

58 | 性能设计:缓存
陈皓

该思维导图由 AI 生成,仅供参考
你好,我是陈皓,网名左耳朵耗子。
前面分享了《分布式系统设计模式》系列文章的前两部分——弹力设计篇和管理设计篇。今天开始这一系列的最后一部分内容——性能设计篇,主题为《性能设计篇之“缓存”》。
基本上来说,在分布式系统中最耗性能的地方就是最后端的数据库了。一般来说,只要小心维护好,数据库四种操作(select、update、insert 和 delete)中的三个写操作 insert、update 和 delete 不太会出现性能问题(insert 一般不会有性能问题,update 和 delete 一般会有主键,所以也不会太慢)。除非索引建得太多,而数据库里的数据又太多,这三个操作才会变慢。
绝大多数情况下,select 是出现性能问题最大的地方。一方面,select 会有很多像 join、group、order、like 等这样丰富的语义,而这些语义是非常耗性能的;另一方面,大多数应用都是读多写少,所以加剧了慢查询的问题。
分布式系统中远程调用也会消耗很多资源,因为网络开销会导致整体的响应时间下降。为了挽救这样的性能开销,在业务允许的情况(不需要太实时的数据)下,使用缓存是非常必要的事情。
从另一个方面说,缓存在今天的移动互联网中是必不可少的一部分,因为网络质量不一定永远是最好的,所以前端也会为所有的 API 加上缓存。不然,网络不通畅的时候,没有数据,前端都不知道怎么展示 UI 了。既然因为移动互联网的网络质量而导致我们必须容忍数据的不实时性,那么,从业务上来说,在大多数情况下是可以使用缓存的。
缓存是提高性能最好的方式,一般来说,缓存有以下三种模式。
Cache Aside 更新模式
这是最常用的设计模式了,其具体逻辑如下。
失效:应用程序先从 Cache 取数据,如果没有得到,则从数据库中取数据,成功后,放到缓存中。
命中:应用程序从 Cache 中取数据,取到后返回。
更新:先把数据存到数据库中,成功后,再让缓存失效。
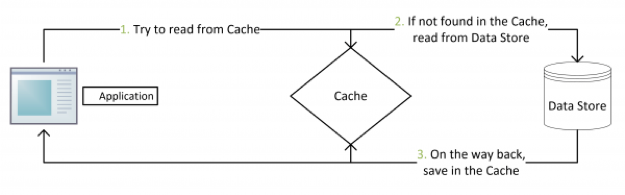
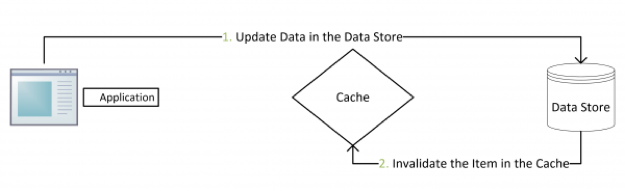
这是标准的设计模式,包括 Facebook 的论文《Scaling Memcache at Facebook》中也使用了这个策略。为什么不是写完数据库后更新缓存?你可以看一下 Quora 上的这个问答《Why does Facebook use delete to remove the key-value pair in Memcached instead of updating the Memcached during write request to the backend?》,主要是怕两个并发的写操作导致脏数据。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

