,这时候你要查 ID_card_n2 对应的名字是什么,处理步骤就是:首先,将 ID_card_n2 通过哈希函数算出 N;然后,按顺序遍历,找到 User2。
需要注意的是,图中四个 ID_card_n 的值并不是递增的,这样做的好处是增加新的 User 时速度会很快,只需要往后追加。但缺点是,因为不是有序的,所以哈希索引做区间查询的速度是很慢的。
你可以设想下,如果你现在要找身份证号在[ID_card_X, ID_card_Y]这个区间的所有用户,就必须全部扫描一遍了。
所以,哈希表这种结构适用于只有等值查询的场景,比如 Memcached 及其他一些 NoSQL 引擎。
而有序数组在等值查询和范围查询场景中的性能就都非常优秀。还是上面这个根据身份证号查名字的例子,如果我们使用有序数组来实现的话,示意图如下所示:
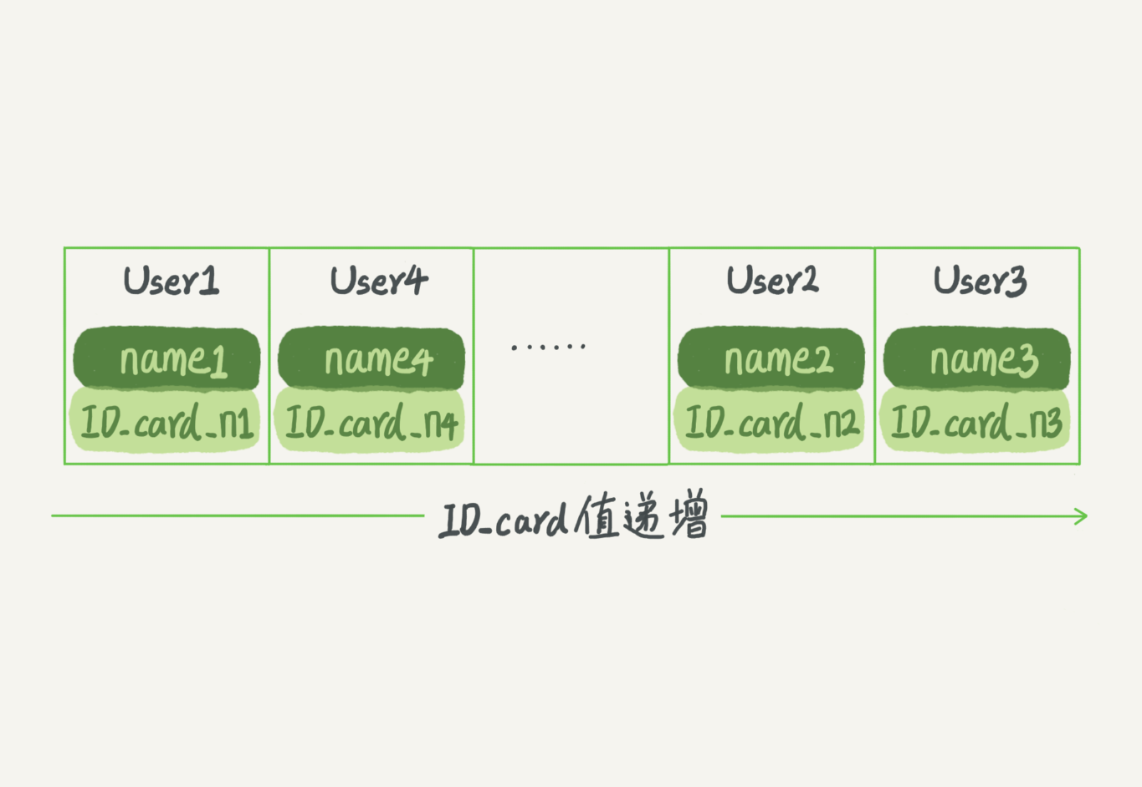
图 2 有序数组示意图
这里我们假设身份证号没有重复,这个数组就是按照身份证号递增的顺序保存的。这时候如果你要查 ID_card_n2 对应的名字,用二分法就可以快速得到,这个时间复杂度是 O(log(N))。
同时很显然,这个索引结构支持范围查询。你要查身份证号在[ID_card_X, ID_card_Y]区间的 User,可以先用二分法找到 ID_card_X(如果不存在 ID_card_X,就找到大于 ID_card_X 的第一个 User),然后向右遍历,直到查到第一个大于 ID_card_Y 的身份证号,退出循环。
