

17 | 跳表:为什么Redis一定要用跳表来实现有序集合?
王争

该思维导图由 AI 生成,仅供参考
上两节我们讲了二分查找算法。当时我讲到,因为二分查找底层依赖的是数组随机访问的特性,所以只能用数组来实现。如果数据存储在链表中,就真的没法用二分查找算法了吗?
实际上,我们只需要对链表稍加改造,就可以支持类似“二分”的查找算法。我们把改造之后的数据结构叫做跳表(Skip list),也就是今天要讲的内容。
跳表这种数据结构对你来说,可能会比较陌生,因为一般的数据结构和算法书籍里都不怎么会讲。但是它确实是一种各方面性能都比较优秀的动态数据结构,可以支持快速地插入、删除、查找操作,写起来也不复杂,甚至可以替代红黑树(Red-black tree)。
Redis 中的有序集合(Sorted Set)就是用跳表来实现的。如果你有一定基础,应该知道红黑树也可以实现快速地插入、删除和查找操作。那 Redis 为什么会选择用跳表来实现有序集合呢? 为什么不用红黑树呢?学完今天的内容,你就知道答案了。
如何理解“跳表”?
对于一个单链表来讲,即便链表中存储的数据是有序的,如果我们要想在其中查找某个数据,也只能从头到尾遍历链表。这样查找效率就会很低,时间复杂度会很高,是 O(n)。
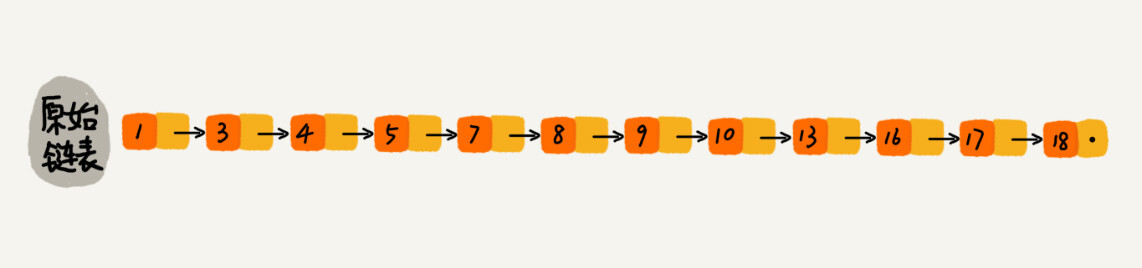
那怎么来提高查找效率呢?如果像图中那样,对链表建立一级“索引”,查找起来是不是就会更快一些呢?每两个结点提取一个结点到上一级,我们把抽出来的那一级叫做索引或索引层。你可以看我画的图。图中的 down 表示 down 指针,指向下一级结点。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

