

25 | 冒险和预测(四):今天下雨了,明天还会下雨么?
徐文浩

该思维导图由 AI 生成,仅供参考
过去三讲,我主要为你介绍了结构冒险和数据冒险,以及增加资源、流水线停顿、操作数前推、乱序执行,这些解决各种“冒险”的技术方案。
在结构冒险和数据冒险中,你会发现,所有的流水线停顿操作都要从指令执行阶段开始。流水线的前两个阶段,也就是取指令(IF)和指令译码(ID)的阶段,是不需要停顿的。CPU 会在流水线里面直接去取下一条指令,然后进行译码。
取指令和指令译码不会需要遇到任何停顿,这是基于一个假设。这个假设就是,所有的指令代码都是顺序加载执行的。不过这个假设,在执行的代码中,一旦遇到 if…else 这样的条件分支,或者 for/while 循环,就会不成立。
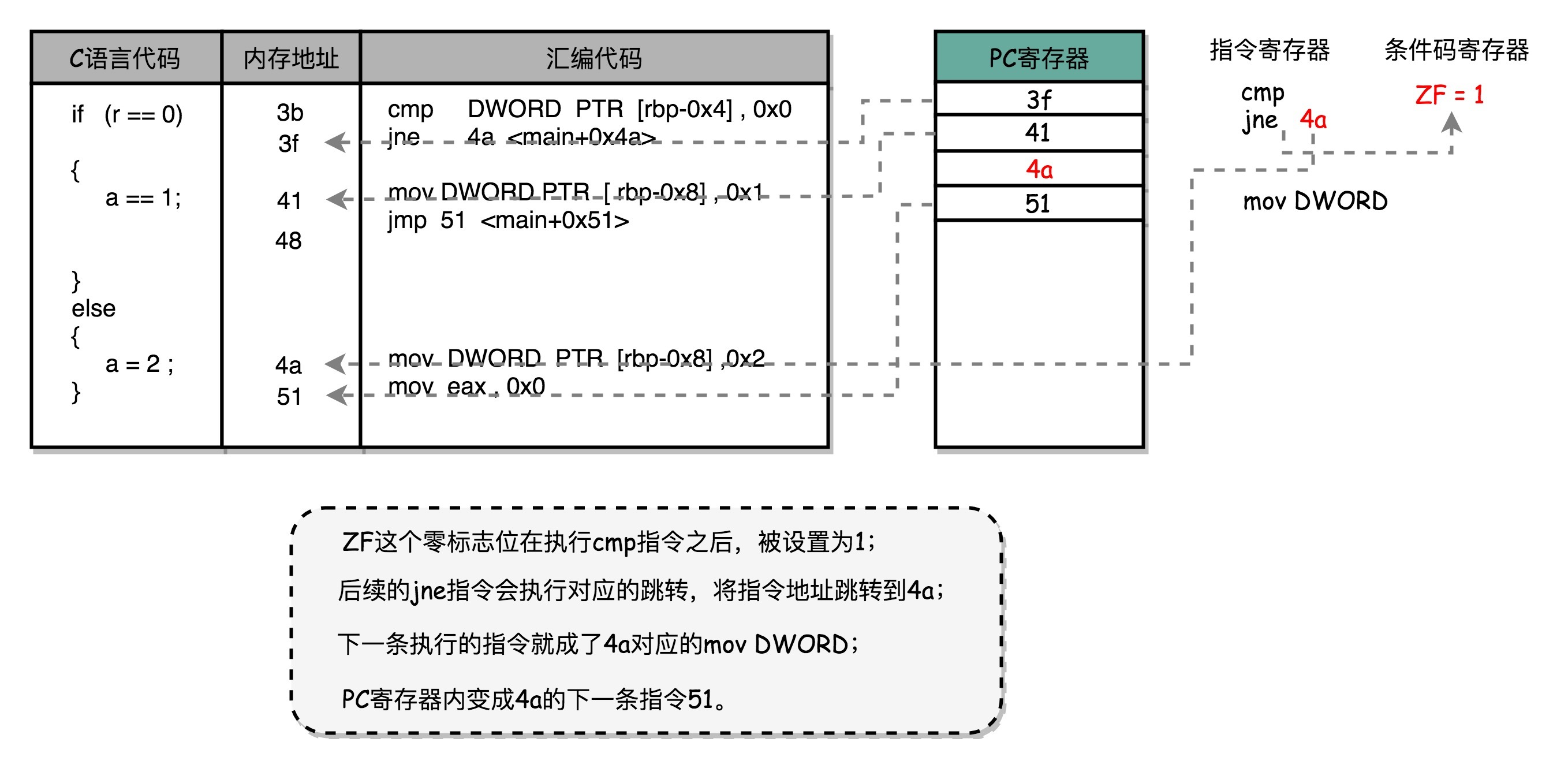
回顾一下第 6 讲的条件跳转流程
我们先来回顾一下,第 6 讲里讲的 cmp 比较指令、jmp 和 jle 这样的条件跳转指令。可以看到,在 jmp 指令发生的时候,CPU 可能会跳转去执行其他指令。jmp 后的那一条指令是否应该顺序加载执行,在流水线里面进行取指令的时候,我们没法知道。要等 jmp 指令执行完成,去更新了 PC 寄存器之后,我们才能知道,是否执行下一条指令,还是跳转到另外一个内存地址,去取别的指令。
这种为了确保能取到正确的指令,而不得不进行等待延迟的情况,就是今天我们要讲的控制冒险(Control Harzard)。这也是流水线设计里最后一种冒险。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文介绍了控制冒险在计算机流水线设计中的挑战,并提出了三种应对控制冒险的方式。首先是缩短分支延迟,通过提前进行条件比较和地址跳转来减少流水线停顿时间。其次是静态分支预测,即假装分支不发生,通过简单的预测策略来提高预测准确率。最后是动态分支预测,引入状态机来根据历史分支信息进行预测,提高预测准确率。这些方法在硬件层面和预测算法上有所不同,但都旨在提高CPU对控制冒险的应对能力。文章通过生动的比喻和实例,使读者能够快速了解这些技术特点,为深入了解分支预测技术提供了基础。此外,文章还通过一个Java程序的例子展示了分支预测出错对程序性能的影响,引发读者对分支预测技术的思考。文章推荐了进一步了解控制冒险和分支预测技术的书籍,并鼓励读者分享自己的疑惑和见解。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《深入浅出计算机组成原理》,新⼈⾸单¥68
《深入浅出计算机组成原理》,新⼈⾸单¥68
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(36)
- 最新
- 精选
 韩俊臣”在这样的情况下,上面的第一段循环,也就是内层 k 循环 10000 次的代码。每隔 10000 次,才会发生一次预测上的错误。而这样的错误,在第二层 j 的循环发生的次数,是 1000 次。” 求老师和各位大佬指点下,这句没太看明白,为啥每隔10000次才出现一次预测错误
