

14 | 排序优化:如何实现一个通用的、高性能的排序函数?
王争

该思维导图由 AI 生成,仅供参考
几乎所有的编程语言都会提供排序函数,比如 C 语言中 qsort(),C++ STL 中的 sort()、stable_sort(),还有 Java 语言中的 Collections.sort()。在平时的开发中,我们也都是直接使用这些现成的函数来实现业务逻辑中的排序功能。那你知道这些排序函数是如何实现的吗?底层都利用了哪种排序算法呢?
基于这些问题,今天我们就来看排序这部分的最后一块内容:如何实现一个通用的、高性能的排序函数?
如何选择合适的排序算法?
如果要实现一个通用的、高效率的排序函数,我们应该选择哪种排序算法?我们先回顾一下前面讲过的几种排序算法。
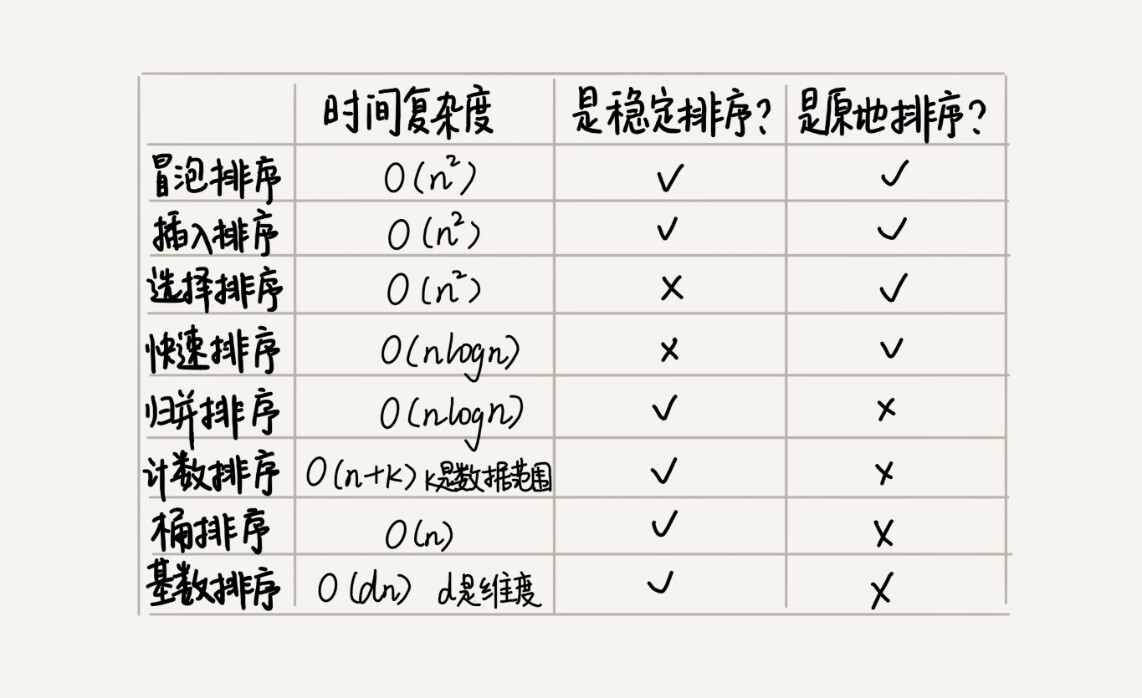
我们前面讲过,线性排序算法的时间复杂度比较低,适用场景比较特殊。所以如果要写一个通用的排序函数,不能选择线性排序算法。
如果对小规模数据进行排序,可以选择时间复杂度是 O(n2) 的算法;如果对大规模数据进行排序,时间复杂度是 O(nlogn) 的算法更加高效。所以,为了兼顾任意规模数据的排序,一般都会首选时间复杂度是 O(nlogn) 的排序算法来实现排序函数。
时间复杂度是 O(nlogn) 的排序算法不止一个,我们已经讲过的有归并排序、快速排序,后面讲堆的时候我们还会讲到堆排序。堆排序和快速排序都有比较多的应用,比如 Java 语言采用堆排序实现排序函数,C 语言使用快速排序实现排序函数。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了如何实现一个通用的、高性能的排序函数。首先介绍了选择合适的排序算法的重要性,强调了时间复杂度为O(nlogn)的算法更适合实现通用排序函数。随后,对快速排序进行了优化讨论,提出了三数取中法和随机法两种常用的分区算法,以及避免堆栈溢出的解决办法。文章还分析了C语言中的qsort()函数的底层实现原理,展示了其选择排序算法和优化策略的思路。通过举例分析,读者能够更直观地了解排序函数的实现和优化过程。整体而言,本文内容贴近实战,贯穿了一些前面几节的内容,对于开发人员实现高性能排序函数具有指导意义。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《数据结构与算法之美》,新⼈⾸单¥68
《数据结构与算法之美》,新⼈⾸单¥68
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(147)
- 最新
- 精选
 Jerry银银说说我觉得文章可能存在的一个问题,再借此问题,正好回答下思考题! ---------------------- 文章中有一段话,如下: "时间复杂度是 O(nlogn) 的排序算法不止一个,我们已经讲过的有归并排序、快速排序,后面讲堆的时候我们还会讲到堆排序。堆排序和快速排序都有比较多的应用,比如 Java 语言采用堆排序实现排序函数,C 语言使用快速排序实现排序函数。" 这里说,”Java语言采用堆排序实现排序函数“,这句话是不是错误的? 在JDK中,排序相关的主要是两个工具类:Arrays.java 和 Collections.java,具体的排序方法是sort()。这里要注意的是,Collections.java中的sort()方法是将List转为数组,然后调用Arrays.sort()方法进行排序,具体代码如下(留言中代码格式可能有点混乱,讲究看看,也可以自行参看List.sort()): default void sort(Comparator<? super E> c) { Object[] a = this.toArray(); Arrays.sort(a, (Comparator) c); ListIterator<E> i = this.listIterator(); for (Object e : a) { i.next(); i.set((E) e); } } 在Arrays类中,sort()有一系列的重载方法,罗列几个典型的Arrays.sort()方法如下: public static void sort(int[] a) { DualPivotQuicksort.sort(a, 