

05 | 数组:为什么很多编程语言中数组都从0开始编号?
该思维导图由 AI 生成,仅供参考
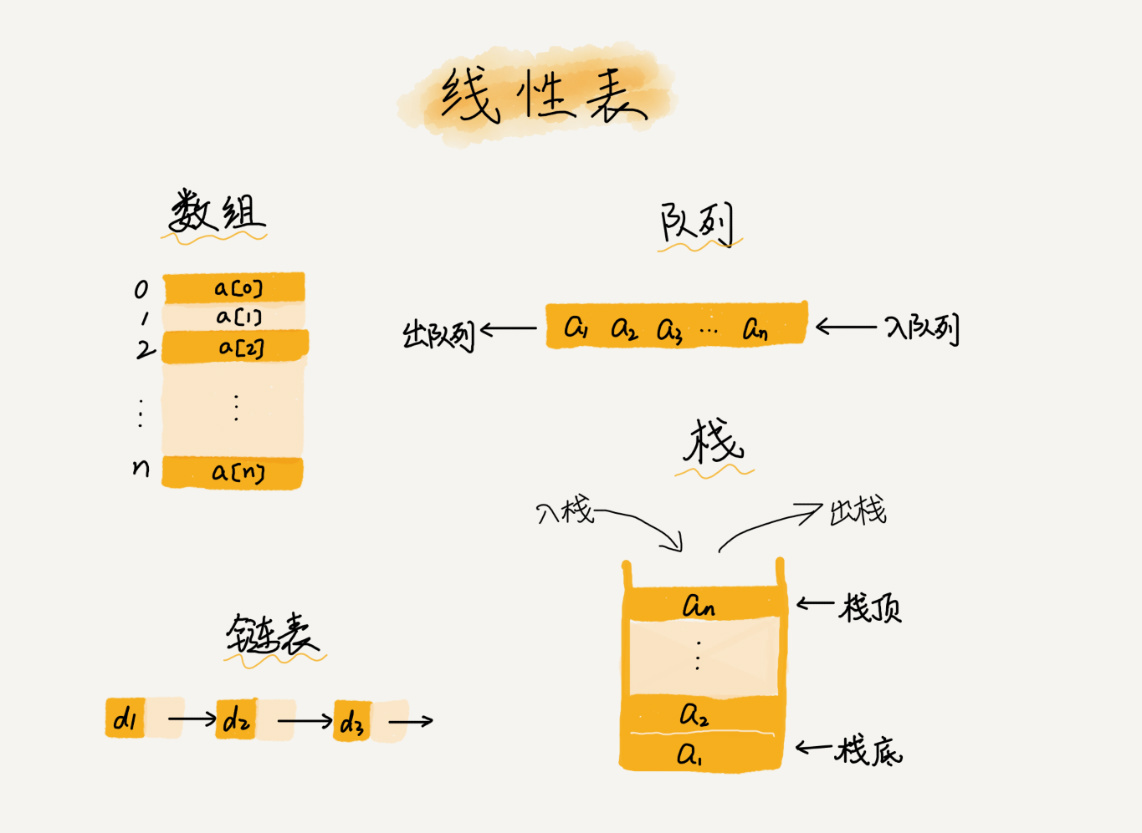
如何实现随机访问?
