

45 | 机械硬盘:Google早期用过的“黑科技”

该思维导图由 AI 生成,仅供参考
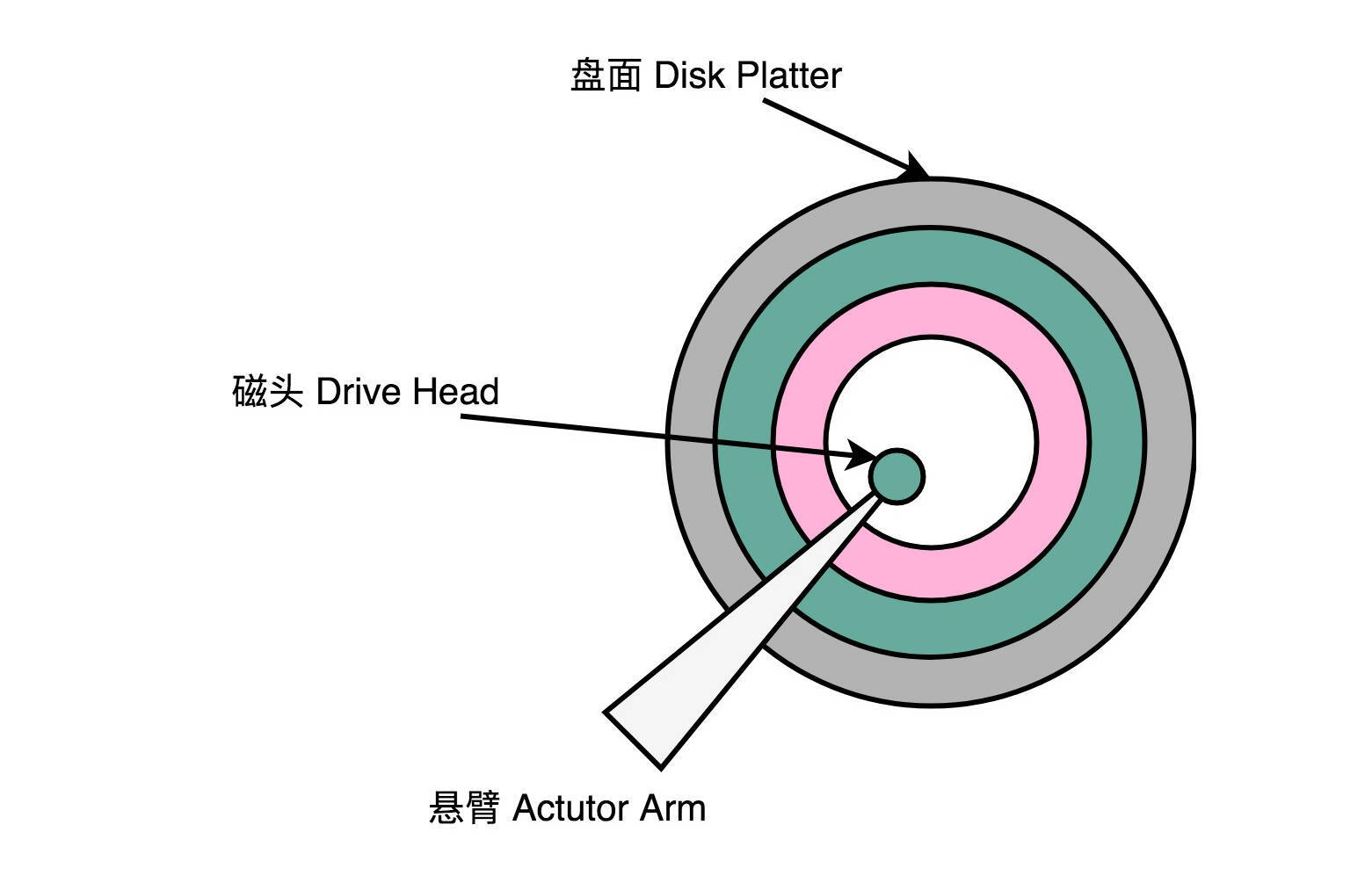
拆解机械硬盘
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

