

55 | 理解Disruptor(下):不需要换挡和踩刹车的CPU,有多快?

该思维导图由 AI 生成,仅供参考
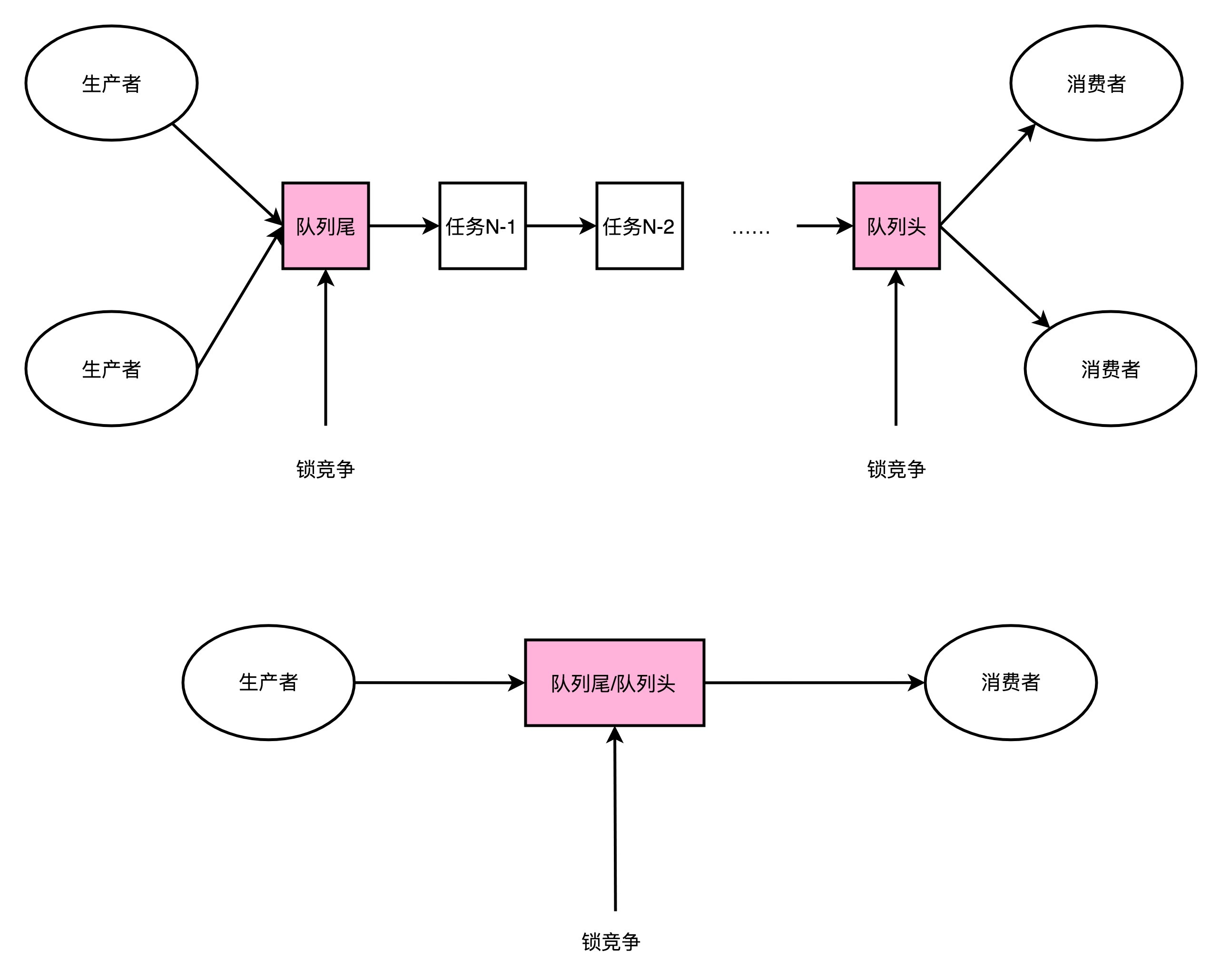
缓慢的锁
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

Disruptor的RingBuffer利用CPU硬件支持的CAS指令实现了无锁队列,避免了锁竞争和上下文切换的性能损耗。相比于基于锁的队列,Disruptor的RingBuffer在生产者-消费者模式下表现更快。文章通过对比实验结果和CAS指令的性能,生动地展示了无锁设计原理和性能优势。RingBuffer采用CAS操作进行序号的自增和对比,使得CPU不需要获取操作系统的锁,从而避免了上下文切换,提升了程序运行速度。然而,由于采用了忙等待的方式,会使CPU始终满负荷运转,消耗更多电力。文章还推荐了相关阅读材料,并留下了一道思考题,鼓励读者深入探讨应用层和硬件层之间的关联性。 Disruptor的无锁设计原理和性能优势使其成为一个值得深入研究的开源库。
《深入浅出计算机组成原理》,新⼈⾸单¥68

全部留言(25)
- 最新
- 精选
- 唐朝农民ReentrantLock内部不也是CAS实现的吗
作者回复: 并不是,ReentrantLock内部只是有CAS方法的调用而已,而这个调用是为了做状态检查和获取锁。 ReetrantLock最终会调用AbstractQueuedSynchronizer,并且会在拿不到锁的时候会有让当前节点sleep的过程。 这个可以深入读一下ReetrantLock的源码。 本质上,ReentrantLock等于是在Java层面实现了一个跨平台的锁机制,它的底层调用用到了CAS方法而已。而不是直接基于CAS来设计队列。
2019-09-0927  姜戈课后问题: 对比了Sequence与AtomicLong源码,在于CAS之前,Disruptor直接取原有值,做CAS操作;而AtomicLong使用了getLongVolatile获值。 两者value都用了Volatile来修饰,这点是共同的;但在于获值时,AtomicLong又再次使用volatile(getLongVolatile), 由于Volatile会在内存中强行刷新此值,相比这样就会增加一次性能的消耗,另外还有Spinlock(自旋锁),这两点都会带来性能消耗。 为什么Disruptor可以这样做,免掉getLongVolatile操作,我猜想应该是缓存行的填充,避免了伪共享(False Sharing)的问题,线程对value值的修改,不会出现不同线程同时修改同一缓存行不同变量的问题,所以不需要再次强行刷内存的步骤。 请老师指正!!! /** Sequence关于取值是直接Get(), 查看内部方法直接返回value * * Atomically add the supplied value. * * @param increment The value to add to the sequence. * @return The value after the increment. */ public long addAndGet(final long increment) { long currentValue; long newValue; do { currentValue = get(); newValue = currentValue + increment; } while (!compareAndSet(currentValue, newValue)); return newValue; } /** AtomicLong关于取值时使用getLongVolatile,查看其源码,增加了Volatile和自旋锁 * * getAndAddLong * */ public final long getAndAddLong(Object var1, long var2, long var4) { long var6; do { var6 = this.getLongVolatile(var1, var2); } while(!this.compareAndSwapLong(var1, var2, var6, var6 + var4)); return var6; } /** getLongVolatile源码(C++) * * 1. volatile, 刷新内存 * 2.Spinlock, 自旋锁 */ jlong sun::misc::Unsafe::getLongVolatile (jobject obj, jlong offset) { volatile jlong *addr = (jlong *) ((char *) obj + offset); spinlock lock; return *addr; }