韩俊臣”在这样的情况下,上面的第一段循环,也就是内层 k 循环 10000 次的代码。每隔 10000 次,才会发生一次预测上的错误。而这样的错误,在第二层 j 的循环发生的次数,是 1000 次。” 求老师和各位大佬指点下,这句没太看明白,为啥每隔10000次才出现一次预测错误作者回复: 韩俊臣同学, 你好,最内层的循环,要执行10000次,前面的9999次都是继续执行下一次循环指令,最后一次是结束循环。预测的话,前面9999次都会预测会继续执行指令,到最后一次的预测会出错。
2019-09-18213 许先森“要等 jmp 指令执行完成,去更新了 PC 寄存器之后,我们才能知道,是否执行下一条指令,还是跳转到另外一个内存地址,去取别的指令。” 这一段说错了吧?应该是cmp执行完,更新条件码寄存器,才能知道是否执行下一条还是跳转到另一个内存地址,取别的指令
许先森“要等 jmp 指令执行完成,去更新了 PC 寄存器之后,我们才能知道,是否执行下一条指令,还是跳转到另外一个内存地址,去取别的指令。” 这一段说错了吧?应该是cmp执行完,更新条件码寄存器,才能知道是否执行下一条还是跳转到另一个内存地址,取别的指令作者回复: 许先森同学, 你好,这里没有错哦。 cmp指令执行完之后,仍然是顺序执行下一条jmp指令。 但是jmp指令执行完之后,不一定是顺序执行jmp后面的指令,而是要看跳转是否发生,发生的话,执行的就是跳转地址之后的指令了。如果跳转没有发生,才是继续执行jmp后面地址的指令。
2020-01-1429 易飞
易飞 python,第一个例子60s,第二个例子53s
python,第一个例子60s,第二个例子53s作者回复: 哈哈,这还真在我意料之外,不过作为解释性语言,也的确有可能发生这样的事情,回头我研究研究。
2021-09-2442- 鱼向北游徐老师 这个for循环的原理是对的,但是例子可能不恰当,因为这个例子耗时最长的不是cpu分支冒险,而是最后一层循环的临时变量创建次数,属于栈的问题,如果要测试分支预测,需要int i,j,k在循环外初始化好,但是这样的话目前100,1000,10000次的循环是几乎看不到差异的,甚至得出的结果会相反,在最大的循环扩充到1000万次(总量为10万亿次,才能感受到冒险的差异)。希望老师能看到,顺便改下例子2019-07-0224102
 焰火以后写代码的时候养成良好习惯,按事件概率高低在分支中升序或降序安排,争取让状态机少判断2019-07-20627
焰火以后写代码的时候养成良好习惯,按事件概率高低在分支中升序或降序安排,争取让状态机少判断2019-07-20627 test实验结果,首先是根据与“鱼向北游”同学的一致,把i j k放在循环外面,必须增大一万倍才有明显的性能差距(10倍左右); 其次是那个循环的解释,我理解是,最内层的错误预测是一次,但是“底层循环”因为中层执行了1000次,所以是1000次错误判断,而中层的错误判断是一次,但是因为最外层循环导致“中层循环”执行了100次,所以是100次错误判断。2020-05-30313