机械硬盘的性能优化方法Partial Stroking是本文的重点。文章首先介绍了机械硬盘的构成,包括盘面、磁头和悬臂。随后详细解释了数据的读取过程,包括盘面旋转和悬臂定位的时间计算。最后,文章提出了Partial Stroking技术,通过缩短寻道时间来提升硬盘的IOPS。通过这一技术,读者可以了解如何在没有SSD硬盘的情况下,通过软件优化提升机械硬盘的性能。整体而言,本文通过对机械硬盘的物理构造和工作原理进行深入解析,为读者提供了全面的了解和实用的技术指导。
《深入浅出计算机组成原理》,新⼈⾸单¥68

全部留言(32)
- 最新
- 精选

 penbox这个解决方案真的太妙了,简单有效又容易操作。有点编程珠玑里面的位图排序算法的感觉。 机械硬盘分区是由外到内的,C盘在最外侧依次类推,所以机械硬盘里面C盘的性能是所有分区里最好的。 要想只用最外侧1/4的磁道,只需要简单地把C盘分成整个硬盘1/4的容量,剩下的容量弃而不用就可以达到文章里面的效果了!
penbox这个解决方案真的太妙了,简单有效又容易操作。有点编程珠玑里面的位图排序算法的感觉。 机械硬盘分区是由外到内的,C盘在最外侧依次类推,所以机械硬盘里面C盘的性能是所有分区里最好的。 要想只用最外侧1/4的磁道,只需要简单地把C盘分成整个硬盘1/4的容量,剩下的容量弃而不用就可以达到文章里面的效果了!作者回复: 哈哈,的确是,第一次听到这种方式的时候我也觉得自己解决问题的思路不够奔放。
2019-08-12796 许童童老师,Partial Stroking技术不就是用空间换时间吗,原来计算机优化的本质都是一样的。 5400 转的硬盘,只使用一半的硬盘空间,我们的 IOPS 能够提升多少呢? 每分钟5400转,每秒可以转180个半圈,平均延时就是5.5ms 只使用一半硬盘空间,平均寻道时间就是9ms/2=4.5ms 总体IOPS就是1s / (5.5ms + 4.5ms) = 100 IOPS
许童童老师,Partial Stroking技术不就是用空间换时间吗,原来计算机优化的本质都是一样的。 5400 转的硬盘,只使用一半的硬盘空间,我们的 IOPS 能够提升多少呢? 每分钟5400转,每秒可以转180个半圈,平均延时就是5.5ms 只使用一半硬盘空间,平均寻道时间就是9ms/2=4.5ms 总体IOPS就是1s / (5.5ms + 4.5ms) = 100 IOPS作者回复: 许童童同学, 你好。Partial Stroking的确也是一种以空间换时间的技术。计算结果也是对的。👍
2019-08-0942 阿卡牛HDD 硬盘通常有个磁盘清理的操作,有什么用?
阿卡牛HDD 硬盘通常有个磁盘清理的操作,有什么用?作者回复: HDD硬盘常见又两种功能 1. 磁盘清理,这个主要是清除很多应用程序的临时文件和缓存。 2. 磁盘碎片整理,这个主要是尽量让数据在磁盘的物理位置上连续存放。这样新的输入写入以及旧的数据读取都会是以顺序读和顺序写的概率变大,能提升实际的性能表现。
2019-08-1216 雲至也许可以用另外一方法 就是多加几个磁头 每个负责一部分就快了 就好像几个人一块找东西
雲至也许可以用另外一方法 就是多加几个磁头 每个负责一部分就快了 就好像几个人一块找东西作者回复: 雲至同学, 你好,因为磁头是一个机械结构,要多几个磁头其实工程技术上的挑战更大。
2019-08-09411 山间竹文中“实践当中,我们可以只用 1/2 或者 1/4 的磁道,也就是最外面 1/4 或者 1/2 的磁道。这样,我们硬盘可以使用的容量可能变成了 1/2 或者 1/4。” 这个容量计算有误吧,现在硬盘大体实现了等密度了,不是正比例关系。
