

25 | 红黑树(上):为什么工程中都用红黑树这种二叉树?
该思维导图由 AI 生成,仅供参考
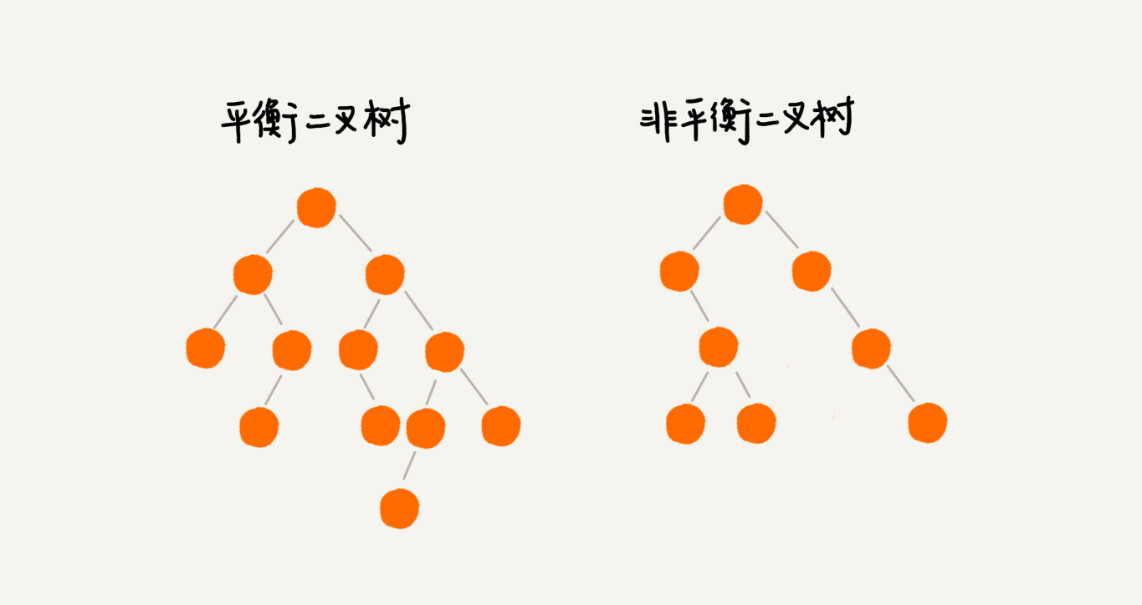
什么是“平衡二叉查找树”?
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

红黑树是一种重要的平衡二叉查找树,用于解决二叉查找树在频繁动态更新时可能出现的性能退化问题。其定义包括根节点为黑色、叶子节点为黑色空节点、相邻节点不能同时为红色、每个节点到达叶子节点的路径包含相同数目的黑色节点等规则。红黑树的高度近似于2log2n,仅比高度平衡的AVL树的高度(log2n)多一倍,性能下降并不多。因此,红黑树被广泛应用于工程中,以提高插入、删除、查找等操作的效率。相比于AVL树,红黑树的维护平衡成本较低,使得其在工程应用中更受青睐。红黑树是一种性能稳定的平衡二叉查找树,适用于动态数据操作的场景。文章还介绍了平衡二叉查找树的概念和红黑树的定义,以及红黑树的近似平衡性质。虽然红黑树的实现较为复杂,但掌握其由来、特性、适用场景和解决问题的能力即可。文章还提到了红黑树与其他动态数据结构的对比,以及红黑树在工程中的应用和实现难度。
《数据结构与算法之美》,新⼈⾸单¥68

全部留言(138)
- 最新
- 精选
 Smallfly动态数据结构的动态是什么意思? 动态是指在运行时该数据结构所占的内存会扩大或缩小。 数组是一种静态的数据结构,在创建时内存大小已经确定,不管有没有插入数据。而链表是动态的数据结构,插入数据 alloc 内存,删除数据 release 内存。 栈、队列、散列表、跳表、树都是抽象的数据结构,它们在内存中存在的形式都要依赖于数组或者链表。 如果用链表实现,很明显它们是动态的数据结构;如果用数组实现,那么在扩容的时候会创建更大内存的数组,原数组被废弃,从抽象角度看,它们仍旧是动态的。
Smallfly动态数据结构的动态是什么意思? 动态是指在运行时该数据结构所占的内存会扩大或缩小。 数组是一种静态的数据结构,在创建时内存大小已经确定,不管有没有插入数据。而链表是动态的数据结构,插入数据 alloc 内存,删除数据 release 内存。 栈、队列、散列表、跳表、树都是抽象的数据结构,它们在内存中存在的形式都要依赖于数组或者链表。 如果用链表实现,很明显它们是动态的数据结构;如果用数组实现,那么在扩容的时候会创建更大内存的数组,原数组被废弃,从抽象角度看,它们仍旧是动态的。作者回复: 我看smallfly大牛好像对动态数据结构有些误解,可能其他同学也会有。所以,我解释一下:动态数据结构是支持动态的更新操作,里面存储的数据是时刻在变化的,通俗一点讲,它不仅仅支持查询,还支持删除、插入数据。而且,这些操作都非常高效。如果不高效,也就算不上是有效的动态数据结构了。所以,这里的红黑树算一个,支持动态的插入、删除、查找,而且效率都很高。链表、队列、栈实际上算不上,因为操作非常有限,查询效率不高。那现在你再想一下还有哪些支持动态插入、删除、查找数据并且效率都很高的的数据结构呢??
