

60 | 性能设计:数据库扩展
陈皓

该思维导图由 AI 生成,仅供参考
你好,我是陈皓,网名左耳朵耗子。
读写分离 CQRS
读写分离是数据库扩展最简单实用的玩法了,这种方法针对读多写少的业务场景还是很管用的,而且还可以有效地把业务做相应的隔离。
如下图所示,数据库只有一个写库,有两个读库,所有的服务都写一个数据库。对于读操作来说,服务 A 和服务 B 走从库 A,服务 D 和服务 E 走从库 B,服务 C 在从库 A 和从库 B 间做轮询。
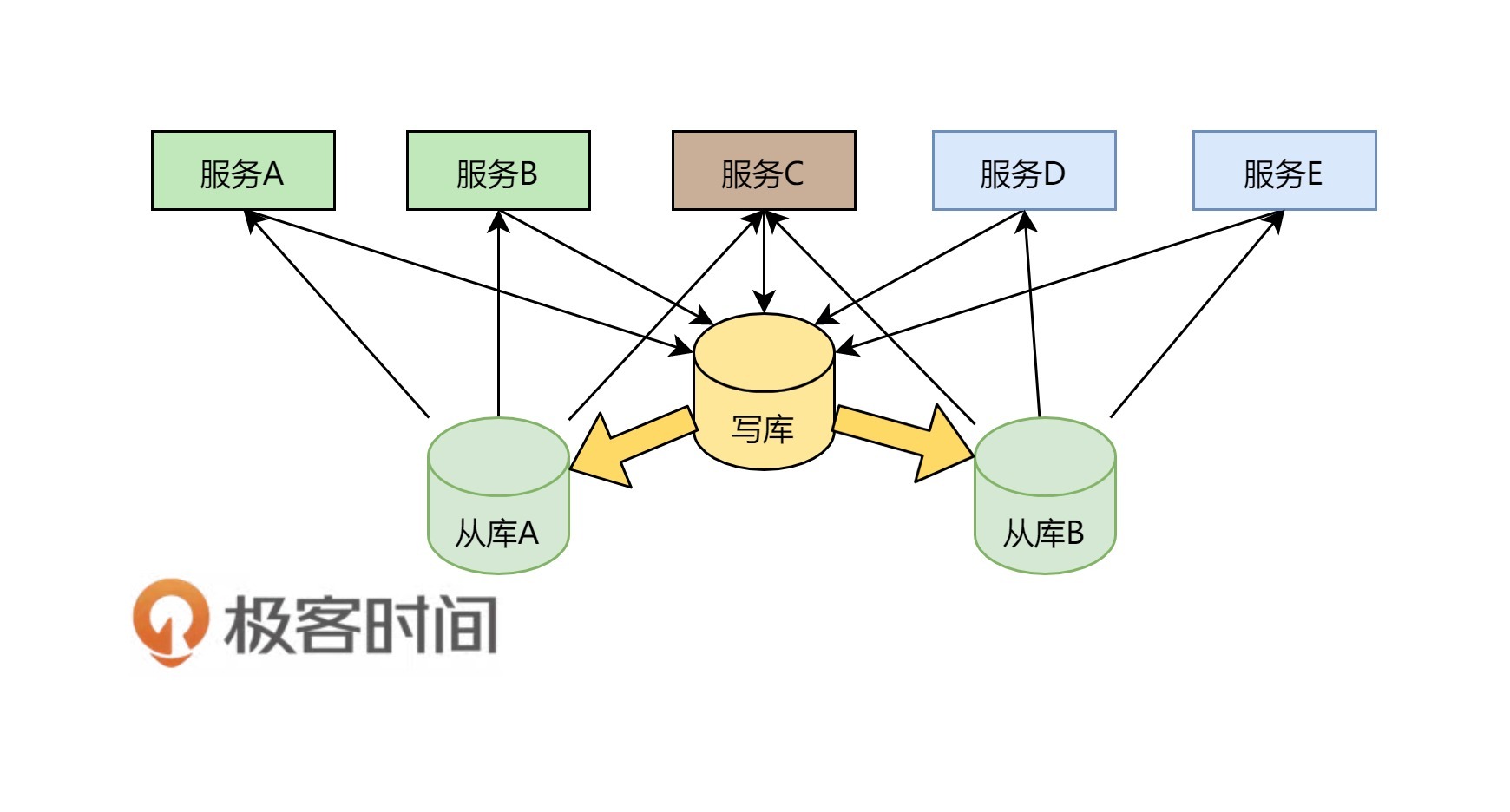
这样的方法好处是:
比较容易实现。数据库的 master-slave 的配置和服务框架里的读写分离都比较成熟,应用起来也很快。
可以很好地把各个业务隔离开来。不会因为一个业务把数据库拖死而导致所有的业务都死掉。
可以很好地分担数据库的读负载,毕竟读操作是最耗数据库 CPU 的操作。
这样的方法不好的地方是:
写库有单点故障问题。如果是写库出了性能问题,那么所有的业务一样不可用。对于交易型的业务,要得到高的写操作速度,这样的方式不行。
数据库同步不实时,需要强一致性的读写操作还是需要落在写库上。
综上所述,一般来说,这样的玩法主要是为了减少读操作的压力。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文介绍了在分布式系统设计中的性能设计方面的一些常见模式,包括读写分离、CQRS、Event Sourcing和分库分表。读写分离是一种简单实用的数据库扩展方法,能有效减轻数据库的读负载,但也存在一些问题。CQRS原则能提高系统的性能、可扩展性和安全性,同时保持高度的灵活性。Event Sourcing则可以降低系统的副作用,并提高并发和性能。此外,文章还介绍了分库分表的策略和中间件的应用,以及在实际应用中需要考虑的业务分片和数据使用模式等关键事项。总的来说,通过介绍这些性能设计模式,为读者提供了在分布式系统设计中优化数据库性能的思路和方法。文章还指出了数据库扩展的设计重点,强调了在拆解数据库和服务化后进行读写分离或分片的方式来获得更多的性能和吞吐量。对于分片模式,文章提到了水平分片和垂直分片,并列举了一些注意事项和挑战。整体而言,本文为读者提供了丰富的分布式系统设计模式知识,对于想要优化数据库性能的技术人员具有一定的参考价值。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《左耳听风》,新⼈⾸单¥98
