

24 | 语言模型:如何使用链式法则和马尔科夫假设简化概率模型?

该思维导图由 AI 生成,仅供参考
语言模型是什么?
1. 链式法则
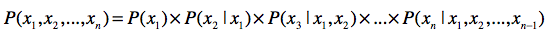
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文介绍了基于概率模型的语言处理技术及其在信息检索和中文分词领域的应用。文章首先讨论了概率模型在计算复杂度方面的重要性,引入了链式法则和马尔科夫假设的概念。随后详细介绍了语言模型如何计算句子出现的概率,以及马尔科夫假设和多元文法模型在简化计算复杂度和解决0概率问题方面的作用。此外,文章还探讨了语言模型在信息检索中计算文档与查询相关性的应用,以及在中文分词中解决歧义的作用。最后,文章提出了对语言模型的改进思路,将分类信息纳入模型考量范围。总的来说,本文深入浅出地介绍了概率模型在语言处理中的重要性和应用价值,为读者提供了对该领域的全面了解。
《程序员的数学基础课》,新⼈⾸单¥68

全部留言(32)
- 最新
- 精选
 枫林火山黄老师,一直没想明白多元文法里的前面N个词的是否有顺序。例如: 大家好, 家大好 。 这2种情况都符合三元文法中的P(xn|xn-2,xn-1)的统计条件吗? 推广下 P(x1,x2,x3,x4….xn) 等于 P(xn,xn-1,xn-2,….,x4,x3,x2,x1) 吗? 百度-联合概率是指在多元的概率分布中多个随机变量分别满足各自条件的概率。我的理解联合概率的条件是可以交换顺序的。 所以从联合概率定义的角度理解是等于的, 但是从语法模型的角度理解,语法是有顺序的,那用联合概率表示对不对。 本节讲的语法模型是把一句话当作有序队列去对待的还是无序集合对待的? 我听您的讲解是感觉是有序的,但是我理解公式从联合概率定义又感觉公式是在说一个无序的一组条件。 没法把这两者联系起来。 以下两组公式,我只能知道当使用一元文法时,二者时相等的。二元以上有点懵!老师能不能讲解下 P(x1,x2,x3,x4….xn) = P(x1)*P(x2|x1)*P(x3|x1,x2)*…….*P(xn|x1,x2,x3,x4….xn-1) P(xn,xn-1,xn-2,….,x4,x3,x2,x1) = P(xn)*P(xn-1|xn)*P(xn-2|xn,xn-1)*…….*P(x1|xn,xn-1,……,x2)
枫林火山黄老师,一直没想明白多元文法里的前面N个词的是否有顺序。例如: 大家好, 家大好 。 这2种情况都符合三元文法中的P(xn|xn-2,xn-1)的统计条件吗? 推广下 P(x1,x2,x3,x4….xn) 等于 P(xn,xn-1,xn-2,….,x4,x3,x2,x1) 吗? 百度-联合概率是指在多元的概率分布中多个随机变量分别满足各自条件的概率。我的理解联合概率的条件是可以交换顺序的。 所以从联合概率定义的角度理解是等于的, 但是从语法模型的角度理解,语法是有顺序的,那用联合概率表示对不对。 本节讲的语法模型是把一句话当作有序队列去对待的还是无序集合对待的? 我听您的讲解是感觉是有序的,但是我理解公式从联合概率定义又感觉公式是在说一个无序的一组条件。 没法把这两者联系起来。 以下两组公式,我只能知道当使用一元文法时,二者时相等的。二元以上有点懵!老师能不能讲解下 P(x1,x2,x3,x4….xn) = P(x1)*P(x2|x1)*P(x3|x1,x2)*…….*P(xn|x1,x2,x3,x4….xn-1) P(xn,xn-1,xn-2,….,x4,x3,x2,x1) = P(xn)*P(xn-1|xn)*P(xn-2|xn,xn-1)*…….