姜戈课后问题: 对比了Sequence与AtomicLong源码,在于CAS之前,Disruptor直接取原有值,做CAS操作;而AtomicLong使用了getLongVolatile获值。 两者value都用了Volatile来修饰,这点是共同的;但在于获值时,AtomicLong又再次使用volatile(getLongVolatile), 由于Volatile会在内存中强行刷新此值,相比这样就会增加一次性能的消耗,另外还有Spinlock(自旋锁),这两点都会带来性能消耗。 为什么Disruptor可以这样做,免掉getLongVolatile操作,我猜想应该是缓存行的填充,避免了伪共享(False Sharing)的问题,线程对value值的修改,不会出现不同线程同时修改同一缓存行不同变量的问题,所以不需要再次强行刷内存的步骤。 请老师指正!!! /** Sequence关于取值是直接Get(), 查看内部方法直接返回value * * Atomically add the supplied value. * * @param increment The value to add to the sequence. * @return The value after the increment. */ public long addAndGet(final long increment) { long currentValue; long newValue; do { currentValue = get(); newValue = currentValue + increment; } while (!compareAndSet(currentValue, newValue)); return newValue; } /** AtomicLong关于取值时使用getLongVolatile,查看其源码,增加了Volatile和自旋锁 * * getAndAddLong * */ public final long getAndAddLong(Object var1, long var2, long var4) { long var6; do { var6 = this.getLongVolatile(var1, var2); } while(!this.compareAndSwapLong(var1, var2, var6, var6 + var4)); return var6; } /** getLongVolatile源码(C++) * * 1. volatile, 刷新内存 * 2.Spinlock, 自旋锁 */ jlong sun::misc::Unsafe::getLongVolatile (jobject obj, jlong offset) { volatile jlong *addr = (jlong *) ((char *) obj + offset); spinlock lock; return *addr; }作者回复: 抱歉,不过你的 AtomicLong 部分的代码时从哪里看到的?似乎和open jdk里面的源码完全不一样。 Sequence主要是做了Cache Line Padding,来解决False Sharing的问题,和AtomicLong比较,避免Cache里面的数据被反复交换到内存里面去。 “ In fact the only real difference between the 2 is that the Sequence contains additional functionality to prevent false sharing between Sequences and other values.”