《左耳听风》,新⼈⾸单¥98
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(23)
- 最新
- 精选
 mgxian索引表也越来越多大 需要分片怎么办呢
mgxian索引表也越来越多大 需要分片怎么办呢作者回复: 索引表没有业务属性,就是kv,没有join,没有group,所以非常容易用哈希分片
2018-05-17210 唐稳CQRS应该用在没有事务强一致性要求的场合,才能充分发挥其作用。不过微服务架构似乎更倾向于设计出最终一致性的程序。
唐稳CQRS应该用在没有事务强一致性要求的场合,才能充分发挥其作用。不过微服务架构似乎更倾向于设计出最终一致性的程序。作者回复: 嗯。另外,仔细想想,强一致性这种场景真的不多。
2018-05-178 W_T按照哈希散列分片,实现方案最简单,只需要在操作数据库的时候特殊处理就可以了。 按照业务分片,为了减少跨分片操作,在请求的前端就需要明确业务字段的值,所以并不是所有场景都适用,这些方案各有利弊。 不过有一点我还是赞同的,不到万不得已,不要用哈希散列分片,不然等到以后要重新分片的时候代价巨大。
W_T按照哈希散列分片,实现方案最简单,只需要在操作数据库的时候特殊处理就可以了。 按照业务分片,为了减少跨分片操作,在请求的前端就需要明确业务字段的值,所以并不是所有场景都适用,这些方案各有利弊。 不过有一点我还是赞同的,不到万不得已,不要用哈希散列分片,不然等到以后要重新分片的时候代价巨大。作者回复: 业务分片,其实直接就数据分库,服务拆分,走向微服务得了。
2018-05-174 sipom谢谢耗子老师。 我涉及的业务是金融交易的清算(批处理系统),需要保证主从库的数据强一致性,但mysql复制不能保证强一致性,这种情况怎么做为好呢?是在应用层写双库,做两阶段提交?还是有什么产品可用呢?
