

39 | MESI协议:如何让多核CPU的高速缓存保持一致?

该思维导图由 AI 生成,仅供参考
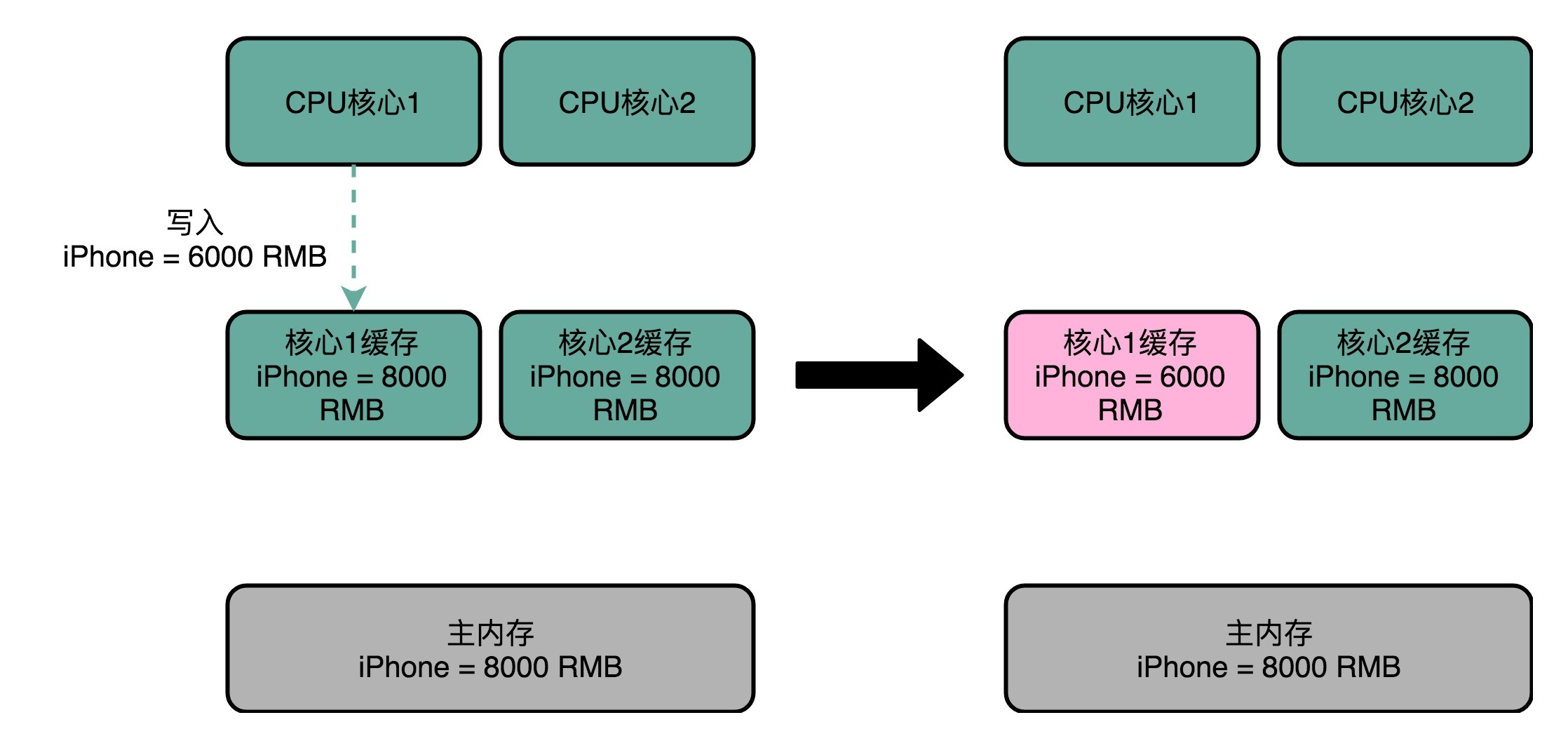
缓存一致性问题
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

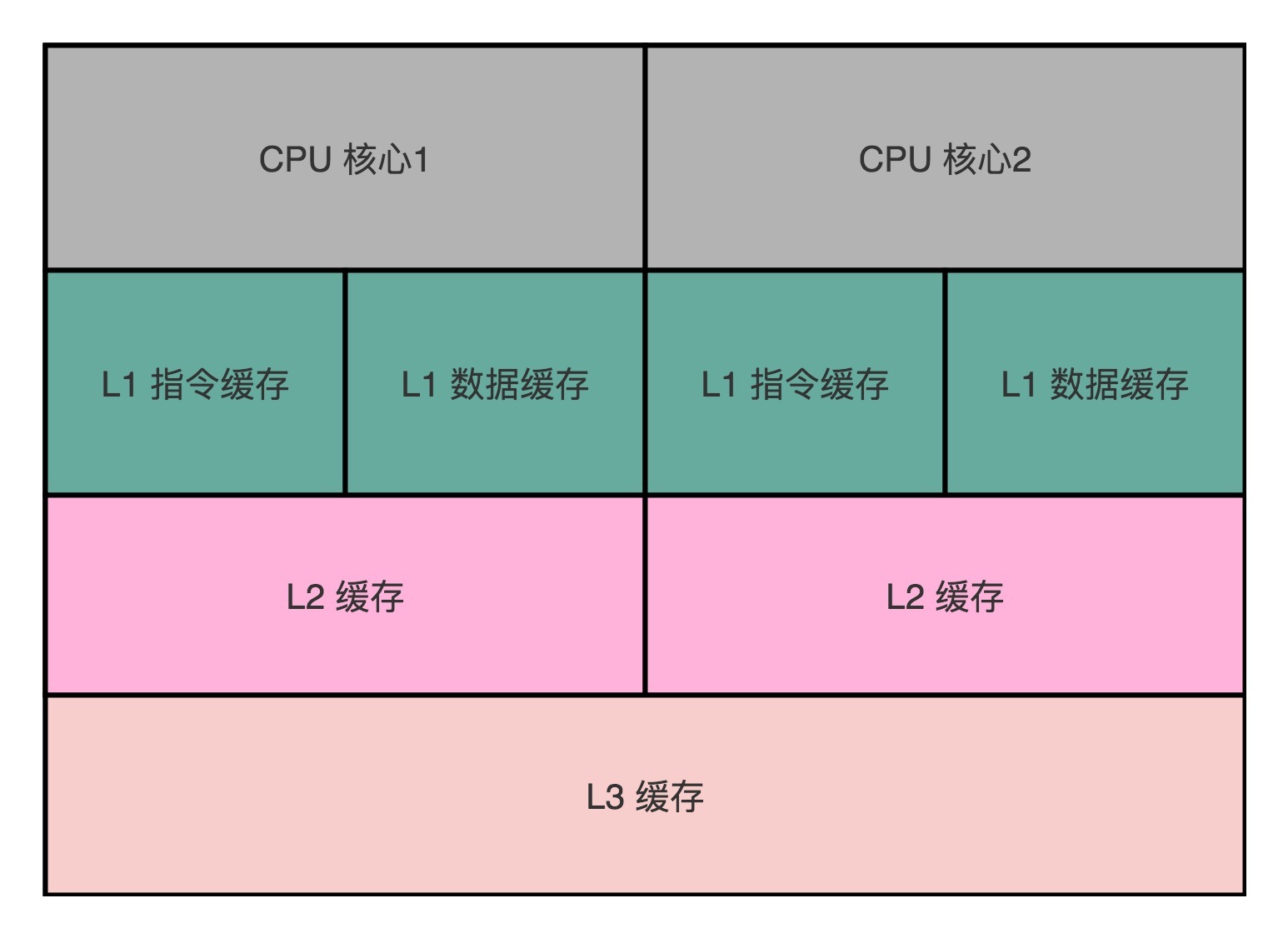
多核CPU的高速缓存一致性是一个重要的技术挑战。多核CPU的每个核心都有自己的缓存,这可能导致缓存不一致的问题。为了解决这个问题,需要实现写传播和事务的串行化。写传播确保数据更新能够传播到其他CPU核心的缓存中,而事务的串行化则要求不同核心看到的数据变化顺序是一致的。这种机制类似于数据库中的事务串行化,对于CPU Cache来说,需要实现同步通信和“锁”的概念。MESI协议是一种实现了这两个机制的解决方案。通过理解和实现缓存一致性,可以更好地利用多核CPU的优势,提升CPU的吞吐率。 文章介绍了多核CPU的缓存一致性问题以及解决方案。首先讲解了总线嗅探机制,通过总线广播读写请求给所有CPU核心,再根据本地情况进行响应,解决了多核CPU之间的数据传播问题。然后详细介绍了MESI协议,它是一种基于写失效的缓存一致性协议,通过已修改、独占、共享和已失效四种状态来管理缓存一致性。文章还提到MESI协议是对MSI协议的优化,通过搜索引擎可以了解两者的区别和优化。 总的来说,本文深入浅出地介绍了多核CPU的缓存一致性问题和MESI协议的解决方案,对于想要深入了解CPU缓存一致性的读者来说,是一篇值得阅读的文章。
《深入浅出计算机组成原理》,新⼈⾸单¥68

全部留言(57)
- 最新
- 精选
 山间竹既然有了MESI协议,是不是就不需要volatile的可见性语义了?当然不是,还有三个问题: 并不是所有的硬件架构都提供了相同的一致性保证,JVM需要volatile统一语义(就算是MESI,也只解决CPU缓存层面的问题,没有涉及其他层面)。 可见性问题不仅仅局限于CPU缓存内,JVM自己维护的内存模型中也有可见性问题。使用volatile做标记,可以解决JVM层面的可见性问题。 如果不考虑真·重排序,MESI确实解决了CPU缓存层面的可见性问题;然而,真·重排序也会导致可见性问题。
山间竹既然有了MESI协议,是不是就不需要volatile的可见性语义了?当然不是,还有三个问题: 并不是所有的硬件架构都提供了相同的一致性保证,JVM需要volatile统一语义(就算是MESI,也只解决CPU缓存层面的问题,没有涉及其他层面)。 可见性问题不仅仅局限于CPU缓存内,JVM自己维护的内存模型中也有可见性问题。使用volatile做标记,可以解决JVM层面的可见性问题。 如果不考虑真·重排序,MESI确实解决了CPU缓存层面的可见性问题;然而,真·重排序也会导致可见性问题。作者回复: 山间竹同学, 是的,JVM本质上是个抽象的“计算机硬件”,所以volatile对于JVM维护语义是有意义的,
