

24 | 冒险和预测(三):CPU里的“线程池”
徐文浩

该思维导图由 AI 生成,仅供参考
过去两讲,我为你讲解了通过增加资源、停顿等待以及主动转发数据的方式,来解决结构冒险和数据冒险问题。对于结构冒险,由于限制来自于同一时钟周期不同的指令,要访问相同的硬件资源,解决方案是增加资源。对于数据冒险,由于限制来自于数据之间的各种依赖,我们可以提前把数据转发到下一个指令。
但是即便综合运用这三种技术,我们仍然会遇到不得不停下整个流水线,等待前面的指令完成的情况,也就是采用流水线停顿的解决方案。比如说,上一讲里最后给你的例子,即使我们进行了操作数前推,因为第二条加法指令依赖于第一条指令从内存中获取的数据,我们还是要插入一次 NOP 的操作。
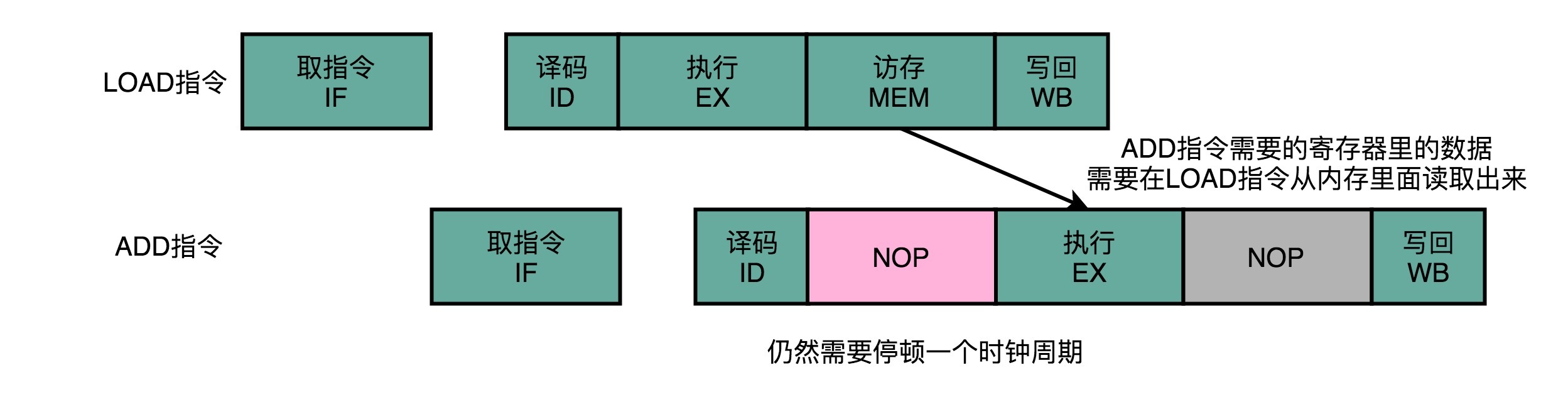
那这个时候你就会想了,那我们能不能让后面没有数据依赖的指令,在前面指令停顿的时候先执行呢?
答案当然是可以的。毕竟,流水线停顿的时候,对应的电路闲着也是闲着。那我们完全可以先完成后面指令的执行阶段。
填上空闲的 NOP:上菜的顺序不必是点菜的顺序
之前我为你讲解的,无论是流水线停顿,还是操作数前推,归根到底,只要前面指令的特定阶段还没有执行完成,后面的指令就会被“阻塞”住。
但是这个“阻塞”很多时候是没有必要的。因为尽管你的代码生成的指令是顺序的,但是如果后面的指令不需要依赖前面指令的执行结果,完全可以不必等待前面的指令运算完成。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文介绍了乱序执行技术在解决流水线阻塞问题中的重要性和应用。通过动态调度,乱序执行技术能够最大化CPU的吞吐率,充分利用CPU的性能和流水线的并发性。文章详细介绍了乱序执行的实现原理,包括指令分发到保留站、数据依赖等待、指令执行、结果重排序等过程。乱序执行技术提供了一个类似“线程池”的动态调度机制,极大地提高了CPU的运行效率。此外,文章还提到了现代Intel CPU的乱序执行过程中保障内存访问顺序的强内存模型,引发了读者对内存访问顺序保障的思考。总的来说,本文通过生动的比喻和图示,使读者能够快速了解乱序执行技术的原理和优势,为深入理解计算机组成原理奠定了基础。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《深入浅出计算机组成原理》,新⼈⾸单¥68
《深入浅出计算机组成原理》,新⼈⾸单¥68
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(46)
- 最新
- 精选
 88591应该是数据一致性问题,多核访问相同的内存。但是有自己的缓存,寄存器。
88591应该是数据一致性问题,多核访问相同的内存。但是有自己的缓存,寄存器。作者回复: 👍
2019-12-09251 许先森我的思考是上面的例子只是简单的计算,会不会是后面有一些逻辑运算对a和x的结果读取有顺序要求,如果不保证先正确读取a再正确读取到x的话会对逻辑运算有影响。
许先森我的思考是上面的例子只是简单的计算,会不会是后面有一些逻辑运算对a和x的结果读取有顺序要求,如果不保证先正确读取a再正确读取到x的话会对逻辑运算有影响。作者回复: 许先森同学, 会啊,所以需要有冒险检测,以及触发数据冒险,用NOP去填充一些流水线的位置,避免程序出错。
2020-01-14- 许先森“3. 这些指令不会立刻执行,而要等待它们所依赖的数据,传递给它们之后才会执行。这就好像一列列的火车都要等到乘客来齐了才能出发。” 这里有个问题啊,所有指令都是在保留站中等待自己依赖的数据,那如果依赖的是上一条指令的结果呢?