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

数组是编程语言中常见的数据类型,也是最基础的数据结构之一。本文解释了为什么很多编程语言中数组从0开始编号,以及数组的实现原理和操作效率。文章首先介绍了数组的定义和特性,包括线性表结构和随机访问的实现原理。然后详细讨论了数组中插入和删除操作的低效性,并提出了一些改进方法。最后,通过实例说明了如何优化删除操作的效率。文章强调了对数组背后思想和处理技巧的理解,以及算法和数据结构在软件开发和架构设计中的重要性。 文章还提到了数组访问越界问题,以及容器是否能完全替代数组的讨论。对于数组从0开始编号的原因,文章解释了从内存模型和效率角度出发,为了减少一次减法操作,数组选择了从0开始编号。同时,也提到了历史原因和不同语言的实现差异。 总的来说,数组作为最基础、最简单的数据结构,支持随机访问,但插入、删除操作效率较低。在业务开发中,可以直接使用编程语言提供的容器类,但在特别底层的开发中,直接使用数组可能更合适。 文章还提出了课后思考问题,包括JVM的标记清除垃圾回收算法和二维数组的内存寻址公式,为读者提供了进一步思考和学习的机会。 综上所述,本文通过深入讨论数组的特性、实现原理和效率问题,为读者提供了对数组及其在软件开发中的应用的全面了解。
《数据结构与算法之美》,新⼈⾸单¥68

全部留言(1091)
- 最新
- 精选
 杰杰置顶JVM标记清除算法: 大多数主流虚拟机采用可达性分析算法来判断对象是否存活,在标记阶段,会遍历所有 GC ROOTS,将所有 GC ROOTS 可达的对象标记为存活。只有当标记工作完成后,清理工作才会开始。 不足:1.效率问题。标记和清理效率都不高,但是当知道只有少量垃圾产生时会很高效。2.空间问题。会产生不连续的内存空间碎片。 二维数组内存寻址: 对于 m * n 的数组,a [ i ][ j ] (i < m,j < n)的地址为: address = base_address + ( i * n + j) * type_size 另外,对于数组访问越界造成无限循环,我理解是编译器的问题,对于不同的编译器,在内存分配时,会按照内存地址递增或递减的方式进行分配。老师的程序,如果是内存地址递减的方式,就会造成无限循环。 不知我的解答和理解是否正确,望老师解答?
杰杰置顶JVM标记清除算法: 大多数主流虚拟机采用可达性分析算法来判断对象是否存活,在标记阶段,会遍历所有 GC ROOTS,将所有 GC ROOTS 可达的对象标记为存活。只有当标记工作完成后,清理工作才会开始。 不足:1.效率问题。标记和清理效率都不高,但是当知道只有少量垃圾产生时会很高效。2.空间问题。会产生不连续的内存空间碎片。 二维数组内存寻址: 对于 m * n 的数组,a [ i ][ j ] (i < m,j < n)的地址为: address = base_address + ( i * n + j) * type_size 另外,对于数组访问越界造成无限循环,我理解是编译器的问题,对于不同的编译器,在内存分配时,会按照内存地址递增或递减的方式进行分配。老师的程序,如果是内存地址递减的方式,就会造成无限循环。 不知我的解答和理解是否正确,望老师解答?作者回复: 完全正确✅
2018-10-01711665 slvher对文中示例的无限循环有疑问的同学,建议去查函数调用的栈桢结构细节(操作系统或计算机体系结构的教材应该会讲到)。 函数体内的局部变量存在栈上,且是连续压栈。在Linux进程的内存布局中,栈区在高地址空间,从高向低增长。变量i和arr在相邻地址,且i比arr的地址大,所以arr越界正好访问到i。当然,前提是i和arr元素同类型,否则那段代码仍是未决行为。
slvher对文中示例的无限循环有疑问的同学,建议去查函数调用的栈桢结构细节(操作系统或计算机体系结构的教材应该会讲到)。 函数体内的局部变量存在栈上,且是连续压栈。在Linux进程的内存布局中,栈区在高地址空间,从高向低增长。变量i和arr在相邻地址,且i比arr的地址大,所以arr越界正好访问到i。当然,前提是i和arr元素同类型,否则那段代码仍是未决行为。作者回复: 👍 高手!
2018-10-01441887 不诉离殇例子中死循环的问题跟编译器分配内存和字节对齐有关 数组3个元素 加上一个变量a 。4个整数刚好能满足8字节对齐 所以i的地址恰好跟着a2后面 导致死循环。。如果数组本身有4个元素 则这里不会出现死循环。。因为编译器64位操作系统下 默认会进行8字节对齐 变量i的地址就不紧跟着数组后面了。
不诉离殇例子中死循环的问题跟编译器分配内存和字节对齐有关 数组3个元素 加上一个变量a 。4个整数刚好能满足8字节对齐 所以i的地址恰好跟着a2后面 导致死循环。。如果数组本身有4个元素 则这里不会出现死循环。。因为编译器64位操作系统下 默认会进行8字节对齐 变量i的地址就不紧跟着数组后面了。作者回复: 高手!
