

26 | Superscalar和VLIW:如何让CPU的吞吐率超过1?
徐文浩
该思维导图由 AI 生成,仅供参考
到今天为止,专栏已经过半了。过去的 20 多讲里,我给你讲的内容,很多都是围绕着怎么提升 CPU 的性能这个问题展开的。
程序的 CPU 执行时间 = 指令数 × CPI × Clock Cycle Time
这个公式里,有一个叫 CPI 的指标。我们知道,CPI 的倒数,又叫作 IPC(Instruction Per Clock),也就是一个时钟周期里面能够执行的指令数,代表了 CPU 的吞吐率。那么,这个指标,放在我们前面几节反复优化流水线架构的 CPU 里,能达到多少呢?
答案是,最佳情况下,IPC 也只能到 1。因为无论做了哪些流水线层面的优化,即使做到了指令执行层面的乱序执行,CPU 仍然只能在一个时钟周期里面,取一条指令。
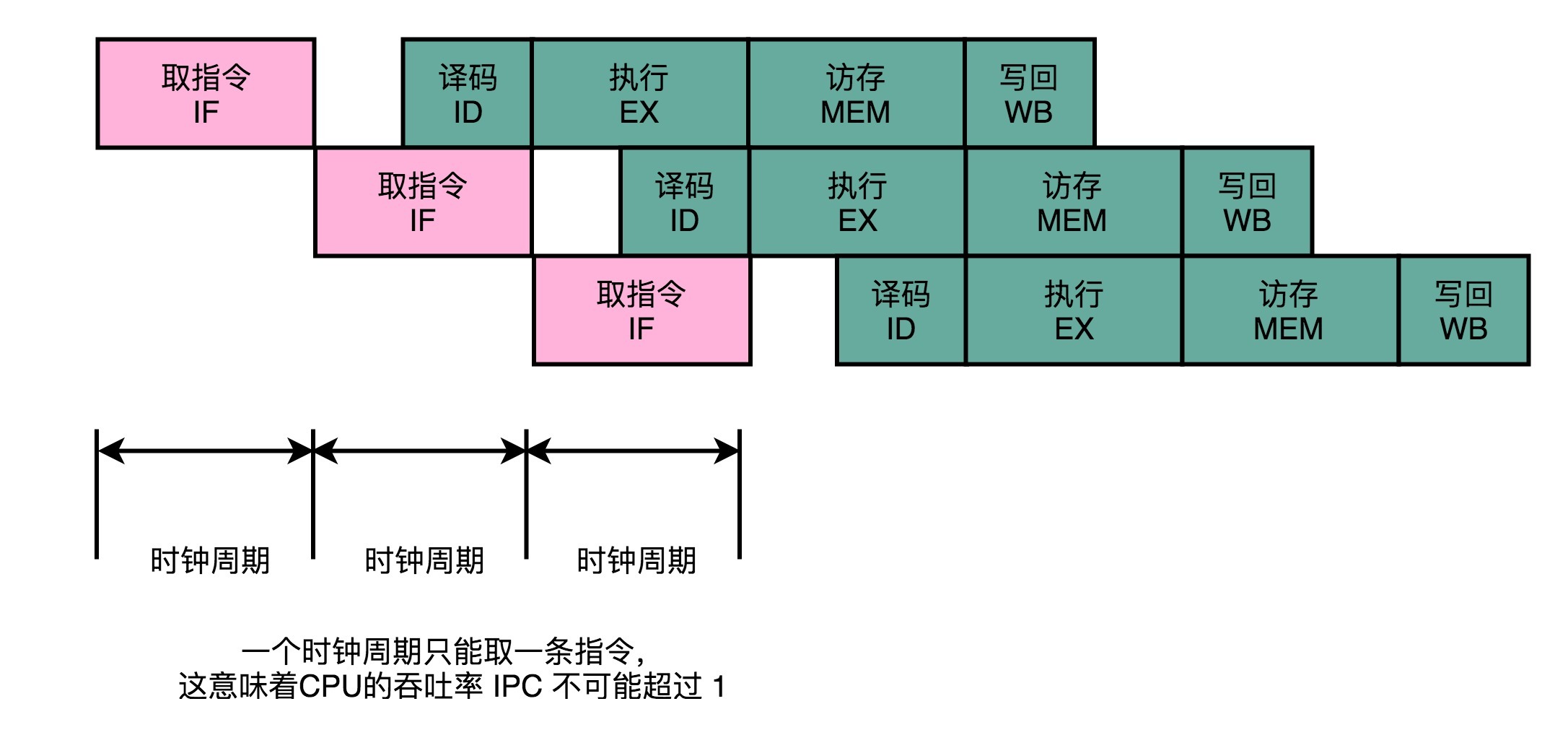
这说明,无论指令后续能优化得多好,一个时钟周期也只能执行完这样一条指令,CPI 只能是 1。但是,我们现在用的 Intel CPU 或者 ARM 的 CPU,一般的 CPI 都能做到 2 以上,这是怎么做到的呢?