2019-09-09320 活的潇洒极客时间买了13个专栏,终于完成了一个专栏的所有笔记 专栏所有笔记如下:https://www.cnblogs.com/luoahong/p/10496701.html
活的潇洒极客时间买了13个专栏,终于完成了一个专栏的所有笔记 专栏所有笔记如下:https://www.cnblogs.com/luoahong/p/10496701.html作者回复: 👍不容易
2019-09-15713 南山专栏最开始就订阅了,看到了这篇专栏目录中的这篇文档标题,当时就想着要从底层了解disruptor的原理,也一篇一篇认真的跟了下来,不知不觉就到了今天,虽然有很多后续还是要回去时常翻阅的知识点,但是也庆幸自己能一路跟着老师到现在。 课后思考题会去翻源码再回来补充
南山专栏最开始就订阅了,看到了这篇专栏目录中的这篇文档标题,当时就想着要从底层了解disruptor的原理,也一篇一篇认真的跟了下来,不知不觉就到了今天,虽然有很多后续还是要回去时常翻阅的知识点,但是也庆幸自己能一路跟着老师到现在。 课后思考题会去翻源码再回来补充作者回复: 👍 Disruptor的代码短小精干,很适合深入读一读
2019-09-0910 D看了下jdk 1.8的 AtomicLong 和disruptor的sequence, 个人认为有两点不同: 1. disruptor 加了上一讲里面的padding, 以进一步利用缓存。 2. Atomiclong 里面提供了更多的方法,并且判断cpu是否支持无锁cas 相同点,底层都是调用unsafe类实现硬件层面的操作,以跳过jdk的限制。
D看了下jdk 1.8的 AtomicLong 和disruptor的sequence, 个人认为有两点不同: 1. disruptor 加了上一讲里面的padding, 以进一步利用缓存。 2. Atomiclong 里面提供了更多的方法,并且判断cpu是否支持无锁cas 相同点,底层都是调用unsafe类实现硬件层面的操作,以跳过jdk的限制。作者回复: 👍理解准确到位
2019-09-098- 姜戈LinkedBlockingQueue源码(JDK1.8)看了一下, 使用的是ReentrantLock和Condition来控制的,没发现老师说的synchronized关键字, 是不是哪里我忽略掉了?
作者回复: 是我笔误了,是ReetrantLock,下面我给的对比示例也是ReentrantLock的。
2019-09-095  免费的人Cas仍然会涉及到内存读取,老师能否介绍下rcu锁?
