

36 | 局部性原理:数据库性能跟不上,加个缓存就好了?
徐文浩

该思维导图由 AI 生成,仅供参考
平时进行服务端软件开发的时候,我们通常会把数据存储在数据库里。而服务端系统遇到的第一个性能瓶颈,往往就发生在访问数据库的时候。这个时候,大部分工程师和架构师会拿出一种叫作“缓存”的武器,通过使用 Redis 或者 Memcache 这样的开源软件,在数据库前面提供一层缓存的数据,来缓解数据库面临的压力,提升服务端的程序性能。
在数据库前添加数据缓存是常见的性能优化方式
那么,不知道你有没有想过,这种添加缓存的策略一定是有效的吗?或者说,这种策略在什么情况下是有效的呢?如果从理论角度去分析,添加缓存一定是我们的最佳策略么?进一步地,如果我们对于访问性能的要求非常高,希望数据在 1 毫秒,乃至 100 微秒内完成处理,我们还能用这个添加缓存的策略么?
理解局部性原理
我们先来回顾一下,上一讲的这张不同存储器的性能和价目表。可以看到,不同的存储器设备之间,访问速度、价格和容量都有几十乃至上千倍的差异。
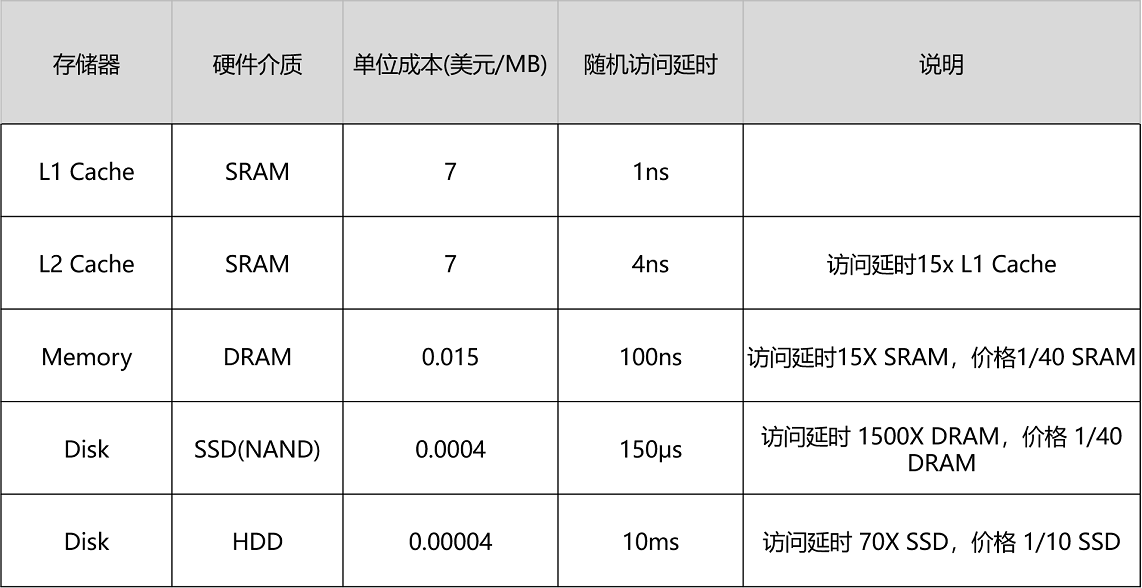
以上一讲的 Intel 8265U 的 CPU 为例,它的 L1 Cache 只有 256K,L2 Cache 有个 1MB,L3 Cache 有 12MB。一共 13MB 的存储空间,如果按照 7 美元 /1MB 的价格计算,就要 91 美元。
我们的内存有 8GB,容量是 CPU Cache 的 600 多倍,按照表上的价格差不多就是 120 美元。如果按照今天京东上的价格,恐怕不到 40 美元。128G 的 SSD 和 1T 的 HDD,现在的价格加起来也不会超过 100 美元。虽然容量是内存的 16 倍乃至 128 倍,但是它们的访问速度却不到内存的 1/1000。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

通过本文了解了数据库性能优化中的关键技术——局部性原理。文章以亚马逊电商网站为例,深入探讨了如何利用时间局部性和空间局部性来优化数据存储和访问策略。通过合理组合不同层次的存储器,可以在满足高访问性能要求的情况下,以最低的成本提供所需的数据存储、管理和访问需求。作者通过实际案例和理论分析,阐述了如何进行存储器的硬件规划,以及如何估算服务器负载和规划硬件设备。总结指出,对于架构师和工程师来说,掌握“估算+规划”的能力是必不可少的。文章还强调了局部性原理在应用开发中使用缓存的重要性,以及如何通过快速估算来判断缓存策略是否能够满足需求。最后,文章提到了推荐阅读和课后思考,鼓励读者深入学习和思考相关技术问题。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《深入浅出计算机组成原理》,新⼈⾸单¥68
《深入浅出计算机组成原理》,新⼈⾸单¥68
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(32)
- 最新
- 精选