分布式系统设计模式中的性能设计篇之“缓存”一文深入探讨了在分布式系统中使用缓存提高性能的重要性以及三种常见的缓存模式。文章指出数据库操作和远程调用在分布式系统中是性能瓶颈,因此使用缓存是必要的。缓存模式包括Cache Aside、Read/Write Through和Write Behind Caching,每种模式都有其特点和适用场景。文章还强调了在分布式架构下,缓存集群、命中率、数据更新延迟、缓存数据的时间周期以及LRU策略等方面的重要性。此外,文章还提到了缓存设计中需要考虑的一致性、锁竞争、爬虫保护等问题。总的来说,缓存是为了加速数据访问,在数据库之上添加的一层机制,而在分布式架构下,对缓存集群、一致性、LRU的锁竞争、爬虫等多方面都需要认真考虑。通过本文的阅读,读者可以快速了解分布式系统中缓存的重要性以及不同的缓存模式,为性能设计提供了有益的参考。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《左耳听风》,新⼈⾸单¥98
《左耳听风》,新⼈⾸单¥98
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(34)
- 最新
- 精选
 Black这篇的内容有大部分是跟之前博客上的一篇 缓存更新的套路 重复了
Black这篇的内容有大部分是跟之前博客上的一篇 缓存更新的套路 重复了作者回复: 是的。这是为了整个系列的完整。
2018-05-105 riverCache aside 更新数据库 然后失效缓存,在读很高的情况下,会不会相当于缓存被击穿?
riverCache aside 更新数据库 然后失效缓存,在读很高的情况下,会不会相当于缓存被击穿?作者回复: 怎么会呢?
2018-05-13104 坤陈皓老师好,redis 分片热点问题,有没有什么好的解决方案?
坤陈皓老师好,redis 分片热点问题,有没有什么好的解决方案?作者回复: 建数据索引服务
2018-05-10 翎逸感觉更多的是不是应该说下缓存的监控,雪崩,缓存和数据库的一致性,以及热点缓存处理等一些场景的处理,这样会觉得更深入一些2018-05-10739
翎逸感觉更多的是不是应该说下缓存的监控,雪崩,缓存和数据库的一致性,以及热点缓存处理等一些场景的处理,这样会觉得更深入一些2018-05-10739 顾海这篇文章偏科普,除此之外,我的总结 1.某些场景下,LocalCache比较有效,可以解决远程缓存热点数据问题。另外,可以通过多副本缓存解决热点数据的读问题,例如redis cluster的多多机制。 2.更新数据和(删除)更新缓存的先后顺序问题:一般是先更新数据库,再去操作缓存。缓存操作失败时可以通过重试操作缓存以实现最终一致性。如果是先操作缓存,再处理数据库,很有可能导致缓存中的是脏数据,而且不能实现最终一致性。 3.并发更新缓存时,存在旧数据覆盖新数据的可能。可以通过CAS机制比较缓存中的数据与待放去缓存的数据的版本,如果缓存中的数据比较新,则放弃本次的缓存操作。 4.缓存穿透,缓存雪崩问题2020-04-26111
顾海这篇文章偏科普,除此之外,我的总结 1.某些场景下,LocalCache比较有效,可以解决远程缓存热点数据问题。另外,可以通过多副本缓存解决热点数据的读问题,例如redis cluster的多多机制。 2.更新数据和(删除)更新缓存的先后顺序问题:一般是先更新数据库,再去操作缓存。缓存操作失败时可以通过重试操作缓存以实现最终一致性。如果是先操作缓存,再处理数据库,很有可能导致缓存中的是脏数据,而且不能实现最终一致性。 3.并发更新缓存时,存在旧数据覆盖新数据的可能。可以通过CAS机制比较缓存中的数据与待放去缓存的数据的版本,如果缓存中的数据比较新,则放弃本次的缓存操作。 4.缓存穿透,缓存雪崩问题2020-04-26111 W_TRead/Write Through 模式中对数据库的操作一定要交给交给缓存代理么,如果是这样就会带来两个问题: 1. 需要在缓存服务中实现数据库操作的代码,我从来没有这么做过,也不清楚目前主流缓存是否支持这样的操作。 2. 缓存服务与数据库之间建立了依赖。 我在工作中更常见的做法是由应用服务操作缓存以及数据库,这样的话感觉就跟前面的cache aside模式很像了。 可能是我对Read/Write Through模式理解不深,说错的地方还请老师指正2018-05-1035
W_TRead/Write Through 模式中对数据库的操作一定要交给交给缓存代理么,如果是这样就会带来两个问题: 1. 需要在缓存服务中实现数据库操作的代码,我从来没有这么做过,也不清楚目前主流缓存是否支持这样的操作。 2. 缓存服务与数据库之间建立了依赖。 我在工作中更常见的做法是由应用服务操作缓存以及数据库,这样的话感觉就跟前面的cache aside模式很像了。 可能是我对Read/Write Through模式理解不深,说错的地方还请老师指正2018-05-1035 知行合一三大缓存设计模式,cache aside,read/write through,write behind cache;缓存是以空间换时间,牺牲了强一致性,带来高性能和可用性。缓存分片希望也能分析分析2020-01-114
知行合一三大缓存设计模式,cache aside,read/write through,write behind cache;缓存是以空间换时间,牺牲了强一致性,带来高性能和可用性。缓存分片希望也能分析分析2020-01-114 shawn你好,我看了“架构之路”的公众号, https://mp.weixin.qq.com/s?__biz=MjM5ODYxMDA5OQ==&mid=404202261&idx=1&sn=1b8254ba5013952923bdc21e0579108e&scene=21#wechat_redirect 这里说了大部分场景是建议 先 “缓存失效 -> 再更新数据”。 比如:先写数据再淘汰缓存会有如下情况: “假设先写数据库,再淘汰缓存:第一步写数据库操作成功,第二步淘汰缓存失败,则会出现DB中是新数据,Cache中是旧数据,数据不一致【如上图:db中是新数据,cache中是旧数据】。” 我想听听你的看法。2018-12-1273
shawn你好,我看了“架构之路”的公众号, https://mp.weixin.qq.com/s?__biz=MjM5ODYxMDA5OQ==&mid=404202261&idx=1&sn=1b8254ba5013952923bdc21e0579108e&scene=21#wechat_redirect 这里说了大部分场景是建议 先 “缓存失效 -> 再更新数据”。 比如:先写数据再淘汰缓存会有如下情况: “假设先写数据库,再淘汰缓存:第一步写数据库操作成功,第二步淘汰缓存失败,则会出现DB中是新数据,Cache中是旧数据,数据不一致【如上图:db中是新数据,cache中是旧数据】。” 我想听听你的看法。2018-12-1273 冰糕不冰皓哥,对于很多需要统计的数据或者筛选条件复杂的怎么利用缓存了?2018-06-0113
冰糕不冰皓哥,对于很多需要统计的数据或者筛选条件复杂的怎么利用缓存了?2018-06-0113 如来神掌Cache Aside 的方式就挺好,简单好用,脏数据发生的可能性还非常小2020-07-292
如来神掌Cache Aside 的方式就挺好,简单好用,脏数据发生的可能性还非常小2020-07-292
收起评论