sipom谢谢耗子老师。 我涉及的业务是金融交易的清算(批处理系统),需要保证主从库的数据强一致性,但mysql复制不能保证强一致性,这种情况怎么做为好呢?是在应用层写双库,做两阶段提交?还是有什么产品可用呢?作者回复: 业务层上,只有两阶段提交,数据层上,只有Paxos
2018-06-143 吞枣感觉分库分表是分布式数据库到来之前的临时方案,另外感觉老外们好像并不怎么会采用分库分表,是这样吗?2018-05-22215
吞枣感觉分库分表是分布式数据库到来之前的临时方案,另外感觉老外们好像并不怎么会采用分库分表,是这样吗?2018-05-22215 ^o^一致性哈希2018-06-139
^o^一致性哈希2018-06-139 顾海耗哥,关于CQRS有个问题:从架构图上来看,往Query Store中写数据是异步的,并没有解决读写分离方案下的数据非实时同步的问题。如果CQRS不用异步写,那么就是双写了,就会带来分布式事务的问题。 关于数据库分片,我的一点想法:1如果机器升级,读写分离,缓存不能解决问题,才考虑分片方案。2是分库还是分表,也要视场景而定。如果只是数据量比较大,但是TPS/QPS不高,一个库能够满足未来预期的业务量增长,可以考虑只做分表,以规避分库带来的分布式事务问题。3分库分表的维度,要视业务场景。我们按一个主维度分库分表之后,由此会导致其他维度的查询问题。通常通过数据异构解决,有两种方式A按所有维度都把数据分库分表,在维度比较多的时候,这会导致数据维护的困难B使用ElasticSearch这种NOSQL数据库,只维护一份数据,但是对于不同维度的查询能够很好支撑。2020-04-256
顾海耗哥,关于CQRS有个问题:从架构图上来看,往Query Store中写数据是异步的,并没有解决读写分离方案下的数据非实时同步的问题。如果CQRS不用异步写,那么就是双写了,就会带来分布式事务的问题。 关于数据库分片,我的一点想法:1如果机器升级,读写分离,缓存不能解决问题,才考虑分片方案。2是分库还是分表,也要视场景而定。如果只是数据量比较大,但是TPS/QPS不高,一个库能够满足未来预期的业务量增长,可以考虑只做分表,以规避分库带来的分布式事务问题。3分库分表的维度,要视业务场景。我们按一个主维度分库分表之后,由此会导致其他维度的查询问题。通常通过数据异构解决,有两种方式A按所有维度都把数据分库分表,在维度比较多的时候,这会导致数据维护的困难B使用ElasticSearch这种NOSQL数据库,只维护一份数据,但是对于不同维度的查询能够很好支撑。2020-04-256- Geek_22d08b请问如果采用阿里云华为云的话,那么多技术要实现是不是只要购买阿里云他们相应的产品,然后配置下就可以了,就没程序员什么事了?2018-05-1915
 chaoqiang请只考虑业务分片。请不要走哈希散列的分片方式 对这句话不太理解,走哈希分片虽然是有跨表查询隐患,后续数据量再次暴涨也需要重新哈希,比较恶心,但也可以解决热点问题,而且互联网公司的用户数据大部分场景下都是有热点的吧,为什么皓叔这么反对呢?实际场景中会遇到什么更痛的点嘛?能否更详细地讲讲呢2018-05-1724
chaoqiang请只考虑业务分片。请不要走哈希散列的分片方式 对这句话不太理解,走哈希分片虽然是有跨表查询隐患,后续数据量再次暴涨也需要重新哈希,比较恶心,但也可以解决热点问题,而且互联网公司的用户数据大部分场景下都是有热点的吧,为什么皓叔这么反对呢?实际场景中会遇到什么更痛的点嘛?能否更详细地讲讲呢2018-05-1724 偏偏老师,你好,关于仓储这块有个问题,需要指点一下,如果我每个微服务对应一个数据库,这时我的表分散开来,有时会涉及到多个库连表查询的问题,在配置中怎么提现关系,请问老师这块在微服务中应如何处理。 1. 如果跨库联查应该在仓储层怎么定义。 2. 如果添加本地冗余表,会形成大量表和同步任务,不好维护。 3. 有没有一个中间件可以做到隔离数据库分库实现细节,在业务外层就相当于一个数据库。 如果使用mysql这种情况该如何实现。 4. 如果使用newsql类的数据库,如tidb是不是可以解决掉。2020-03-1212
偏偏老师,你好,关于仓储这块有个问题,需要指点一下,如果我每个微服务对应一个数据库,这时我的表分散开来,有时会涉及到多个库连表查询的问题,在配置中怎么提现关系,请问老师这块在微服务中应如何处理。 1. 如果跨库联查应该在仓储层怎么定义。 2. 如果添加本地冗余表,会形成大量表和同步任务,不好维护。 3. 有没有一个中间件可以做到隔离数据库分库实现细节,在业务外层就相当于一个数据库。 如果使用mysql这种情况该如何实现。 4. 如果使用newsql类的数据库,如tidb是不是可以解决掉。2020-03-1212
收起评论