*P(x1|xn,xn-1,……,x2)作者回复: 联合概率是不考虑顺序的,而N元文法一般都是要考虑一点顺序的。所谓“一点”就如你所提到的,这是一个条件概率P(xn|xn-2,xn-1),顺序是指xn-2和xn-1都是在xn的前面出现,但是我们并不关心xn-2和xn-1之间的顺序。而另一方面,我们之前已经考虑了P(xn-1|xn-2, xn-3),你可以认为xn-1和xn-2之间的关系已经在这一步考虑了。 至于你说的最后一点,P(x1,x2,x3,x4….xn) 和P(xn,xn-1,xn-2,….,x4,x3,x2,x1)理论上应该是一致的。但是n稍微大点,我们就无法直接求了,所以要使用马尔科夫假设进行近似。而马尔科夫假在一定程度上考虑了文本出现的顺序,所以不同顺序的x1,x2...xn就会影响近似的结果,所以有P(x1,x2,x3,x4….xn)约等于近似结果a,P(xn,xn-1,xn-2,….,x4,x3,x2,x1)约等于近似结果b,a和b都是同一个理论值的近似,但是由于马尔科夫假设的原因,两个近似值不一致。
2019-04-11322 文本分类器,对给定文本进行判断。用特征词代表该文本。应该和上篇文章分类的计算有类似之处。计算每个特征词出现在该类文章的概率。然后根据权重分类?或者根据每个词的词频。 (我也很迷糊)那中文中有时词的顺序错乱也能表达一个意思。 比如,密码是123和321是密码;蹦迪坟头和坟头蹦迪。 比如(相互和互相;代替和替代)比 如,纳税可以是一个专有名词,也可以是人名,姓纳名税。还有那遇到多音字咋办?
文本分类器,对给定文本进行判断。用特征词代表该文本。应该和上篇文章分类的计算有类似之处。计算每个特征词出现在该类文章的概率。然后根据权重分类?或者根据每个词的词频。 (我也很迷糊)那中文中有时词的顺序错乱也能表达一个意思。 比如,密码是123和321是密码;蹦迪坟头和坟头蹦迪。 比如(相互和互相;代替和替代)比 如,纳税可以是一个专有名词,也可以是人名,姓纳名税。还有那遇到多音字咋办?作者回复: 这个问题很好,确实中文比较特殊,和拉丁文不太一样。 我觉得你的问题是:中文里的歧义或者分词错误,是不是会影响分类? 你说的这几种情况,我简单分为以下几种: 分词:如果我们能知道123或321代表一个字符串,而不是单个的数字,那么就不会切分它们。再例如“相互”也不会切为“相”和“互”。当然中文分词本身不是件容易的事情,我这里提到概率语言模型,如果语料里有相关的信息,那么可以在一定程度上提升分词效果。 同义词:如果我们能正确切分出“相互”和“互相”,那么还需要把它们关联为同义词。基本的做法是使用词典。 语义:“纳税”的问题就更复杂一些,需要计算机理解上下文关系和语义。从统计的角度而言,那还是要看语料里“纳税”这个词哪种情况的概率更高。 所以,自然语言处理,尤其是中文的处理,是件相当复杂也是相当有趣的事情。“词包”模型只是最基本的模型,如果我们想优化它在分类问题上的表现,需要解决好中文分词、消除歧义、同义词/近义词等问题。每个问题都是值得研究,并且可以提升的。如果每个点都能得到优化,那么最终分类的效果也会得到优化。 总结一下,文本分类涉及的面很广,不仅受到分类算法的影响,还受到其他许多自然语言处理的影响。由于这个系列专栏的主题是数学,所以我这讲只能把概率和相关分类算的核心思想体现出来。如果你对自然语言处理有兴趣,我可以在加餐或者其他专栏中和你分享。
2019-02-088 qinggeouye思考题: 首先,利用语言模型进行中文分词,计算句子 S=使用纯净水源浇灌的大米,属于哪种分词结果 W(“使用|纯净|水源|浇灌|的|大米”、“使用|纯净水|源|浇灌|的|大米”)的概率最大? 然后,回到上节的文本分类,再计算 分词结果W 属于哪种分类(“大米”、“纯净水”)的概率比较大?