2018-11-166136 失火的夏天动态数据结构有链表,栈,队列,哈希表等等。链表适合遍历的场景,插入和删除操作方便,栈和队列可以算一种特殊的链表,分别适用先进后出和先进先出的场景。哈希表适合插入和删除比较少(尽量少的扩容和缩容),查找比较多的时候。红黑树对数据要求有序,对数据增删查都有一定要求的时候。(个人看法,欢迎老师指正)
失火的夏天动态数据结构有链表,栈,队列,哈希表等等。链表适合遍历的场景,插入和删除操作方便,栈和队列可以算一种特殊的链表,分别适用先进后出和先进先出的场景。哈希表适合插入和删除比较少(尽量少的扩容和缩容),查找比较多的时候。红黑树对数据要求有序,对数据增删查都有一定要求的时候。(个人看法,欢迎老师指正)作者回复: 👍 刚看错了。写的不错
2018-11-1641- null红黑树的节点颜色,是如何确定的,如何知道在新增一个节点时,该节点是什么颜色? 从红黑树需要满足的四个要求来看: 1. 根节点为黑色 2. 所有叶子节点为黑色,且不存储数据 3. 相邻两个节点不能都为红色 4. 从某节点到其所有叶子节点的路径中,黑色节点数相同 从这四点要求,好像我一根树全是黑色,也是满足其定义的。这里用红黑两色区分各节点,意义是啥? 谢谢老师
作者回复: 新插入的节点都是红色的。全黑不可能的。红黑区分的意义你等下一节课看看能懂不
2018-11-16315 - increasingly请问什么是单次操作时间非常敏感的场景呢
作者回复: 比如有些系统只关注操作的平均执行时间,大部分操作都很快,比如1s,极个别操作可能花费很多时间10s,但平均下来,整体上都很快,所以也能接受。 但是有的系统不仅仅关注平均执行时间,对单次操作的时间非常敏感,极个别的10s操作也是无法接受的。
2019-02-2111  Laughing_Lz老师,你这里提到:我画了两个红黑树的图例,你可以对照着看下。 这下面的两张图,左边第一个,四个叶子节点都是红色呀?我有点看不懂。。 规则不是说叶子节点都是不存储数据的黑色空节点吗?这里是不是画错了? 如果你是说省略了黑色叶子节点,那就是说这四个红色节点下其实还有叶子节点?但是这样又不能满足规则四:每个节点,从该节点到达其可达叶子节点的所有路径,都包含相同数目的黑色节点...除非第三层的第三个黑色子节点下也有叶子节点?