 阿斯蒂芬老师举的这个亚马逊商品缓存的例子,我理解就是利用了时间局部性的特征,一个商品如果被访问了,那么猜测很快会被第二次访问。我再尝试理解空间局部性,也拿老师说的《哈利波特》全集的例子,如果《哈1》被访问了,那么《哈2-7》被访问的可能性也很高,因此这也可以作为缓存预热的一种策略,类似地我还想到了电商经常用的“看相似”和“看过这个的同时也喜欢...”这一类推荐,细想一下背后也是一种“空间局部性”的应用,在后台基于大数据做离线分析,生成内容相关推荐,可以在适当时候优先加载到更快速的存储上以达到更快的响应。当然,可能实际上是否会优先加载不一定,但是透过老师的讲解,把这块联系上了计算机组成原理的理论,还是觉得嗨森,哈哈哈。
阿斯蒂芬老师举的这个亚马逊商品缓存的例子,我理解就是利用了时间局部性的特征,一个商品如果被访问了,那么猜测很快会被第二次访问。我再尝试理解空间局部性,也拿老师说的《哈利波特》全集的例子,如果《哈1》被访问了,那么《哈2-7》被访问的可能性也很高,因此这也可以作为缓存预热的一种策略,类似地我还想到了电商经常用的“看相似”和“看过这个的同时也喜欢...”这一类推荐,细想一下背后也是一种“空间局部性”的应用,在后台基于大数据做离线分析,生成内容相关推荐,可以在适当时候优先加载到更快速的存储上以达到更快的响应。当然,可能实际上是否会优先加载不一定,但是透过老师的讲解,把这块联系上了计算机组成原理的理论,还是觉得嗨森,哈哈哈。作者回复: 👍
2020-01-0228 ........
........ 老师, 感觉硬盘应该还是需要能够完全支撑用户访问, 因为一开始数据应该都是存放在硬盘中, 然后通过用户的不断点击来更新缓存? 不知道是不是这样
老师, 感觉硬盘应该还是需要能够完全支撑用户访问, 因为一开始数据应该都是存放在硬盘中, 然后通过用户的不断点击来更新缓存? 不知道是不是这样作者回复: 是这样的。但是一般我们可以做缓存预热,也就是warm-up,预先把我们认为可能会高频访问的数据先加载到缓存里面来。
2019-09-307 leslie其实这还是一个负载均衡的问题:如何合理的使用内存库;就如同现在某些行业的数据库其实是定时入数据库的,效率的平衡性确实;物理设备代价的平衡性,程序、数据库、中间件的使用平衡性,需要整体考虑。
leslie其实这还是一个负载均衡的问题:如何合理的使用内存库;就如同现在某些行业的数据库其实是定时入数据库的,效率的平衡性确实;物理设备代价的平衡性,程序、数据库、中间件的使用平衡性,需要整体考虑。作者回复: leslie同学, 你好,这是一个trade-off的问题,是一个选择、平衡、妥协的问题,但是不是一个负载均衡的问题哦
2019-08-225 -_-|||文中“一块 HDD 硬盘只能支撑每秒 100 次的随机访问,2400TB 的数据,以 4TB 一块磁盘来计算,有 600 块磁盘,也就是能支撑每秒 6 万次( = 2400TB/4TB × 1s/10ms )的随机访问”,600 块磁盘构成了一个集群吗
-_-|||文中“一块 HDD 硬盘只能支撑每秒 100 次的随机访问,2400TB 的数据,以 4TB 一块磁盘来计算,有 600 块磁盘,也就是能支撑每秒 6 万次( = 2400TB/4TB × 1s/10ms )的随机访问”,600 块磁盘构成了一个集群吗作者回复: -_-_aaa同学, 你好,并不一定是一个集群,通常很多服务器,一个主板上可以有8块乃至12块硬盘的接口用50台服务器提供服务就可以了。