2018-10-0123716 zyzheng关于数组越界访问导致死循环的问题,我也动手实践了一下,发现结果和编译器的实现有关,gcc有一个编译选项(-fno-stack-protector)用于关闭堆栈保护功能。默认情况下启动了堆栈保护,不管i声明在前还是在后,i都会在数组之后压栈,只会循环4次;如果关闭堆栈保护功能,则会出现死循环。请参考:https://www.ibm.com/developerworks/cn/linux/l-cn-gccstack/index.html
zyzheng关于数组越界访问导致死循环的问题,我也动手实践了一下,发现结果和编译器的实现有关,gcc有一个编译选项(-fno-stack-protector)用于关闭堆栈保护功能。默认情况下启动了堆栈保护,不管i声明在前还是在后,i都会在数组之后压栈,只会循环4次;如果关闭堆栈保护功能,则会出现死循环。请参考:https://www.ibm.com/developerworks/cn/linux/l-cn-gccstack/index.html作者回复: 就喜欢你这种自己动手研究的同学
2018-10-0325465 Zzzzz对于死循环那个问题,要了解栈这个东西。栈是向下增长的,首先压栈的i,a[2],a[1],a[0],这是我在我vc上调试查看汇编的时候看到的压栈顺序。相当于访问a[3]的时候,是在访问i变量,而此时i变量的地址是数组当前进程的,所以进行修改的时候,操作系统并不会终止进程。
Zzzzz对于死循环那个问题,要了解栈这个东西。栈是向下增长的,首先压栈的i,a[2],a[1],a[0],这是我在我vc上调试查看汇编的时候看到的压栈顺序。相当于访问a[3]的时候,是在访问i变量,而此时i变量的地址是数组当前进程的,所以进行修改的时候,操作系统并不会终止进程。作者回复: 👍
2018-10-0113179 shane无限循环的问题,我认为内存分配是从后往前分配的。例如,在Excel中从上往下拉4个格子,变量i会先被分配到第4个格子的内存,然后变量arr往上数分配3个格子的内存,但arr的数据是从分配3个格子的第一个格子从上往下存储数据的,当访问第3索引时,这时刚好访问到第4个格子变量i的内存。 不知道对不对,望指正!
shane无限循环的问题,我认为内存分配是从后往前分配的。例如,在Excel中从上往下拉4个格子,变量i会先被分配到第4个格子的内存,然后变量arr往上数分配3个格子的内存,但arr的数据是从分配3个格子的第一个格子从上往下存储数据的,当访问第3索引时,这时刚好访问到第4个格子变量i的内存。 不知道对不对,望指正!作者回复: 形象👍
2018-10-018105 李朋远老师,您好,个人觉得您举例的内存越界的循环应该限制在x86架构的小端模式,在别的架构平台上的大端模式应该不是这样的!