2020-01-05519 fcb的鱼老师好,问下:在多核cpu里边,某个cpu更新了数据,再去广播其他cpu。怎么保证其他cpu一定是操作成功的呢?
fcb的鱼老师好,问下:在多核cpu里边,某个cpu更新了数据,再去广播其他cpu。怎么保证其他cpu一定是操作成功的呢?作者回复: fcb的鱼同学, 你好,这个是由“协议”来保证的。也就是其他CPU,在收到特定的广播消息,必须做什么样的特定操作。 只要“协议”是正确的,其他CPU操作之后的特定结果就会一致。那么,这个协议就是我们这里的MESI协议,你可以对照着下面的状态流转图看一下。 如果你问的是CPU在硬件层面,是否一个操作必定执行成功(好比你让程序算 1+1 = 2 是不是会算错),那这个是要在硬件的电路层面来保证的。在一个分层的软硬件体系下,这个不是MESI协议需要考虑的时间。
2020-02-063 炎发灼眼老师,有个问题,如果说一个核心更新了数据,广播失效操作和地址,其他核心的缓存被更新为失效,那更新数据的那个核心什么时候把数据再次写入内存呢,按照上一讲,在下次更新数据的时候才会写入,那如果在这个之间,别的核心需要用到这部分数据,看到失效,还是从内存读,这不是还是读不到最新的数据么。2019-07-262047
炎发灼眼老师,有个问题,如果说一个核心更新了数据,广播失效操作和地址,其他核心的缓存被更新为失效,那更新数据的那个核心什么时候把数据再次写入内存呢,按照上一讲,在下次更新数据的时候才会写入,那如果在这个之间,别的核心需要用到这部分数据,看到失效,还是从内存读,这不是还是读不到最新的数据么。2019-07-262047
 林三杠涉及到数据一致性的问题,cpu层,单机多线程内存层,分布式系统多台机器层,处理办法都差不多,原理是相通的2019-07-24328
林三杠涉及到数据一致性的问题,cpu层,单机多线程内存层,分布式系统多台机器层,处理办法都差不多,原理是相通的2019-07-24328 bro.Java中volatile变量修饰的共享变量在进行写操作时候会多出一行汇编** ``` 0x01a3de1d:movb $0×0,0×1104800(%esi);0x01a3de24:lock addl $0×0,(%esp); ``` lock前缀的指令在多核处理器下会: 1. 将当前处理器缓存行的数据写回到系统内存 2. 