0, a.length - 1, null, 0, 0); } public static void sort(long[] a) { DualPivotQuicksort.sort(a, 0, a.length - 1, null, 0, 0); } public static void sort(Object[] a) { if (LegacyMergeSort.userRequested) legacyMergeSort(a); else ComparableTimSort.sort(a, 0, a.length, null, 0, 0); } 重载方法虽然多,但是从“被排序的数组所存储的内容”这个维度可以将其分为两类: 1. 存储的数据类型是基本数据类型 2. 存储的数据类型是Object 第一种情况使用的是快排,在数据量很小的时候,使用的插入排序; 第二种情况使用的是归并排序,在数据量很小的时候,使用的也是插入排序 以上两种场景所用到的排序都是「混合式的排序」,也都是为了追求极致的性能而设计的。另外,第二种排序有个专业的名称,叫:TimSort(可以自行Wikipedia)
Jerry银银说说我觉得文章可能存在的一个问题,再借此问题,正好回答下思考题! ---------------------- 文章中有一段话,如下: "时间复杂度是 O(nlogn) 的排序算法不止一个,我们已经讲过的有归并排序、快速排序,后面讲堆的时候我们还会讲到堆排序。堆排序和快速排序都有比较多的应用,比如 Java 语言采用堆排序实现排序函数,C 语言使用快速排序实现排序函数。" 这里说,”Java语言采用堆排序实现排序函数“,这句话是不是错误的? 在JDK中,排序相关的主要是两个工具类:Arrays.java 和 Collections.java,具体的排序方法是sort()。这里要注意的是,Collections.java中的sort()方法是将List转为数组,然后调用Arrays.sort()方法进行排序,具体代码如下(留言中代码格式可能有点混乱,讲究看看,也可以自行参看List.sort()): default void sort(Comparator<? super E> c) { Object[] a = this.toArray(); Arrays.sort(a, (Comparator) c); ListIterator<E> i = this.listIterator(); for (Object e : a) { i.next(); i.set((E) e); } } 在Arrays类中,sort()有一系列的重载方法,罗列几个典型的Arrays.sort()方法如下: public static void sort(int[] a) { DualPivotQuicksort.sort(a, 0, a.length - 1, null, 0, 0); } public static void sort(long[] a) { DualPivotQuicksort.sort(a, 0, a.length - 1, null, 0, 0); } public static void sort(Object[] a) { if (LegacyMergeSort.userRequested) legacyMergeSort(a); else ComparableTimSort.sort(a, 0, a.length, null, 0, 0); } 重载方法虽然多,但是从“被排序的数组所存储的内容”这个维度可以将其分为两类: 1. 存储的数据类型是基本数据类型 2. 存储的数据类型是Object 第一种情况使用的是快排,在数据量很小的时候,使用的插入排序; 第二种情况使用的是归并排序,在数据量很小的时候,使用的也是插入排序 以上两种场景所用到的排序都是「混合式的排序」,也都是为了追求极致的性能而设计的。另外,第二种排序有个专业的名称,叫:TimSort(可以自行Wikipedia)作者回复: 👍 细心,新版本的jdk估计有优化吧,可以从代码中发现: if (LegacyMergeSort.userRequested) legacyMergeSort(a); legacy的实现确实是堆排序!