李朋远老师,您好,个人觉得您举例的内存越界的循环应该限制在x86架构的小端模式,在别的架构平台上的大端模式应该不是这样的!作者回复: 说的没错 👍
2018-10-03692 hope根据我们前面讲的数组寻址公式,a[3] 也会被定位到某块不属于数组的内存地址上,而这个地址正好是存储变量 i 的内存地址,那么 a[3]=0 就相当于 i=0,所以就会导致代码无限循环。 这块不是十分清晰,希望老师详细解答一下,谢谢! 看完了 ,之前说总结但是没总结,这次前连天的总结也补上了,打卡
hope根据我们前面讲的数组寻址公式,a[3] 也会被定位到某块不属于数组的内存地址上,而这个地址正好是存储变量 i 的内存地址,那么 a[3]=0 就相当于 i=0,所以就会导致代码无限循环。 这块不是十分清晰,希望老师详细解答一下,谢谢! 看完了 ,之前说总结但是没总结,这次前连天的总结也补上了,打卡作者回复: 1. 不同的语言对数组访问越界的处理方式不同,即便是同一种语言,不同的编译器处理的方式也不同。至于你熟悉的语言是怎么处理的,请行百度。 2. C语言中,数组访问越界的处理是未决。并不一定是错,有同学做实验说没问题,那并不代表就是正确的。 3. 我觉得那个例子,栈是由高到低位增长的,所以,i和数组的数据从高位地址到低位地址依次是:i, a[2], a[1], a[0]。a[3]通过寻址公式,计算得到地址正好是i的存储地址,所以a[3]=0,就相当于i=0. 4. 大家有不懂的多看看留言,留言区还是有很多大牛的!我可能有时候回复的不及时,或者同样的问题只回复一个同学!
2018-10-01675 港1. 我认为文中更准确的说法可能是标记-整理垃圾回收算法。标记-清除算法在垃圾收集时会先标记出需要回收的对象,标记完成后统一回收所有被标记的对象。清除之后会产生大量不连续的内存碎片。标记-整理垃圾回收算法在标记完成之后让所有存活的对象都向一端移动,然后直接清理掉边界以外的内存。 2. 假设二维数组大小为m*n,那么寻址公式为 a[i][j]_address = base_address + (i * n+j)*data_type_size 3. C语言变量的内存申请可以看做是地址按照从大到小连续申请的,因为i在arr前面申请,所以arr[3]的地址和i的地址相同。 例如对于如下代码: int i = 0;int j = 1;int k = 2; int arr[3] = {0}; cout<<"i-"<<&i<<endl; cout<<"j-"<<&j<<endl; cout<<"k-"<<&k<<endl; cout<<"arr-"<<&arr<<endl; cout<<"arr3-"<<&arr[3]<<endl; 运行结果: i-0x28ff0c j-0x28ff08 k-0x28ff04 arr-0x28fef8 arr3-0x28ff04
港1. 我认为文中更准确的说法可能是标记-整理垃圾回收算法。标记-清除算法在垃圾收集时会先标记出需要回收的对象,标记完成后统一回收所有被标记的对象。清除之后会产生大量不连续的内存碎片。标记-整理垃圾回收算法在标记完成之后让所有存活的对象都向一端移动,然后直接清理掉边界以外的内存。 2. 假设二维数组大小为m*n,那么寻址公式为 a[i][j]_address = base_address + (i * n+j)*data_type_size 3. C语言变量的内存申请可以看做是地址按照从大到小连续申请的,因为i在arr前面申请,所以arr[3]的地址和i的地址相同。 例如对于如下代码: int i = 0;int j = 1;int k = 2; int arr[3] = {0}; cout<<"i-"<<&i<<endl; cout<<"j-"<<&j<<endl; cout<<"k-"<<&k<<endl; cout<<"arr-"<<&arr<<endl; cout<<"arr3-"<<&arr[3]<<endl; 运行结果: i-0x28ff0c j-0x28ff08 k-0x28ff04 arr-0x28fef8 arr3-0x28ff04作者回复: 👍