如果仅仅看查询效率,有序数组就是最好的数据结构了。但是,在需要更新数据的时候就麻烦了,你往中间插入一个记录就必须得挪动后面所有的记录,成本太高。
所以,有序数组索引只适用于静态存储引擎,比如你要保存的是 2017 年某个城市的所有人口信息,这类不会再修改的数据。
二叉搜索树也是课本里的经典数据结构了。还是上面根据身份证号查名字的例子,如果我们用二叉搜索树来实现的话,示意图如下所示:
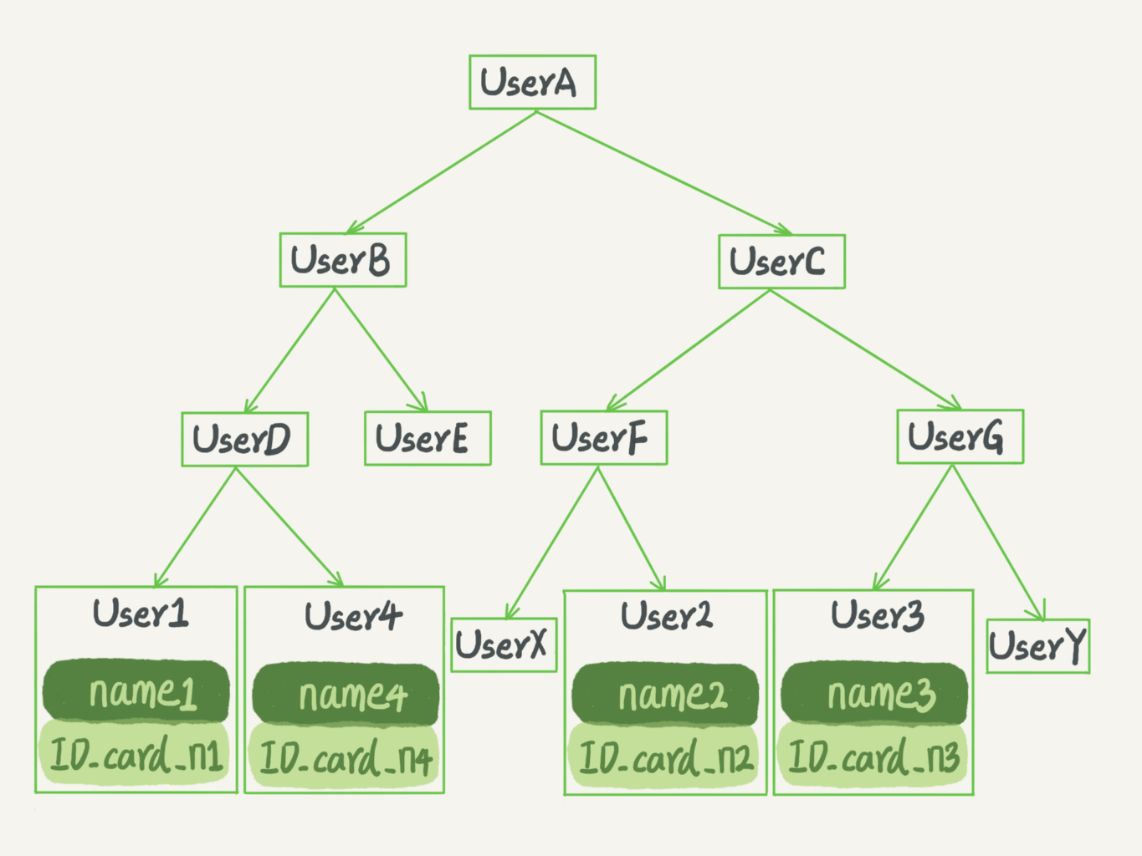
图 3 二叉搜索树示意图
二叉搜索树的特点是:每个节点的左儿子小于父节点,父节点又小于右儿子。这样如果你要查 ID_card_n2 的话,按照图中的搜索顺序就是按照 UserA -> UserC -> UserF -> User2 这个路径得到。这个时间复杂度是 O(log(N))。
当然为了维持 O(log(N)) 的查询复杂度,你就需要保持这棵树是平衡二叉树。为了做这个保证,更新的时间复杂度也是 O(log(N))。
树可以有二叉,也可以有多叉。多叉树就是每个节点有多个儿子,儿子之间的大小保证从左到右递增。二叉树是搜索效率最高的,但是实际上大多数的数据库存储却并不使用二叉树。其原因是,索引不止存在内存中,还要写到磁盘上。
你可以想象一下一棵 100 万节点的平衡二叉树,树高 20。一次查询可能需要访问 20 个数据块。在机械硬盘时代,从磁盘随机读一个数据块需要 10 ms 左右的寻址时间。也就是说,对于一个 100 万行的表,如果使用二叉树来存储,单独访问一个行可能需要 20 个 10 ms 的时间,这个查询可真够慢的。