2020-01-182 吴宇晨感觉还能加一层ssd缓存,内存和ssd差价太大速度也差很多,可以内存存千分一,ssd存百分一
吴宇晨感觉还能加一层ssd缓存,内存和ssd差价太大速度也差很多,可以内存存千分一,ssd存百分一作者回复: 吴宇晨同学, 你好,是的,SSD在今天是一个更好的选择。而且因为SSD不是易失性存储设备,而且价格也大幅度下降了。现在大家都直接用作存储了,而不是用来作为缓存设备了。
2019-08-282 Jag现在通常加一个redis ,在加一个本地缓存,来帮数据库分担压力
Jag现在通常加一个redis ,在加一个本地缓存,来帮数据库分担压力作者回复: Jag同学, 你好,在这一讲里,我们已经用上了本地缓存。你可以尝试估算一下淘宝的数据量,看看到底要用多少机器才能装得下这么多数据呢?
2019-08-22
 xindoo局部性原理真是计算机各类优化的基石,小到cpu cache,大到cdn。而且不仅仅是存储,java的jit也是利于局部性优化性能。任何东西只要不是均匀分布的,就有优化空间。2019-07-174121
xindoo局部性原理真是计算机各类优化的基石,小到cpu cache,大到cdn。而且不仅仅是存储,java的jit也是利于局部性优化性能。任何东西只要不是均匀分布的,就有优化空间。2019-07-174121 许童童假设淘宝网有12亿商品数量,每件商品需要 4MB 的存储空间,那么一共需要 4800TB( = 12 亿 × 4MB)的数据存储 如果1%的热点数据做为缓存则需要48TB的内存 72 万美元( = 48TB/1MB × 0.015 美元 = 72 万美元) 另外还需要99%的硬盘 19 万美元( = 4752TB/1MB × 0.00004 美元 = 19 万美元)2019-07-17231
许童童假设淘宝网有12亿商品数量,每件商品需要 4MB 的存储空间,那么一共需要 4800TB( = 12 亿 × 4MB)的数据存储 如果1%的热点数据做为缓存则需要48TB的内存 72 万美元( = 48TB/1MB × 0.015 美元 = 72 万美元) 另外还需要99%的硬盘 19 万美元( = 4752TB/1MB × 0.00004 美元 = 19 万美元)2019-07-17231 恺撒之剑亚马逊的例子估算问题 现在普通硬盘的吞吐量在100MB/s左右,按4MB每个商品计算,硬盘每秒的访问次数为100 / 4 = 25次 ,而不是按照IOPS的角度 1s/10ms = 100次 硬盘不但受IOPS的限制,也受吞吐量的限制,文中的估算没有考虑吞吐量,只考虑的IOPS2020-05-129
恺撒之剑亚马逊的例子估算问题 现在普通硬盘的吞吐量在100MB/s左右,按4MB每个商品计算,硬盘每秒的访问次数为100 / 4 = 25次 ,而不是按照IOPS的角度 1s/10ms = 100次 硬盘不但受IOPS的限制,也受吞吐量的限制,文中的估算没有考虑吞吐量,只考虑的IOPS2020-05-129 随心而至我记得编程珠玑有一章中,专门考察了估算能力,老师关于亚马逊的估算真的是很赞。2019-10-229
随心而至我记得编程珠玑有一章中,专门考察了估算能力,老师关于亚马逊的估算真的是很赞。2019-10-229
收起评论

