

27 | 决策树:信息增益、增益比率和基尼指数的运用

该思维导图由 AI 生成,仅供参考
如何通过信息熵挑选合适的问题?

 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

决策树算法及其应用 本文介绍了决策树算法的基本概念和几种常见的决策树算法,包括ID3、C4.5和CART。文章首先通过问卷调查案例引出了信息熵、信息增益和基尼指数等信息论概念在决策树中的运用,重点介绍了信息增益、增益比率和基尼指数的应用。作者详细解释了这些概念的计算方法,并通过案例分析展示了决策树算法的实际应用。此外,文章还对不同决策树算法的特点进行了比较,指出它们在特征选择和数据划分上的异同。特别是介绍了信息增益率的应用,以及CART算法采用基尼指数进行特征选择和数据划分的方式。最后,文章指出了决策树算法的优势和不足,以及对于过拟合问题的优化方案。总的来说,本文通过具体案例和技术原理,深入浅出地介绍了决策树算法的运用和相关概念,对于读者快速了解决策树算法具有一定的参考价值。
《程序员的数学基础课》,新⼈⾸单¥68

全部留言(22)
- 最新
- 精选
 Peng开始看不懂了,我再多看几遍试试。
Peng开始看不懂了,我再多看几遍试试。作者回复: 可以逐个理解,每次理解一点都是进步👍
2019-03-05213 lifes a Struggle知道了,老师的案例中个体都是一个单独的分类,所有在原始集合中可以采用-n*(Pi*log(2,Pi))的形式进行信息熵的计算。如果存在分类的数据不均匀,通过各个分类的信息熵求和即可。
lifes a Struggle知道了,老师的案例中个体都是一个单独的分类,所有在原始集合中可以采用-n*(Pi*log(2,Pi))的形式进行信息熵的计算。如果存在分类的数据不均匀,通过各个分类的信息熵求和即可。作者回复: 是的👍
2019-08-075 总统老唐既然每次都是分解成左右两个子树,为什么CART算法公式中的m不直接写成2
总统老唐既然每次都是分解成左右两个子树,为什么CART算法公式中的m不直接写成2作者回复: 这里主要是通用性,对于CART算法确实可以将m简写为2,对于其他使用基尼指数的算法仍然保持m
2019-12-253 张九州计算整个数据集基尼指数,pj是什么 如何计算?
张九州计算整个数据集基尼指数,pj是什么 如何计算?作者回复: pj表示第j组元素出现的概率,这里用在某个划分的组之中,第j组元素的数量除以这个划分的元素数量来计算
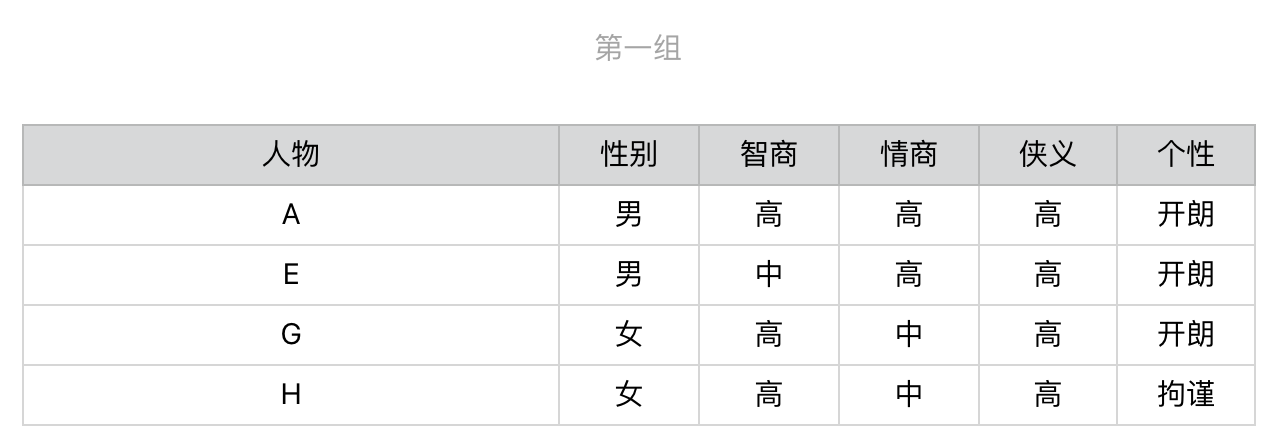
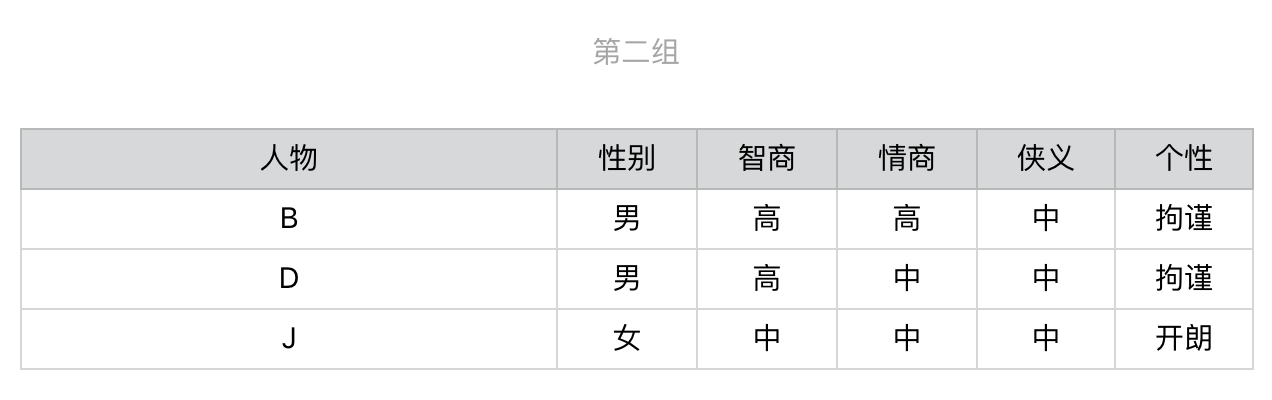
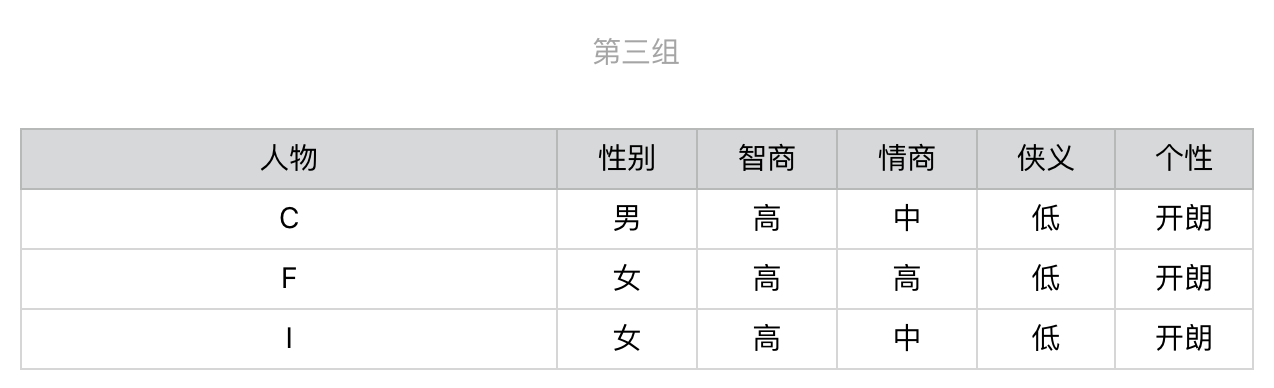