为了让一个查询尽量少地读磁盘,就必须让查询过程访问尽量少的数据块。那么,我们就不应该使用二叉树,而是要使用“N 叉”树。这里,“N 叉”树中的“N”取决于数据块的大小。
以 InnoDB 的一个整数字段索引为例,这个 N 差不多是 1200。这棵树高是 4 的时候,就可以存 1200 的 3 次方个值,这已经 17 亿了。考虑到树根的数据块总是在内存中的,一个 10 亿行的表上一个整数字段的索引,查找一个值最多只需要访问 3 次磁盘。其实,树的第二层也有很大概率在内存中,那么访问磁盘的平均次数就更少了。
N 叉树由于在读写上的性能优点,以及适配磁盘的访问模式,已经被广泛应用在数据库引擎中了。
不管是哈希还是有序数组,或者 N 叉树,它们都是不断迭代、不断优化的产物或者解决方案。数据库技术发展到今天,跳表、LSM 树等数据结构也被用于引擎设计中,这里我就不再一一展开了。
你心里要有个概念,数据库底层存储的核心就是基于这些数据模型的。每碰到一个新数据库,我们需要先关注它的数据模型,这样才能从理论上分析出这个数据库的适用场景。
截止到这里,我用了半篇文章的篇幅和你介绍了不同的数据结构,以及它们的适用场景,你可能会觉得有些枯燥。但是,我建议你还是要多花一些时间来理解这部分内容,毕竟这是数据库处理数据的核心概念之一,在分析问题的时候会经常用到。当你理解了索引的模型后,就会发现在分析问题的时候会有一个更清晰的视角,体会到引擎设计的精妙之处。
现在,我们一起进入相对偏实战的内容吧。