Laughing_Lz老师,你这里提到:我画了两个红黑树的图例,你可以对照着看下。 这下面的两张图,左边第一个,四个叶子节点都是红色呀?我有点看不懂。。 规则不是说叶子节点都是不存储数据的黑色空节点吗?这里是不是画错了? 如果你是说省略了黑色叶子节点,那就是说这四个红色节点下其实还有叶子节点?但是这样又不能满足规则四:每个节点,从该节点到达其可达叶子节点的所有路径,都包含相同数目的黑色节点...除非第三层的第三个黑色子节点下也有叶子节点?作者回复: 是的 都会有nil的黑色叶子节点的
2018-12-022 复兴红黑树是链表还是数组存储的呢
复兴红黑树是链表还是数组存储的呢作者回复: 都不是啊,是树
2019-09-291 TryTs老师你之前说过的成就感固然是吧!但是我觉得我的挫败感更大.....可能是我想一蹴而就了吧……还有我想请问一下老师你觉得比较有创意的计算机领域有哪些?
TryTs老师你之前说过的成就感固然是吧!但是我觉得我的挫败感更大.....可能是我想一蹴而就了吧……还有我想请问一下老师你觉得比较有创意的计算机领域有哪些?作者回复: 区块链?人工智能?
2018-11-211 Northern红黑树的两个图例中,第一张图看不太懂,为什么叶子节点都是红色?这不符合红黑树的定义
Northern红黑树的两个图例中,第一张图看不太懂,为什么叶子节点都是红色?这不符合红黑树的定义作者回复: 麻烦仔细读读文章 我前面有讲的
2018-12-10 qinggeouye红黑树的第三点要求:「任何相邻的节点都不能同时为红色」,这里是否可以理解为子节点和它的父节点不能同时为空色? 本节第三幅图例的第二个红黑树,一开始对着平衡二叉树查找树的严格定义,发现左右子树的高度相差并不小于等于 1,但是又想到「近似」的含义,一下就释怀了。
qinggeouye红黑树的第三点要求:「任何相邻的节点都不能同时为红色」,这里是否可以理解为子节点和它的父节点不能同时为空色? 本节第三幅图例的第二个红黑树,一开始对着平衡二叉树查找树的严格定义,发现左右子树的高度相差并不小于等于 1,但是又想到「近似」的含义,一下就释怀了。作者回复: 第一个问题 是的
2018-12-02 鹏程万里请问文中的这段话:“前面红黑树的定义里有这么一条:从任意节点到可达的叶子节点的每个路径包含相同数目的黑色节点。我们从四叉树中取出某些节点,放到叶节点位置,四叉树就变成了完全二叉树。所以,仅包含黑色节点的四叉树的高度,比包含相同节点个数的完全二叉树的高度还要小”-----这段话想表达的意思是仅包含黑色结点的四叉树的高度比相同结点个数的完全二叉树的高度小吗?那么这句话“从任意节点到可达的叶子节点的每个路径包含相同数目的黑色节点”想表达什么意思呢?是要把四叉树转换为满二叉树再去比较吗?
鹏程万里请问文中的这段话:“前面红黑树的定义里有这么一条:从任意节点到可达的叶子节点的每个路径包含相同数目的黑色节点。我们从四叉树中取出某些节点,放到叶节点位置,四叉树就变成了完全二叉树。所以,仅包含黑色节点的四叉树的高度,比包含相同节点个数的完全二叉树的高度还要小”-----这段话想表达的意思是仅包含黑色结点的四叉树的高度比相同结点个数的完全二叉树的高度小吗?那么这句话“从任意节点到可达的叶子节点的每个路径包含相同数目的黑色节点”想表达什么意思呢?是要把四叉树转换为满二叉树再去比较吗?作者回复: 第一个问题答案是yes 另外两个问的太笼统 没看懂
2018-11-19