2019-03-021196 Andrew 陈震老师,我有一个问题,关于递归太深导致堆栈溢出的问题。对于这个问题,您说一般有两种解决方法,一是设置最深的层数,如果超过层数了,就报错。对于这样的问题,我想排序一个数列,超过了层数,难道就不排了么?我看有留言说,stl中的sort默认是使用快排的,但当递归深度过大时 会转为使用归并排序。但是归并排序也是递归排序啊,如果两种排序都达到了最深层数怎么处理?另外,在排序之前,能否估算出排序是否超过最深层数呢?如果估算不出,那岂不是要先排一遍,发现超过层数,再换用别的。我的想法是设个阈值,不超过阈值,用一种,超过了,用另一种。 第二种应对堆栈溢出的方法是通过在堆上模拟实现一个函数调用栈,手动模拟递归压栈、出栈的过程。这个方法在您的几篇教程里都提到过,但是不详细,您能否稍微详细讲解一下。 谢谢老师
Andrew 陈震老师,我有一个问题,关于递归太深导致堆栈溢出的问题。对于这个问题,您说一般有两种解决方法,一是设置最深的层数,如果超过层数了,就报错。对于这样的问题,我想排序一个数列,超过了层数,难道就不排了么?我看有留言说,stl中的sort默认是使用快排的,但当递归深度过大时 会转为使用归并排序。但是归并排序也是递归排序啊,如果两种排序都达到了最深层数怎么处理?另外,在排序之前,能否估算出排序是否超过最深层数呢?如果估算不出,那岂不是要先排一遍,发现超过层数,再换用别的。我的想法是设个阈值,不超过阈值,用一种,超过了,用另一种。 第二种应对堆栈溢出的方法是通过在堆上模拟实现一个函数调用栈,手动模拟递归压栈、出栈的过程。这个方法在您的几篇教程里都提到过,但是不详细,您能否稍微详细讲解一下。 谢谢老师作者回复: 太深报错也没问题 不过不建议这么处理 归并排序比较稳定 栈的深度是logn 非常小 所以不会堆栈溢出 关于手动模拟栈 你可以看看qsort()函数的实现
2018-10-22347 蛐鸣看了一下,.NET里面的Array排序实现: 1. 三个以内的,直接比较,交换进行实现 2.大于3个小于16个的,用的是插入排序进行的实现 3.对于大于16,并且深度限制是0的,用的是堆排序实现的 4.对于大于15,并且深度限制不是0的,使用的是快速排序;然后快速排序分区使用的也是三数取中法
蛐鸣看了一下,.NET里面的Array排序实现: 1. 三个以内的,直接比较,交换进行实现 2.大于3个小于16个的,用的是插入排序进行的实现 3.对于大于16,并且深度限制是0的,用的是堆排序实现的 4.对于大于15,并且深度限制不是0的,使用的是快速排序;然后快速排序分区使用的也是三数取中法作者回复: 👍
2018-11-02240 城qsort中为避免递归调用过深,所以在堆上模拟了栈。不知道是否是将递归调用,改写为循环非递归方式呢?
城qsort中为避免递归调用过深,所以在堆上模拟了栈。不知道是否是将递归调用,改写为循环非递归方式呢?作者回复: 是的
2018-10-22219 雨天使用快排如何解决不稳定排序的问题?
雨天使用快排如何解决不稳定排序的问题?作者回复: 并没解决 所以qsort不稳定
2018-10-2213 落叶飞逝的恋老师,你好,我终于认真消化完了前面的知识,没有半点马虎,也给自己打个卡记录。 关于思考题: 查看了Java的Arrays.sort 1.若数组元素个数总数小于47,使用插入排序 2.若数据元素个数总数在47~286之间,使用快速排序。应该是使用的优化版本的三值取中的优化版本。 3.若大于286的个数,使用归并排序。 底层实现的代码比之前示范写的代码校验多,所以目前只能看到这,下面继续加油吧!
落叶飞逝的恋老师,你好,我终于认真消化完了前面的知识,没有半点马虎,也给自己打个卡记录。 关于思考题: 查看了Java的Arrays.sort 1.若数组元素个数总数小于47,使用插入排序 2.若数据元素个数总数在47~286之间,使用快速排序。应该是使用的优化版本的三值取中的优化版本。 3.若大于286的个数,使用归并排序。 底层实现的代码比之前示范写的代码校验多,所以目前只能看到这,下面继续加油吧!作者回复: 👍
2018-12-04412 favorlm
favorlm 虽然说思考很重要,但是面试还是需要你实现一种算法。
虽然说思考很重要,但是面试还是需要你实现一种算法。作者回复: 留言区点赞最高的就是答案
2018-11-0411 helloworld2018老师好,请教个问题,快排不是稳定算法,为啥还要用快排
helloworld2018老师好,请教个问题,快排不是稳定算法,为啥还要用快排作者回复: 不是所有的应用场景都关注稳定性呀
2019-07-2810- 学习爱好者王老师,总结8种排序算法的那个图,桶排序不一定是稳定排序吧?比如桶内排序用快排的时候
作者回复: 嗯嗯 用归并或者插入排序就稳定了
2018-11-0510  西南偏北老师,你之前讲的快排、归并,原理我都理解的很清晰,但是一旦到转换成代码的时候,感觉一脸懵逼,你最开始这是这样吗?
西南偏北老师,你之前讲的快排、归并,原理我都理解的很清晰,但是一旦到转换成代码的时候,感觉一脸懵逼,你最开始这是这样吗?作者回复: 是有点 毕竟代码是写给机器执行的 多看几遍 再自己默写默写
2018-10-238
收起评论