在 MySQL 中,索引是在存储引擎层实现的,所以并没有统一的索引标准,即不同存储引擎的索引的工作方式并不一样。而即使多个存储引擎支持同一种类型的索引,其底层的实现也可能不同。由于 InnoDB 存储引擎在 MySQL 数据库中使用最为广泛,所以下面我就以 InnoDB 为例,和你分析一下其中的索引模型。
InnoDB 的索引模型
在 InnoDB 中,表都是根据主键顺序以索引的形式存放的,这种存储方式的表称为索引组织表。又因为前面我们提到的,InnoDB 使用了 B+ 树索引模型,所以数据都是存储在 B+ 树中的。
每一个索引在 InnoDB 里面对应一棵 B+ 树。
假设,我们有一个主键列为 ID 的表,表中有字段 k,并且在 k 上有索引。
这个表的建表语句是:
表中 R1~R5 的 (ID,k) 值分别为 (100,1)、(200,2)、(300,3)、(500,5) 和 (600,6),两棵树的示例示意图如下。
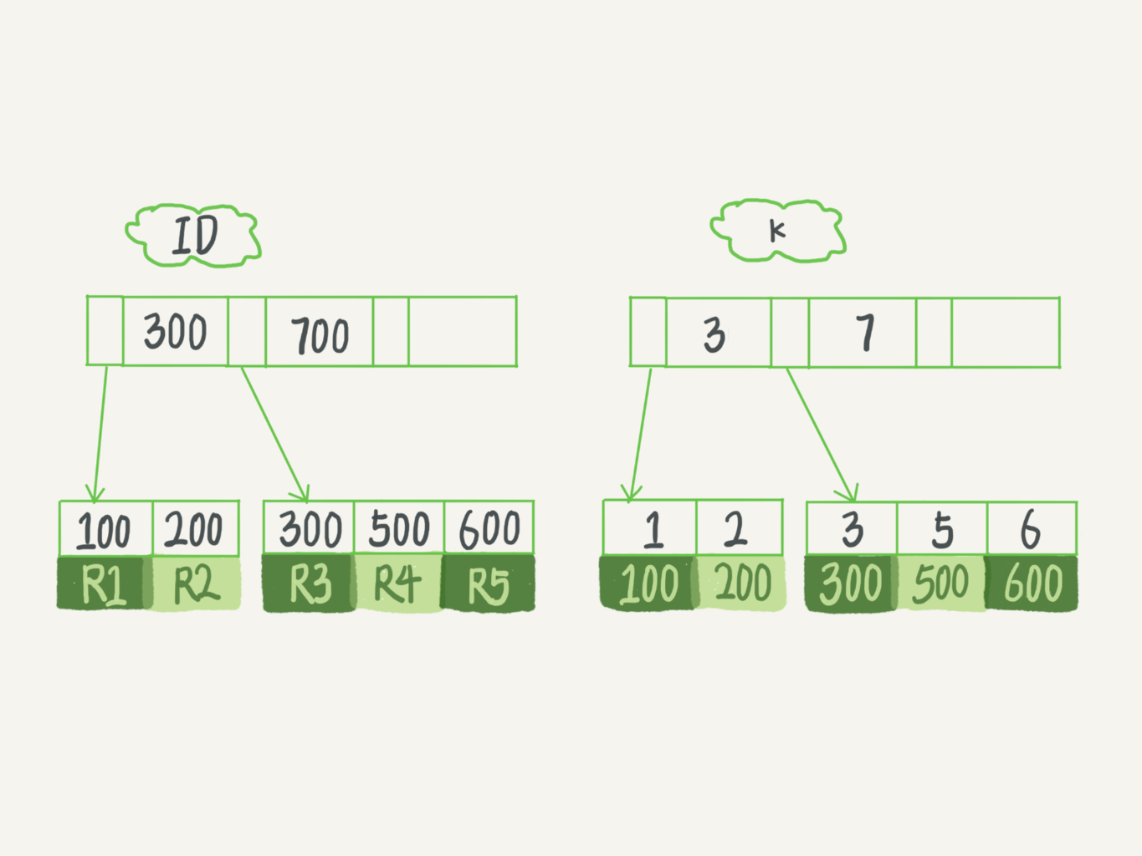
图 4 InnoDB 的索引组织结构
从图中不难看出,根据叶子节点的内容,索引类型分为主键索引和非主键索引。
主键索引的叶子节点存的是整行数据。在 InnoDB 里,主键索引也被称为聚簇索引(clustered index)。
非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引(secondary index)。
根据上面的索引结构说明,我们来讨论一个问题:基于主键索引和普通索引的查询有什么区别?