2018-10-0365 Monday以问题为思路学习本节(国庆10天假,加来完成当初立下的flag,求支持鼓励) 一、引子:为什么很多编程语言的数组都是从0开始编号的? 1、从数组存储的内存模型上来看,“下标”确切的说法就是一种“偏移”,相比从1开始编号,从0开始编号会少一次减法运算,数组作为非常基础的数组结构,通过下标随机访问元素又是非常基础的操作,效率的优化就要尽可能的做到极致。 2、主要的原因是历史原因,C语言的设计者是从0开始计数数组下标的,之后的Java、JS等语言都进行了效仿,或者说是为了减少从C转向Java、JS等的学习成本。 二、什么是数组? 数组是一个线性数据结构,用一组连续的内存空间存储一组具有相同类型的数据。 其实数组、链表、栈、队列都是线性表结构;树、图则是非线性表结构。 三、数组和链表的面试纠错? 1、数组中的元素存在一个连续的内存空间中,而链表中的元素可以不存在于连续的内存空间。 2、数组支持随机访问,根据下标随机访问的时间复杂度是O(1);链表适合插入、删除操作,时间复杂度为O(1)。 四、容器是否完全替代数组? 容器的优势:对于Java语言,容器封装了数组插入、删除等操作的细节,并且支持动态扩容。 对于Java,一些更适合用数组的场景: 1、Java的ArrayList无法存储基本类型,需要进行装箱操作,而装箱与拆箱操作都会有一定的性能消耗,如果特别注意性能,或者希望使用基本类型,就可以选用数组。 2、若数组大小事先已知,并且对数组只有非常简单的操作,不需要使用到ArrayList提供的大部分方法,则可以直接使用数组。 3、多维数组时,使用数组会更加直观。 五、JVM标记清除算法? GC最基础的收集算法就是标记-清除算法,如同他们的名字一样,此算法分为“标记”、“清除”两个阶段,先标记出需要回收的对象,再统一回收标记的对象。不足有二,一是效率不高,二是产生碎片内存空间。 六、数组的内存寻址公式? 一维数组:a[i]_address=base_address+i*type_size 二维数组:二维数组假设是m*n, a[i][j]_address=base_address + (i*n+j)*type_size 三维数组:三维数组假设是m*n*q, a[i][j][k]_address=base_address + (i*n*q + j*q + k)*type_size 若理解有误,欢迎指正,谢谢!
Monday以问题为思路学习本节(国庆10天假,加来完成当初立下的flag,求支持鼓励) 一、引子:为什么很多编程语言的数组都是从0开始编号的? 1、从数组存储的内存模型上来看,“下标”确切的说法就是一种“偏移”,相比从1开始编号,从0开始编号会少一次减法运算,数组作为非常基础的数组结构,通过下标随机访问元素又是非常基础的操作,效率的优化就要尽可能的做到极致。 2、主要的原因是历史原因,C语言的设计者是从0开始计数数组下标的,之后的Java、JS等语言都进行了效仿,或者说是为了减少从C转向Java、JS等的学习成本。 二、什么是数组? 数组是一个线性数据结构,用一组连续的内存空间存储一组具有相同类型的数据。 其实数组、链表、栈、队列都是线性表结构;树、图则是非线性表结构。 三、数组和链表的面试纠错? 1、数组中的元素存在一个连续的内存空间中,而链表中的元素可以不存在于连续的内存空间。 2、数组支持随机访问,根据下标随机访问的时间复杂度是O(1);链表适合插入、删除操作,时间复杂度为O(1)。 四、容器是否完全替代数组? 容器的优势:对于Java语言,容器封装了数组插入、删除等操作的细节,并且支持动态扩容。 对于Java,一些更适合用数组的场景: 1、Java的ArrayList无法存储基本类型,需要进行装箱操作,而装箱与拆箱操作都会有一定的性能消耗,如果特别注意性能,或者希望使用基本类型,就可以选用数组。 2、若数组大小事先已知,并且对数组只有非常简单的操作,不需要使用到ArrayList提供的大部分方法,则可以直接使用数组。 3、多维数组时,使用数组会更加直观。 五、JVM标记清除算法? GC最基础的收集算法就是标记-清除算法,如同他们的名字一样,此算法分为“标记”、“清除”两个阶段,先标记出需要回收的对象,再统一回收标记的对象。不足有二,一是效率不高,二是产生碎片内存空间。 六、数组的内存寻址公式? 一维数组:a[i]_address=base_address+i*type_size 二维数组:二维数组假设是m*n, a[i][j]_address=base_address + (i*n+j)*type_size 三维数组:三维数组假设是m*n*q, a[i][j][k]_address=base_address + (i*n*q + j*q + k)*type_size 若理解有误,欢迎指正,谢谢!作者回复: 👍
2018-10-1034