qinggeouye思考题: 首先,利用语言模型进行中文分词,计算句子 S=使用纯净水源浇灌的大米,属于哪种分词结果 W(“使用|纯净|水源|浇灌|的|大米”、“使用|纯净水|源|浇灌|的|大米”)的概率最大? 然后,回到上节的文本分类,再计算 分词结果W 属于哪种分类(“大米”、“纯净水”)的概率比较大?作者回复: 这是一种方法👌
2019-03-056 唯她命已经求得p(q|d) = p(k1,k2,k3...,kn|d) = p(k1|d) * p(k2|k1,d) * p(k3|k2,k1,d) .... 那么我们怎么求得 p(k2|k1,d) 和 p(k3|k2,k1,d)呢
唯她命已经求得p(q|d) = p(k1,k2,k3...,kn|d) = p(k1|d) * p(k2|k1,d) * p(k3|k2,k1,d) .... 那么我们怎么求得 p(k2|k1,d) 和 p(k3|k2,k1,d)呢作者回复: 在实际项目中,可以通过大量的语料来统计,比如文档d中,在k1后面出现k2的次数,除以k1出现的次数,用来近似P(k2|k1,d)
2019-02-265 OP_未央思考题: 可以增加类别的先验概率,P(w1,w2...wn|C)*P(C);或者已知大米广告的条件下,通过得到的不同分词计算所属类别的概率,选择属于大米概率大的那种分词?
OP_未央思考题: 可以增加类别的先验概率,P(w1,w2...wn|C)*P(C);或者已知大米广告的条件下,通过得到的不同分词计算所属类别的概率,选择属于大米概率大的那种分词?作者回复: 嗯,是的。可以对不同分类构建分类器,或者增加条件概率
2019-04-0424- seleven换句话说:其实我是想问,如何能更好的利用全文或者说全部训练集的语义信息?
作者回复: 如果是词包模型,确实对语义没有太多的理解。可以加入一些基于文法甚至是领域知识的语义分析,不过这个和具体的应用有关系,可能不是语法模型本身能很好解决的。例如,评论中的情感分析(sentiment analysis),我们可以考虑表达情感的词在否定句式中的表达等等。
2019-02-163 - seleven这篇文章和上篇文章中介绍的分类基本都是在假定文章中的词语相互独立的情况下进行的,虽然马尔科夫模型用到前面词的概率,这可以说是结合了部分上下文之间的语义关系,只使用了和前面词的语义关系,对文本分类其实效果已经很好,尤其是在语料充足的情况下可以使用机器学习的方法让分类模型自迭代优化,目前很多机器翻译就是这么干的。但是我想问下老师,针对语料不是很充足的文本集,如何使用全篇文章的语义(不只是前面词的上下文关系)来设计一个文本分类器?
作者回复: 我想你所说的是针对分类问题对吧?那么语料不充足,是指只有少数的标注数据(文章),是吧?如果是这样,一种做法是增大ngram里面的n,因为标注数据不多,增加n不会增加太多的存储空间。另外,也可以使用少量数据训练得到的分类器,对新的数据进行分类,然后获得一些分类结果后,人工再进行复查,把正确的结果再次纳入训练数据。
2019-02-153  建强思考题: 考虑分类信息的分词模式,只要把分词概率计算公式中的文档集合D,改为某一分类的文档集合T,即公式改为:arg maxP(Wi|T),在某个文档类别下,取分词概率最大的那种切分方式,具体计算时,应在同类别下的所有文档中去计算每个分词出现的概率(即分词出现的频度)。
建强思考题: 考虑分类信息的分词模式,只要把分词概率计算公式中的文档集合D,改为某一分类的文档集合T,即公式改为:arg maxP(Wi|T),在某个文档类别下,取分词概率最大的那种切分方式,具体计算时,应在同类别下的所有文档中去计算每个分词出现的概率(即分词出现的频度)。作者回复: 很好的思路
2020-05-302- 唯她命老师你好,p(K2 | k1,d) 指的是K2 | k1 和 d的联合概率 还是指的是 在满足k1和d的条件下,出现k2的概率?
作者回复: 是第二种,在满足k1和d的条件下,出现k2的概率
2019-02-262  A君链式法则将联合概率转成了一系列条件概率相乘,而马尔科夫假设简化了多条件概率的计算复杂度,两者结合,就可以计算一个查询、一条文本在数据集/文档中出现的概率,不仅可以计算查询和文档的匹配度,还可以用于进行中文分词,根据数据集特性来对文本进行分词。
A君链式法则将联合概率转成了一系列条件概率相乘,而马尔科夫假设简化了多条件概率的计算复杂度,两者结合,就可以计算一个查询、一条文本在数据集/文档中出现的概率,不仅可以计算查询和文档的匹配度,还可以用于进行中文分词,根据数据集特性来对文本进行分词。作者回复: 没错👍
2021-01-131