如果语句是 select * from T where ID=500,即主键查询方式,则只需要搜索 ID 这棵 B+ 树;
如果语句是 select * from T where k=5,即普通索引查询方式,则需要先搜索 k 索引树,得到 ID 的值为 500,再到 ID 索引树搜索一次。这个过程称为回表。
也就是说,基于非主键索引的查询需要多扫描一棵索引树。因此,我们在应用中应该尽量使用主键查询。
索引维护
B+ 树为了维护索引有序性,在插入新值的时候需要做必要的维护。以上面这个图为例,如果插入新的行 ID 值为 700,则只需要在 R5 的记录后面插入一个新记录。如果新插入的 ID 值为 400,就相对麻烦了,需要逻辑上挪动后面的数据,空出位置。
而更糟的情况是,如果 R5 所在的数据页已经满了,根据 B+ 树的算法,这时候需要申请一个新的数据页,然后挪动部分数据过去。这个过程称为页分裂。在这种情况下,性能自然会受影响。
除了性能外,页分裂操作还影响数据页的利用率。原本放在一个页的数据,现在分到两个页中,整体空间利用率降低大约 50%。
当然有分裂就有合并。当相邻两个页由于删除了数据,利用率很低之后,会将数据页做合并。合并的过程,可以认为是分裂过程的逆过程。
基于上面的索引维护过程说明,我们来讨论一个案例:
你可能在一些建表规范里面见到过类似的描述,要求建表语句里一定要有自增主键。当然事无绝对,我们来分析一下哪些场景下应该使用自增主键,而哪些场景下不应该。
自增主键是指自增列上定义的主键,在建表语句中一般是这么定义的: NOT NULL PRIMARY KEY AUTO_INCREMENT。
插入新记录的时候可以不指定 ID 的值,系统会获取当前 ID 最大值加 1 作为下一条记录的 ID 值。
也就是说,自增主键的插入数据模式,正符合了我们前面提到的递增插入的场景。每次插入一条新记录,都是追加操作,都不涉及到挪动其他记录,也不会触发叶子节点的分裂。
而有业务逻辑的字段做主键,则往往不容易保证有序插入,这样写数据成本相对较高。
除了考虑性能外,我们还可以从存储空间的角度来看。假设你的表中确实有一个唯一字段,比如字符串类型的身份证号,那应该用身份证号做主键,还是用自增字段做主键呢?
由于每个非主键索引的叶子节点上都是主键的值。如果用身份证号做主键,那么每个二级索引的叶子节点占用约 20 个字节,而如果用整型做主键,则只要 4 个字节,如果是长整型(bigint)则是 8 个字节。
显然,主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小。
所以,从性能和存储空间方面考量,自增主键往往是更合理的选择。
有没有什么场景适合用业务字段直接做主键的呢?还是有的。比如,有些业务的场景需求是这样的:
只有一个索引;
该索引必须是唯一索引。
你一定看出来了,这就是典型的 KV 场景。
由于没有其他索引,所以也就不用考虑其他索引的叶子节点大小的问题。
这时候我们就要优先考虑上一段提到的“尽量使用主键查询”原则,直接将这个索引设置为主键,可以避免每次查询需要搜索两棵树。
小结
今天,我跟你分析了数据库引擎可用的数据结构,介绍了 InnoDB 采用的 B+ 树结构,以及为什么 InnoDB 要这么选择。B+ 树能够很好地配合磁盘的读写特性,减少单次查询的磁盘访问次数。
由于 InnoDB 是索引组织表,一般情况下我会建议你创建一个自增主键,这样非主键索引占用的空间最小。但事无绝对,我也跟你讨论了使用业务逻辑字段做主键的应用场景。
最后,我给你留下一个问题吧。对于上面例子中的 InnoDB 表 T,如果你要重建索引 k,你的两个 SQL 语句可以这么写:
如果你要重建主键索引,也可以这么写:
我的问题是,对于上面这两个重建索引的作法,说出你的理解。如果有不合适的,为什么,更好的方法是什么?