2019-09-083 建强根据信息增益划分的原理,简单写了一个python程序计算了一下问题期望数,程序输出结果如下: 选择信息增益小的问题对人物分类,问题数的期望值=3.7 选择信息增益大的问题对人物分类,问题数的期望值=2.8 程序代码如下: import pandas as pd # 初始化10个武侠人物的属性 p = { '性别':['男','男','男','男','男','女','女','女','女','女'] ,'智商':['高','高','高','高','中','高','高','高','高','中'] ,'情商':['高','高','中','中','高','高','中','中','中','中'] ,'侠义':['高','中','低','中','高','低','高','高','低','中'] ,'个性':['开朗','拘谨','开朗','拘谨','开朗','开朗','开朗','拘谨','开朗','开朗']} name = ['A','B','C','D','E','F','G','H','I','J'] knight = pd.DataFrame(data=p,index=name) # 定义问题类型及增益大小 problem_type = {'性别':1,'智商':0.72,'情商':0.97,'侠义':1.58,'个性':0.88} # 计算测试问题的期望值 def get_exp_problems(knight, problem_type): #BEGIN result = {} sub_knight = [(knight,0)] temp_sub_knight = [] for pt in problem_type: #用某一个问题类型对每一组侠客进行划分 for sub in sub_knight: temp_sub = sub[0].groupby(by = [pt]) #该问题没有将该组侠客进行划分,放入中间结果,继续下一组划分 if len(temp_sub) <= 1: temp_sub_knight.append((sub[0],sub[1])) continue # 对划分后的结果进行处理 for label, member in temp_sub: list_member = list(member.index) if len(list_member) == 1: result[list_member[0]] = sub[1] + 1 else: temp_sub_knight.append((member, sub[1]+1)) sub_knight.clear() sub_knight.extend(temp_sub_knight) temp_sub_knight.clear() # 计算问题数的期望值 exp = 0 for k in result: exp += result[k]/len(name) return exp #END def main(): problem = dict(sorted(problem_type.items(), key=lambda x: x[1], reverse=False)) print('选择信息增益小的问题对人物分类,问题数的期望值={}'.format(round(get_exp_problems(knight, problem),2))) problem = dict(sorted(problem_type.items(), key=lambda x: x[1], reverse=True)) print('选择信息增益大的问题对人物分类,问题数的期望值={}'.format(round(get_exp_problems(knight, problem),2))) if __name__ == '__main__': main()