山间竹文中“实践当中,我们可以只用 1/2 或者 1/4 的磁道,也就是最外面 1/4 或者 1/2 的磁道。这样,我们硬盘可以使用的容量可能变成了 1/2 或者 1/4。” 这个容量计算有误吧,现在硬盘大体实现了等密度了,不是正比例关系。作者回复: 山间竹, 你好,等密度下,内圈空间比较小,但是理论上我们可以只用外圈,这样可以在缩短行程的情况下,使用更多的磁盘空间了。
2020-01-0523 Only now本科的操作系统课程上还有一个电梯算法, 操作系统对于无重叠的磁盘IO操作进行排序, 然后在单向的寻道行程里完成这些数据的访存。 就像电梯一样, 从1层到100层, 按一个顺序送所有乘客, 而不是先来先送让电梯往复运动。 个人感觉在高并发的数据中心上, 这个方案要比谷歌的做法更高效。
Only now本科的操作系统课程上还有一个电梯算法, 操作系统对于无重叠的磁盘IO操作进行排序, 然后在单向的寻道行程里完成这些数据的访存。 就像电梯一样, 从1层到100层, 按一个顺序送所有乘客, 而不是先来先送让电梯往复运动。 个人感觉在高并发的数据中心上, 这个方案要比谷歌的做法更高效。作者回复: Only now同学, 你好,这个思路的确也是一个可行的优化。但是在应用层没有局部性的随机读,还要有响应时间要求情况下,其实一样还会面临IOPS不够的问题。
2019-09-183 大明老师,是不是漏了一节了呢,dma,kafka为什么快。
大明老师,是不是漏了一节了呢,dma,kafka为什么快。作者回复: 大明同学, 你好,那个在第48讲,专栏的一些文章我在写的时候调整了一下先后顺序来保障逻辑线清晰。
2019-08-153 程序员花卷99IOPS左右,大概也就是100 草稿纸上算的,计算过程就不写了!不知道结果对不对
程序员花卷99IOPS左右,大概也就是100 草稿纸上算的,计算过程就不写了!不知道结果对不对作者回复: Hash同学, 你好,👍回答正确,可以和其他同学留言的计算过程做个对照
2019-12-252 活的潇洒老师,Partial Stroking技术不就是用空间换时间吗,按照老师的推算公式。 5400 转的硬盘,只使用一半的硬盘空间,我们的 IOPS 能够提升多少呢? 每分钟5400转,每秒可以转180个半圈,平均延时就是5.56ms 优化前 1000/(5.56+9)= 68.68 优化后 1000/(5.56+9/2)= 99.4 提升了 (99.4-68.68)/68.68*100=44.7%
活的潇洒老师,Partial Stroking技术不就是用空间换时间吗,按照老师的推算公式。 5400 转的硬盘,只使用一半的硬盘空间,我们的 IOPS 能够提升多少呢? 每分钟5400转,每秒可以转180个半圈,平均延时就是5.56ms 优化前 1000/(5.56+9)= 68.68 优化后 1000/(5.56+9/2)= 99.4 提升了 (99.4-68.68)/68.68*100=44.7%作者回复: 活得潇洒同学, 你好, 的确就是空间换时间,你的计算没错,👍。
2019-08-122- haer如果是用更慢的 5400 转的硬盘 平均延时: 1s / 180 = 5.56 ms 优化前: 1s / (5.56ms + 9ms) = 68.7 IOPS 优化后: 1s / (5.56ms + 9ms/2) = 99.4 IOPS
作者回复: 👍
2019-08-091