这个写回内存的操作会使其他CPU里缓存了改内存地址的数据无效 多处理器总线嗅探: 1. 为了提高处理速度,处理器不直接和内存进行通信,而是先将系统内存的数据读到内部缓存后在进行操作,但**写回操作**不知道这个更改何时回写到内存 2. 但是对变量使用volatile进行写操作时,JVM就会向处理器发送一条lock前缀的指令,将这个变量所在的缓存行的数据写回到系统内存 3. 在多处理器中,为了保证各个处理器的缓存一致性,每个处理器通过嗅探在总线上传播的数据来检查自己的缓存值是不是过期了,如果处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置为无效状态,就相当于**写回时发现状态标识为0失效**,当这个处理器对数据进行修改操作时,会重新从系统内存中读取数据到CPU缓存中2019-07-31117
bro.Java中volatile变量修饰的共享变量在进行写操作时候会多出一行汇编** ``` 0x01a3de1d:movb $0×0,0×1104800(%esi);0x01a3de24:lock addl $0×0,(%esp); ``` lock前缀的指令在多核处理器下会: 1. 将当前处理器缓存行的数据写回到系统内存 2. 这个写回内存的操作会使其他CPU里缓存了改内存地址的数据无效 多处理器总线嗅探: 1. 为了提高处理速度,处理器不直接和内存进行通信,而是先将系统内存的数据读到内部缓存后在进行操作,但**写回操作**不知道这个更改何时回写到内存 2. 但是对变量使用volatile进行写操作时,JVM就会向处理器发送一条lock前缀的指令,将这个变量所在的缓存行的数据写回到系统内存 3. 在多处理器中,为了保证各个处理器的缓存一致性,每个处理器通过嗅探在总线上传播的数据来检查自己的缓存值是不是过期了,如果处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置为无效状态,就相当于**写回时发现状态标识为0失效**,当这个处理器对数据进行修改操作时,会重新从系统内存中读取数据到CPU缓存中2019-07-31117 许童童MSI 缓存一致性协议没有E这个状态,也就是没有独享的状态。 如果块尚未被装入缓存(处于“I”状态),则在装入该块之前,必须先要保证该地址的数据不会在其他缓存的缓存块中处于“M”状态。如果另一个缓存中有处于“M”状态的块,则它必须将数据写回后备存储,并回到“S”状态。 MESI 多了E状态(独享状态),如果当前写入的是E,则可直接写入,提高了性能。2019-07-2416