你可以把你的思考和观点写在留言区里,我会在下一篇文章的末尾给出我的参考答案。感谢你的收听,也欢迎你把这篇文章分享给更多的朋友一起阅读。
内容听完了,相信你对数据库索引有了更深入的理解。欢迎在留言区发表你的看法。每一次参与和讨论,都是一个小小的进步。
目前已经有 34000 人在学习这个《MySQL 实战 45 讲》,如果你也感兴趣,可以在发现页搜索 MySQL,就可以找到这个专栏并订阅学习了。
卖桃者说,下周见。
(编辑:成敏)
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结
该免费文章来自《卖桃者说》,如需阅读全部文章,
请先领取课程
请先领取课程
免费领取
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(12)
- 最新
- 精选
 熊斌早上到公司后试了一下文章最后留的作业,没看出个所以然。平时数据库方面的工作都是dba负责,我比较欠缺深入一些的数据库知识。得多补补了
熊斌早上到公司后试了一下文章最后留的作业,没看出个所以然。平时数据库方面的工作都是dba负责,我比较欠缺深入一些的数据库知识。得多补补了池建强回复: 可以订阅这个专栏啊
 X5N池老师,我在极客时间上买了SQL和MySQL的两个专栏(当然都只是刚刚开始学),但发现他们在“数据库设计,表设计”方面似乎都讲得不多。专栏留言区里有人提到了“三范式”之类的概念,老师好像也没打算讲,但我还是想系统学习一下这方面的知识。您有这方面的书籍,或者资料推荐吗?又或者是极客时间上本来就有这方面的内容,只是我没发现?
X5N池老师,我在极客时间上买了SQL和MySQL的两个专栏(当然都只是刚刚开始学),但发现他们在“数据库设计,表设计”方面似乎都讲得不多。专栏留言区里有人提到了“三范式”之类的概念,老师好像也没打算讲,但我还是想系统学习一下这方面的知识。您有这方面的书籍,或者资料推荐吗?又或者是极客时间上本来就有这方面的内容,只是我没发现?池建强回复: 我们看看做个加餐,或者做个每日一课小视频吧
 Halohoop👍🏿👍👍🏻👩🦰👨🦰👩🦳👨🦳👮🏼♂️👷🏼♀️👷♂️🕵️🏼♀️👳♂️ 围观池大偷懒现场~😬😬119
Halohoop👍🏿👍👍🏻👩🦰👨🦰👩🦳👨🦳👮🏼♂️👷🏼♀️👷♂️🕵️🏼♀️👳♂️ 围观池大偷懒现场~😬😬119
 顾仲贤自上次提升技术影响力留言后,能不能再来推广下自己的数据库内核杂谈博客。写过一期索引,并不是针对mysql。而是从各种索引原理比较出发:https://www.jianshu.com/p/6f65dac35188 欢迎拍砖和转载。2
顾仲贤自上次提升技术影响力留言后,能不能再来推广下自己的数据库内核杂谈博客。写过一期索引,并不是针对mysql。而是从各种索引原理比较出发:https://www.jianshu.com/p/6f65dac35188 欢迎拍砖和转载。2 allean大型偷懒现场,当场抓获😁12
allean大型偷懒现场,当场抓获😁12 吃草🐴~目前,我对 MySQL 索引的理解也就仅仅停留在会加索引这个水平了。老师讲得非常细致,学习了。 灵魂拷问:数据库都不懂,以后怎么叱咤大数据界?1
吃草🐴~目前,我对 MySQL 索引的理解也就仅仅停留在会加索引这个水平了。老师讲得非常细致,学习了。 灵魂拷问:数据库都不懂,以后怎么叱咤大数据界?1 哈德韦哈希表在遇到碰撞时,还是要用链表,也就是说仍然需要在链表中把 key 保存着,用来比对。那么将 key 哈希的意义是什么?如果写一个哈希函数 key => key 岂不更好,这样可以保证没有碰撞……
哈德韦哈希表在遇到碰撞时,还是要用链表,也就是说仍然需要在链表中把 key 保存着,用来比对。那么将 key 哈希的意义是什么?如果写一个哈希函数 key => key 岂不更好,这样可以保证没有碰撞…… 小斧主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小。
小斧主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小。 上善若水唯一识别码越小越好,分段查询
上善若水唯一识别码越小越好,分段查询- 上善若水存储 方式决定索引
收起评论