test实验结果,首先是根据与“鱼向北游”同学的一致,把i j k放在循环外面,必须增大一万倍才有明显的性能差距(10倍左右); 其次是那个循环的解释,我理解是,最内层的错误预测是一次,但是“底层循环”因为中层执行了1000次,所以是1000次错误判断,而中层的错误判断是一次,但是因为最外层循环导致“中层循环”执行了100次,所以是100次错误判断。2020-05-30313 喜欢吃鱼哈哈,之前问今天这个程序问题的是我,明白了,谢谢老师的讲解。2019-06-218
喜欢吃鱼哈哈,之前问今天这个程序问题的是我,明白了,谢谢老师的讲解。2019-06-218 七色凉橙可以对比陈皓博客里面CPU cache这篇文章一起理解一下:https://coolshell.cn/articles/10249.html2020-04-166
七色凉橙可以对比陈皓博客里面CPU cache这篇文章一起理解一下:https://coolshell.cn/articles/10249.html2020-04-166 小白package main import ( "fmt" "time" ) func main() { start := time.Now() for i := 0; i < 100; i++ { for j := 0; j < 1000; j++ { for k := 0; k < 10000; k++ { } } } fmt.Println(time.Since(start)) start = time.Now() for i := 0; i < 10000; i++ { for j := 0; j < 1000; j++ { for k := 0; k < 100; k++ { } } } fmt.Println(time.Since(start)) } 417.9044ms 544.5435ms2019-06-2135
小白package main import ( "fmt" "time" ) func main() { start := time.Now() for i := 0; i < 100; i++ { for j := 0; j < 1000; j++ { for k := 0; k < 10000; k++ { } } } fmt.Println(time.Since(start)) start = time.Now() for i := 0; i < 10000; i++ { for j := 0; j < 1000; j++ { for k := 0; k < 100; k++ { } } } fmt.Println(time.Since(start)) } 417.9044ms 544.5435ms2019-06-2135 pebble你的机子好厉害,第一个例子语言五毫秒,我测试,c语言需要4337跟4492毫秒,c#需要5367跟5585毫秒,看来cpu的分支预测机制有大的改进了,不知道是什么机制2019-06-2114
pebble你的机子好厉害,第一个例子语言五毫秒,我测试,c语言需要4337跟4492毫秒,c#需要5367跟5585毫秒,看来cpu的分支预测机制有大的改进了,不知道是什么机制2019-06-2114
收起评论