免费的人Cas仍然会涉及到内存读取,老师能否介绍下rcu锁?作者回复: 是的,CAS仍然会涉及到内存读取。 我之前没有仔细了解过RCU,今天简单看了一下资料,如果我的理解没有错的话。作为读写锁替代的话,是OK的。不过在Disruptor的场景下,Consumer需要的并不是一个读写锁,Producer和Consumer因为都需要更新自己的位置,其实是两个写锁。我直觉上觉得并没有办法依靠RCU的方式来解决。 不过这个值得仔细想一下。
2019-09-113 leslie学习中一步步跟进:越来越明白其实真正弄明白为何学习的中间层其实是操作系统和计算机原理;就像老师的课程中不少就和操作系统相关,而在此基础上可以衍生出一系列相关的知识。 就像老师的2个TOP:存储与IO系统,应用篇分别就是一个向下一个向上;代码题对于不做纯代码超过5年的来说有点难,跟课再去学Java有点难且时间实在不够-毕竟运维的coding能力都偏差,不过大致能明白原理,从原理层去解释一些问题的根源原因,以及某些场合下那些可能更加适用。 其实通过操作系统和组成原理会衍生出很多知识:选择合适的方向专攻确实不错。向老师提个小的要求:希望在最后一堂课可以分享老师在做这个专栏所查阅的主要书籍,毕竟没人可以学完一遍就基本掌握的;老师所看的核心资料是我们后续再看课程提升自己的一个辅助手段吧。
leslie学习中一步步跟进:越来越明白其实真正弄明白为何学习的中间层其实是操作系统和计算机原理;就像老师的课程中不少就和操作系统相关,而在此基础上可以衍生出一系列相关的知识。 就像老师的2个TOP:存储与IO系统,应用篇分别就是一个向下一个向上;代码题对于不做纯代码超过5年的来说有点难,跟课再去学Java有点难且时间实在不够-毕竟运维的coding能力都偏差,不过大致能明白原理,从原理层去解释一些问题的根源原因,以及某些场合下那些可能更加适用。 其实通过操作系统和组成原理会衍生出很多知识:选择合适的方向专攻确实不错。向老师提个小的要求:希望在最后一堂课可以分享老师在做这个专栏所查阅的主要书籍,毕竟没人可以学完一遍就基本掌握的;老师所看的核心资料是我们后续再看课程提升自己的一个辅助手段吧。作者回复: 从运维的角度,其实还有一个重要的主题是网络,也值得仔细关注一下。 在专栏的每篇文章后面列了推荐阅读,也在一开始的学习方法的那一讲里面列了一些参考资料。可以先从这些看起。 另外一个去处是去看Wikipedia对应的条目以及相关引用。
2019-09-0923 逍遥法外ReentrantLock内部也有CAS的操作,只不过也会有Lock的操作。Disruptor直接使用CAS,是简化了操作。
逍遥法外ReentrantLock内部也有CAS的操作,只不过也会有Lock的操作。Disruptor直接使用CAS,是简化了操作。作者回复: 👍 ReetrantLock里面的CAS是作为调用方式,最终来实现一个JVM上跨平台的锁的
2019-09-093 分清云淡文章中加锁和不加锁性能比较的case老师的数据是差了50倍,我在intel E5 v4和鲲鹏920下跑出来都是查了80倍。 不过其中的原因不是因为加锁,而是lock.lock() 函数自身包含了几十条指令,而++只有简单的几个指令,也就是两者指令数就差了1个数量级。 例子中不加锁性能好的另外一个原因是 ++指令 对流水线十分友好,基本能跑满流水线(IPC 跑到4);而lock()那堆指令只能把IPC跑到0.5-0.8之间。 在只有一个线程的情况下加锁中的"锁"对性能是没有任何影响的,比如假设你的业务逻辑几万个指令,加上lock()多出来的几十个指令基本,基本是没有啥影响的。只有一个线程不会真正发生切换、等锁的糟心操作。只需要考虑实际指令量和对pipeline的友好程度2021-06-0714
分清云淡文章中加锁和不加锁性能比较的case老师的数据是差了50倍,我在intel E5 v4和鲲鹏920下跑出来都是查了80倍。 不过其中的原因不是因为加锁,而是lock.lock() 函数自身包含了几十条指令,而++只有简单的几个指令,也就是两者指令数就差了1个数量级。 例子中不加锁性能好的另外一个原因是 ++指令 对流水线十分友好,基本能跑满流水线(IPC 跑到4);而lock()那堆指令只能把IPC跑到0.5-0.8之间。 在只有一个线程的情况下加锁中的"锁"对性能是没有任何影响的,比如假设你的业务逻辑几万个指令,加上lock()多出来的几十个指令基本,基本是没有啥影响的。只有一个线程不会真正发生切换、等锁的糟心操作。只需要考虑实际指令量和对pipeline的友好程度2021-06-0714