作者回复: 许先森同学, 你好,这个就是会触发数据冒险,把整个指令执行往后延。
2020-01-14  程序员花卷我觉得如果不保证它们的执行顺序的话,那最终得到的结果也可能不是我们期望的结果
程序员花卷我觉得如果不保证它们的执行顺序的话,那最终得到的结果也可能不是我们期望的结果作者回复: Hash同学, 你好,可以想一想具体在什么情况下,会不是我们预期的结果呢?
2019-12-182 Mango思考题,感觉是内存屏障,防止多核CPU操作共享内存时出现数据冒险问题。
Mango思考题,感觉是内存屏障,防止多核CPU操作共享内存时出现数据冒险问题。作者回复: Mango同学你好, 可以更具体一点么,离答案很接近了,但是我认为这个不能叫做“数据冒险”问题。
2019-08-28 焰火数据从cpu --> 寄存器 --> 内存, 数据从CPU到内存中间有个寄存器,寄存器和内存数据交换应该也是整页交换,如果不顺序写回寄存器的话,很有可能在寄存器页边界的时候,到内存发生时间差,导致后面寄存器再重新取内存的时候发生数据错误,之前数据不依赖,不保证后面数据不依赖。所以还是顺序写回比较安全。2019-07-19326
焰火数据从cpu --> 寄存器 --> 内存, 数据从CPU到内存中间有个寄存器,寄存器和内存数据交换应该也是整页交换,如果不顺序写回寄存器的话,很有可能在寄存器页边界的时候,到内存发生时间差,导致后面寄存器再重新取内存的时候发生数据错误,之前数据不依赖,不保证后面数据不依赖。所以还是顺序写回比较安全。2019-07-19326
 xindoo我觉得强内存模型是为了保证不同指令对同一内存地址的读写正确性,不同指令的执行不仅仅有寄存器数据依赖,还会有内存数据依赖。2019-06-19210
xindoo我觉得强内存模型是为了保证不同指令对同一内存地址的读写正确性,不同指令的执行不仅仅有寄存器数据依赖,还会有内存数据依赖。2019-06-19210 zhengfan徐老师您好。我有两个问题如下: 1. 乱序执行是否在debug模式下不启用?还是说reorder输出后,已经满足了单步执行下的顺序? 2. 乱序执行这样的优化是否对编码过程透明?换言之,编码过程中有意识的遵从乱序原则,是否会对运行效率有影响?个人感觉是会有影响的,至少在reserve和reorder两个阶段降低了排序难度。您认为呢?2020-04-224
zhengfan徐老师您好。我有两个问题如下: 1. 乱序执行是否在debug模式下不启用?还是说reorder输出后,已经满足了单步执行下的顺序? 2. 乱序执行这样的优化是否对编码过程透明?换言之,编码过程中有意识的遵从乱序原则,是否会对运行效率有影响?个人感觉是会有影响的,至少在reserve和reorder两个阶段降低了排序难度。您认为呢?2020-04-224 有米老师您好!乱序执行就是我们平时说的指令重排么?2020-03-1014
有米老师您好!乱序执行就是我们平时说的指令重排么?2020-03-1014 sun比如 两个线程分别在两个核中执行fun1(){int i1=1; int i2=i1+1; boolean b = true;)和fun2(){if(b) {System.out.println()i2}},假设 协会阶段不是顺序的,b=true被先写回缓存中,此时因为内存屏障,同步到主存中b位true,i2为0,另一个线程输出0,也就是说如果不保证最后的写回阶段有序,内存屏障也会失效?? 请问老师是这样吗?2020-04-012
sun比如 两个线程分别在两个核中执行fun1(){int i1=1; int i2=i1+1; boolean b = true;)和fun2(){if(b) {System.out.println()i2}},假设 协会阶段不是顺序的,b=true被先写回缓存中,此时因为内存屏障,同步到主存中b位true,i2为0,另一个线程输出0,也就是说如果不保证最后的写回阶段有序,内存屏障也会失效?? 请问老师是这样吗?2020-04-012
收起评论

