

40 | 理解内存(上):虚拟内存和内存保护是什么?

该思维导图由 AI 生成,仅供参考
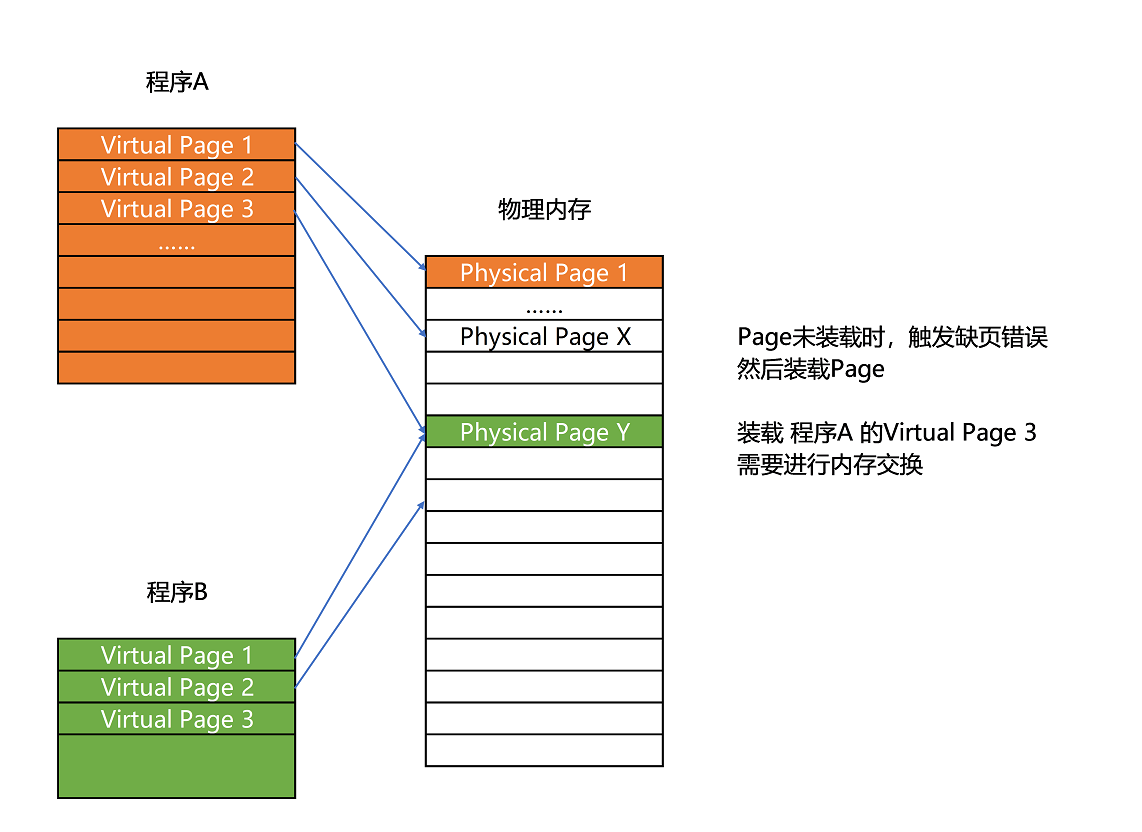
简单页表
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

计算机内存是计算机系统中至关重要的组成部分,程序需要加载到内存中才能被CPU执行。在Linux或Windows操作系统下,程序无法直接访问物理内存,而是通过虚拟内存地址转换成物理内存地址。这一过程通过页表实现,将虚拟内存地址映射到物理内存地址。传统的页表需要大量空间,因此引入了多级页表的解决方案,通过多级索引减少存储空间占用。尽管多级页表减少了存储空间,但增加了时间开销,需要多次访问内存。因此,文章提出了以时间换空间的策略,即多级页表。文章深入浅出地介绍了页表的基本概念和多级页表的原理,为读者解析了虚拟内存地址如何转换成物理内存地址的过程。 在优化页表的过程中,文章指出了数组和树这两种数据结构在时间复杂度和空间复杂度上的差异,以及理论软件的数据结构与硬件设计的高度相关性。此外,文章还推荐了进一步阅读材料,以及提出了课后思考问题,引发读者对多级页表和哈希表的优缺点进行思考。 总之,本文通过深入讲解页表的基本概念和多级页表的原理,为读者提供了对虚拟内存地址转换成物理内存地址的过程的全面理解,同时引发了读者对相关技术问题的思考和进一步学习的兴趣。
《深入浅出计算机组成原理》,新⼈⾸单¥68