建强根据信息增益划分的原理,简单写了一个python程序计算了一下问题期望数,程序输出结果如下: 选择信息增益小的问题对人物分类,问题数的期望值=3.7 选择信息增益大的问题对人物分类,问题数的期望值=2.8 程序代码如下: import pandas as pd # 初始化10个武侠人物的属性 p = { '性别':['男','男','男','男','男','女','女','女','女','女'] ,'智商':['高','高','高','高','中','高','高','高','高','中'] ,'情商':['高','高','中','中','高','高','中','中','中','中'] ,'侠义':['高','中','低','中','高','低','高','高','低','中'] ,'个性':['开朗','拘谨','开朗','拘谨','开朗','开朗','开朗','拘谨','开朗','开朗']} name = ['A','B','C','D','E','F','G','H','I','J'] knight = pd.DataFrame(data=p,index=name) # 定义问题类型及增益大小 problem_type = {'性别':1,'智商':0.72,'情商':0.97,'侠义':1.58,'个性':0.88} # 计算测试问题的期望值 def get_exp_problems(knight, problem_type): #BEGIN result = {} sub_knight = [(knight,0)] temp_sub_knight = [] for pt in problem_type: #用某一个问题类型对每一组侠客进行划分 for sub in sub_knight: temp_sub = sub[0].groupby(by = [pt]) #该问题没有将该组侠客进行划分,放入中间结果,继续下一组划分 if len(temp_sub) <= 1: temp_sub_knight.append((sub[0],sub[1])) continue # 对划分后的结果进行处理 for label, member in temp_sub: list_member = list(member.index) if len(list_member) == 1: result[list_member[0]] = sub[1] + 1 else: temp_sub_knight.append((member, sub[1]+1)) sub_knight.clear() sub_knight.extend(temp_sub_knight) temp_sub_knight.clear() # 计算问题数的期望值 exp = 0 for k in result: exp += result[k]/len(name) return exp #END def main(): problem = dict(sorted(problem_type.items(), key=lambda x: x[1], reverse=False)) print('选择信息增益小的问题对人物分类,问题数的期望值={}'.format(round(get_exp_problems(knight, problem),2))) problem = dict(sorted(problem_type.items(), key=lambda x: x[1], reverse=True)) print('选择信息增益大的问题对人物分类,问题数的期望值={}'.format(round(get_exp_problems(knight, problem),2))) if __name__ == '__main__': main()作者回复: 很好的实现
2020-06-212 qinggeouye某个特征 T 取值越多,数据集 P 划分时分组越多,划分后的「信息熵」越小,「信息增益」越大。「分裂信息」是为了解决某个特征 T 取值过多,造成机器学习过拟合,而引入的一种惩罚项,惩罚取值多的特征。 老师,「基尼指数」没怎么看明白,第一个式子中「n 为集合 P 中所包含的不同分组或分类的数量」该怎么理解?求和符号后面的 pi 是什么含义?谢谢~
qinggeouye某个特征 T 取值越多,数据集 P 划分时分组越多,划分后的「信息熵」越小,「信息增益」越大。「分裂信息」是为了解决某个特征 T 取值过多,造成机器学习过拟合,而引入的一种惩罚项,惩罚取值多的特征。 老师,「基尼指数」没怎么看明白,第一个式子中「n 为集合 P 中所包含的不同分组或分类的数量」该怎么理解?求和符号后面的 pi 是什么含义?谢谢~作者回复: 因为决策树是一种分类算法,我们有训练样本告诉我们每个数据样本属于何种分类,所以这里的分类、分组都是根据训练样本中的分类标签。
2019-03-1022 Thinking建议老师每堂课后能配多几个具有代表性的,针对性的练习题辅助理解概念和公式。
Thinking建议老师每堂课后能配多几个具有代表性的,针对性的练习题辅助理解概念和公式。作者回复: 好的,后面我会考虑多从公式的角度出发
2019-02-152 灰太狼老师,基尼系数公式里的pi是指分组i在集合P中的概率吗?
灰太狼老师,基尼系数公式里的pi是指分组i在集合P中的概率吗?作者回复: 是的👍
2020-03-2841 💢 星星💢老师随机森林有没有好的文章推荐,另外老师有没有公众号,或者其他方式可以白嫖看您的文章呢,当然也期待老师出新的专栏,虽然这个专栏对于我来说已经是新的挑战。但是非常喜欢读老师的文章。
💢 星星💢老师随机森林有没有好的文章推荐,另外老师有没有公众号,或者其他方式可以白嫖看您的文章呢,当然也期待老师出新的专栏,虽然这个专栏对于我来说已经是新的挑战。但是非常喜欢读老师的文章。作者回复: 你好,感谢支持,我暂时还没有时间在其他地方发表博文。如果有好的想法写作,当然首选极客时间专栏啦😆。正在和编辑筹划下一个专栏,期待与大家再次交流
2019-11-111 Joe老师,请问有没有相关代码实现的方式,能否给出参考链接。
Joe老师,请问有没有相关代码实现的方式,能否给出参考链接。作者回复: 你是指计算信息熵、信息增益和基尼指数?可以使用现成的机器学习包计算,如果希望自己计算也不难,遵循专栏中的公式就可以了。后面我有时间整理一下代码。
2019-02-2121