许童童MSI 缓存一致性协议没有E这个状态,也就是没有独享的状态。 如果块尚未被装入缓存(处于“I”状态),则在装入该块之前,必须先要保证该地址的数据不会在其他缓存的缓存块中处于“M”状态。如果另一个缓存中有处于“M”状态的块,则它必须将数据写回后备存储,并回到“S”状态。 MESI 多了E状态(独享状态),如果当前写入的是E,则可直接写入,提高了性能。2019-07-2416 。。。老师我想问下:mesi默认一直运行的, 还是说加了lock才会采用锁总线或者msei协议2020-03-027
。。。老师我想问下:mesi默认一直运行的, 还是说加了lock才会采用锁总线或者msei协议2020-03-027 DarrenMESI 协议对于“锁”的实现是机制是RFO(Request For Ownership),也就是获取当前对应 Cache Block 数据的所有权吗? 如果是的话,多核cpu下,同时RFO会发生死锁呀,还有你RFO结束后,还没有执行完指令去更新缓存行,但是别的cpu又发起RFO了,此时感觉还是不安全的呀?是不是我理解的不对?期望老师和大神帮忙解答下,🙏2020-06-1214
DarrenMESI 协议对于“锁”的实现是机制是RFO(Request For Ownership),也就是获取当前对应 Cache Block 数据的所有权吗? 如果是的话,多核cpu下,同时RFO会发生死锁呀,还有你RFO结束后,还没有执行完指令去更新缓存行,但是别的cpu又发起RFO了,此时感觉还是不安全的呀?是不是我理解的不对?期望老师和大神帮忙解答下,🙏2020-06-1214 随心而至我编译了volatile相关的代码,在Win10 64位下,将java代码转换成字节码,再转换成机器码,发现是由lock cmpxchg两个指令实现的。2019-10-2224
随心而至我编译了volatile相关的代码,在Win10 64位下,将java代码转换成字节码,再转换成机器码,发现是由lock cmpxchg两个指令实现的。2019-10-2224 慎独明强对于MESI协议,当对一个值进行修改时,会需要通过总线广播给其他核,这个时候是需要进行等待其他核响应,这里会有性能的差异吧。记得看过一些资料,有通过写寄存器和无效队列来进行优化,但是优化又会出现可见性和有序问题。最后底层是通过内存屏障来解决加入写寄存器和无效队列的可见性和有序性问题,希望老师能讲下这块2021-03-082
慎独明强对于MESI协议,当对一个值进行修改时,会需要通过总线广播给其他核,这个时候是需要进行等待其他核响应,这里会有性能的差异吧。记得看过一些资料,有通过写寄存器和无效队列来进行优化,但是优化又会出现可见性和有序问题。最后底层是通过内存屏障来解决加入写寄存器和无效队列的可见性和有序性问题,希望老师能讲下这块2021-03-082