全部留言(52)
- 最新
- 精选
 程序员花卷数据结构真的是无处不在啊! 哈希表是数组 + 链表组成的,充分的结合了数组和链表的优势,互补!但是哈希表存在哈希冲突,并且是无序的!不符合局部性原理!
程序员花卷数据结构真的是无处不在啊! 哈希表是数组 + 链表组成的,充分的结合了数组和链表的优势,互补!但是哈希表存在哈希冲突,并且是无序的!不符合局部性原理!作者回复: 👍,其实算法和数据结构在软硬件的开发的方方面面都会涉及到。
2019-12-247 zhe而一个 1 级索引表,32 个 4KiB 的也就是 16KB 的大小,这个怎么算的
zhe而一个 1 级索引表,32 个 4KiB 的也就是 16KB 的大小,这个怎么算的作者回复: zhe同学, 你好,谢谢纠正。这里写错了,我修正过来,是128KB。写的时候太快把4KiB当成了4K Bit了。
2019-08-196 焰火如果程序很大,两头实,中间也实,那么多级页表所占用的空间肯定比简单页表大得多吧? 进程的页表是操作系统进行统一管理的还是每个进程的装载器自我管理呢?
焰火如果程序很大,两头实,中间也实,那么多级页表所占用的空间肯定比简单页表大得多吧? 进程的页表是操作系统进行统一管理的还是每个进程的装载器自我管理呢?作者回复: 焰火同学, 你好,不太可能都实的,比如现在64位的计算机,内存空间是 2^64,没有哪个程序会需要那么多空间的。 进程的页表是由操作系统内核来创建管理的,Linux下也就是大家所谓的Kernel在管理。
2019-09-192 小先生一个页号是完整的 32 位的 4 字节(Byte) ------------------------------- 一个页号不是20位吗,为什么是32位呢??请问有人能回答一下吗??
小先生一个页号是完整的 32 位的 4 字节(Byte) ------------------------------- 一个页号不是20位吗,为什么是32位呢??请问有人能回答一下吗??作者回复: 小先生同学, 你好,页表有2^20个项,这个2^20可以认为是一个虚拟页号。但是物理页号其实是一个内存地址,一个32位的操作系统的一个内存地址就是32Bit也就是32位。
2019-09-232 红泥小火炉下一节是不是就出来tlb了
红泥小火炉下一节是不是就出来tlb了编辑回复: 是
2019-07-28- 鱼向北游哈希表有哈希冲突 并且顺序乱 不符合局部性原理 所以页表存储更复合计算机运行特点 64位系统的快表应该是对页表快速查询的一个优化吧 是用硬件实现么?期待老师下次讲解2019-07-27349
 华新找了半天终于搞明白为啥用多级页表可以节省内存空间了。总觉得加了四级占的空间更大了才对。 有跟我存在一样疑惑的可以参看以下地址,说的很明白: https://www.polarxiong.com/archives/%E5%A4%9A%E7%BA%A7%E9%A1%B5%E8%A1%A8%E5%A6%82%E4%BD%95%E8%8A%82%E7%BA%A6%E5%86%85%E5%AD%98.html2020-05-14735
华新找了半天终于搞明白为啥用多级页表可以节省内存空间了。总觉得加了四级占的空间更大了才对。 有跟我存在一样疑惑的可以参看以下地址,说的很明白: https://www.polarxiong.com/archives/%E5%A4%9A%E7%BA%A7%E9%A1%B5%E8%A1%A8%E5%A6%82%E4%BD%95%E8%8A%82%E7%BA%A6%E5%86%85%E5%AD%98.html2020-05-14735 -W.LI-我们可以一起来测算一下,一个进程如果占用了 1MB 的内存空间,分成了 2 个 512KB 的连续空间。那么,它一共需要 2 个独立的、填满的 2 级索引表,也就意味着 64 个 1 级索引表,2 个独立的 3 级索引表,1 个 4 级索引表。一共需要 69 个索引表,每个 128 字节,大概就是 9KB 的空间。比起 4MB 来说,只有差不多 1/500。 1个3级索引表,不是有32个2级索引表么? 为啥需要2个独立的3级索引表啊?2019-07-271723
-W.LI-我们可以一起来测算一下,一个进程如果占用了 1MB 的内存空间,分成了 2 个 512KB 的连续空间。那么,它一共需要 2 个独立的、填满的 2 级索引表,也就意味着 64 个 1 级索引表,2 个独立的 3 级索引表,1 个 4 级索引表。一共需要 69 个索引表,每个 128 字节,大概就是 9KB 的空间。比起 4MB 来说,只有差不多 1/500。 1个3级索引表,不是有32个2级索引表么? 为啥需要2个独立的3级索引表啊?2019-07-271723 业余爱好者多级页表感觉就是对大量地址的分组,如果组还是太多就接着分组,一直到一个组数规模适中的程度。查找时逐层进行。由于地址空间是个杠铃结构,很多分组就不需要了,这样就大大节省了内存空间。2020-06-209
业余爱好者多级页表感觉就是对大量地址的分组,如果组还是太多就接着分组,一直到一个组数规模适中的程度。查找时逐层进行。由于地址空间是个杠铃结构,很多分组就不需要了,这样就大大节省了内存空间。2020-06-209- 去777跟调表的思想有点像2020-03-1126