今天,我们就一起来看看,现代 CPU 都使用了什么“黑科技”。
多发射与超标量:同一时间执行的两条指令
之前讲 CPU 的硬件组成的时候,我们把所有算术和逻辑运算都抽象出来,变成了一个 ALU 这样的“黑盒子”。你应该还记得第 13 讲到第 16 讲,关于加法器、乘法器、乃至浮点数计算的部分,其实整数的计算和浮点数的计算过程差异还是不小的。实际上,整数和浮点数计算的电路,在 CPU 层面也是分开的。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

现代CPU设计中的超标量和VLIW架构技术为提高CPU吞吐率带来了新的可能性。超标量技术通过并行取指令和指令译码,以及增加多个功能单元并行处理指令,实现了超过1的吞吐率。而VLIW架构则通过编译器在软件层面优化指令执行顺序,实现指令包并行执行。然而,Intel的安腾处理器由于指令集不兼容和扩展困难等问题,最终未能获得市场认可。这表明技术思路上的先进想法在实际应用中会遇到更多具体的实践考验。总体而言,本文深入浅出地介绍了CPU性能提升的技术挑战和失败案例,对于了解现代CPU设计和发展具有一定的参考价值。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《深入浅出计算机组成原理》,新⼈⾸单¥68
《深入浅出计算机组成原理》,新⼈⾸单¥68
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(33)
- 最新
- 精选
 fcb的鱼想知道在cpu里边是怎么并行执行的?一直觉得cpu是一个单线程的工作模式。
fcb的鱼想知道在cpu里边是怎么并行执行的?一直觉得cpu是一个单线程的工作模式。作者回复: fcb的鱼同学, 你好,多核CPU、流水线、超线程、Superscalar都是各种“并行”执行的方式呀,可以仔细读一下这几讲。
2020-02-057 活的潇洒“安腾失败的原因有很多,其中有一个重要的原因就是“向前兼容”。”现在终于明白安腾为什么失败了 day26 笔记:https://www.cnblogs.com/luoahong/p/11441329.html
活的潇洒“安腾失败的原因有很多,其中有一个重要的原因就是“向前兼容”。”现在终于明白安腾为什么失败了 day26 笔记:https://www.cnblogs.com/luoahong/p/11441329.html作者回复: 向前兼容是很多产品成功的原因,但也是很多产品慢慢衰败的原因。 Joel Spolsky曾经专门写过一篇文章讲关于这一点,拿的就是Excel怎么去和Lotus 1-2-3做竞争的例子 https://www.joelonsoftware.com/2000/06/03/strategy-letter-iii-let-me-go-back/
2019-09-0126 magicnum个人感觉VLIW架构下处理器乱序执行应该不需要了,因为编译器已经将可以并行执行的指令打包成了指令包;操作数前推和分支预测应该可以用吧?2019-06-2424
magicnum个人感觉VLIW架构下处理器乱序执行应该不需要了,因为编译器已经将可以并行执行的指令打包成了指令包;操作数前推和分支预测应该可以用吧?2019-06-2424 Linuxer一个时钟周期也只能执行完这样一条指令,CPI 只能是 1。但是,我们现在用的 Intel CPU 或者 ARM 的 CPU,一般的 CPI 都能做到 2 以上,这是怎么做到的呢?这里不是ipc?2019-06-24624
Linuxer一个时钟周期也只能执行完这样一条指令,CPI 只能是 1。但是,我们现在用的 Intel CPU 或者 ARM 的 CPU,一般的 CPI 都能做到 2 以上,这是怎么做到的呢?这里不是ipc?2019-06-24624- 钱勇不能叫VLIW的失败,只能说是EPIC的失败。 VLIW在配套专用编译器的专用芯片上,应用应该是有前途的。 只是不适合用在涉及到前后兼容的通用芯片上。2020-05-2716
 宋不肥这个本身就已经编译器是打乱顺序执行了吧。分支预测的话,相对于指令包的更多指令来讲,预测出错的话,清理缓存的开销应该会更大,但只要出错率*出错时的开销够小的话就应该依旧可行吧。操作数前推应该依旧可以用2019-06-246
宋不肥这个本身就已经编译器是打乱顺序执行了吧。分支预测的话,相对于指令包的更多指令来讲,预测出错的话,清理缓存的开销应该会更大,但只要出错率*出错时的开销够小的话就应该依旧可行吧。操作数前推应该依旧可以用2019-06-246 QianLu在《计算机组成与设计:硬件、软件接口(第三版中文)》中,“指令级并行”和“多发射”应是属于章节6.9。2020-02-254
QianLu在《计算机组成与设计:硬件、软件接口(第三版中文)》中,“指令级并行”和“多发射”应是属于章节6.9。2020-02-254- WENMURAN如何让CPU的吞吐率超过1? 经过前面对于各种冒险的操作,每个周期可以处理的指令只有1条,那么如何让这个数超过1? 解决:多发射,与超标量 一次从内存里取出多条指令,然后交给多个并行的指令译码器,然后交给对应的功能单元去处理。多发射,就是一次取多条指令进行译码执行,超标量,就是一个周期内同时有多条流水线并行工作。2020-04-192
 prader261 程序的执行时间= 指令数*CPI* 其中周期 2 为了进一步提升cpu的效率,引入了多发射和超标量(同时取多条指令,让多条流水线并行)。2019-09-222
prader261 程序的执行时间= 指令数*CPI* 其中周期 2 为了进一步提升cpu的效率,引入了多发射和超标量(同时取多条指令,让多条流水线并行)。2019-09-222- 范海良硬件层面是怎么检测依赖关系的?2022-03-0621
收起评论