跳表是一种动态数据结构,通过多级索引提高了查找效率,适用于快速地插入、删除和查找操作。文章介绍了跳表的原理和优势,以及在跳表中查询的时间复杂度和空间复杂度的分析。通过对比单链表和跳表的查询效率,阐述了跳表的优越性。此外,还提到了跳表在实际软件开发中的应用,强调了其在处理大对象时的优势。跳表使用空间换时间的设计思路,通过构建多级索引来提高查询的效率,实现了基于链表的“二分查找”。跳表是一种动态数据结构,支持快速地插入、删除、查找操作,时间复杂度都是O(logn)。文章还解答了为什么Redis要用跳表来实现有序集合,而不是红黑树,强调了跳表的灵活性和易读性。总的来说,跳表是一种性能优秀的数据结构,能够提高查询效率,适用于实际的软件开发中。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《数据结构与算法之美》,新⼈⾸单¥68
《数据结构与算法之美》,新⼈⾸单¥68
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(288)
- 最新
- 精选
- leo跳表是我非常喜欢的数据结构,之前写过一篇文章,希望大家斧正(https://cloud.tencent.com/developer/article/1353762)。另外,严格来讲,Redis的对象系统中的每种对象实际上都是基于使用场景选择多种底层数据结构实现的,比如ZSET就是基于【压缩列表】或者【跳跃表+字典】(这也跟之前排序中提到的Sort包实现的思想一样,基于数据规模选择合适的排序算法),体现了Redis对于性能极致的追求。
作者回复: 👍
2018-10-299308 
 escray
escray 如果每三个或者五个节点提取一个节点作为上级索引,那么对应的查询数据时间复杂度,应该也还是 O(logn)。 假设每 5 个节点提取,那么最高一层有 5 个节点,而跳表高度为 log5n,每层最多需要查找 5 个节点,即 O(mlogn) 中的 m = 5,最终,时间复杂度为 O(logn)。 空间复杂度也还是 O(logn),虽然省去了一部分索引节点,但是似乎意义不大。 不知道在一般的生产系统,跳表的提取是按照多少个节点来实现?还是每个系统根据实际情况,都不一样。 看了跳表的 Java 实现,查找部分的代码真是漂亮,插入部分看了半天才看明白。
如果每三个或者五个节点提取一个节点作为上级索引,那么对应的查询数据时间复杂度,应该也还是 O(logn)。 假设每 5 个节点提取,那么最高一层有 5 个节点,而跳表高度为 log5n,每层最多需要查找 5 个节点,即 O(mlogn) 中的 m = 5,最终,时间复杂度为 O(logn)。 空间复杂度也还是 O(logn),虽然省去了一部分索引节点,但是似乎意义不大。 不知道在一般的生产系统,跳表的提取是按照多少个节点来实现?还是每个系统根据实际情况,都不一样。 看了跳表的 Java 实现,查找部分的代码真是漂亮,插入部分看了半天才看明白。作者回复: 👍
2018-10-299138 董航redis有序集合是跳跃表实现的,直接这么说有失偏驳,他是复合数据结构,准确说应该是由一个双hashmap构成的字典和跳跃表实现的,不知道我说的有问题吗😊
董航redis有序集合是跳跃表实现的,直接这么说有失偏驳,他是复合数据结构,准确说应该是由一个双hashmap构成的字典和跳跃表实现的,不知道我说的有问题吗😊作者回复: 后面还会讲 你说的没错 👍
2018-10-292102 长期规划感觉跳表跟B+树有些像,父节点会出现在子节点中,而且B+的叶节点也是链接起来的。不同的是跳表每个结点只有一个子结点,而且除叶结点相连外,每层内都相连。从结构上来,很像树的变种,层内相连。老师,跳表是受树的启发两来的吗?
长期规划感觉跳表跟B+树有些像,父节点会出现在子节点中,而且B+的叶节点也是链接起来的。不同的是跳表每个结点只有一个子结点,而且除叶结点相连外,每层内都相连。从结构上来,很像树的变种,层内相连。老师,跳表是受树的启发两来的吗?作者回复: 有可能是的。
2019-07-25318 許敲敲我是机械行业打算换行的,不知道应该怎么把这些知识掌握的扎实一点,今天课里面的红黑树不了解.
許敲敲我是机械行业打算换行的,不知道应该怎么把这些知识掌握的扎实一点,今天课里面的红黑树不了解.作者回复: 后面会讲 不急
2018-10-29212 刘涛涛github上的代码,我理解的p=p.forwars[i]代表第i层的下一结点,不知道对不对
刘涛涛github上的代码,我理解的p=p.forwars[i]代表第i层的下一结点,不知道对不对作者回复: 对的!👍
2019-02-1727 Pluto学到了,这个厉害了,不过实现还是没有看的太懂
Pluto学到了,这个厉害了,不过实现还是没有看的太懂作者回复: 实现确实不好看懂 我也看了很久
2018-11-057 kakasi感觉github上的实现好难理解,希望老师有时间能解释下。 我有一个思路:定义两个数据结构,一个是普通的单链表Node,一个索引类Index。索引类中两个域:单链表节点Node, 下一个Index引用。用Index数组表示1 - level索引层。 这样数据结构里就不会出现数组了,不知这样的思路是否正确。
kakasi感觉github上的实现好难理解,希望老师有时间能解释下。 我有一个思路:定义两个数据结构,一个是普通的单链表Node,一个索引类Index。索引类中两个域:单链表节点Node, 下一个Index引用。用Index数组表示1 - level索引层。 这样数据结构里就不会出现数组了,不知这样的思路是否正确。作者回复: 你的方法也可以 我的实现思路比较有技巧 是不容易看懂 建议不要纠结实现了
2018-11-126 阿文老师,跳表的索引使用数组是不是就不用建立多级索引了?
阿文老师,跳表的索引使用数组是不是就不用建立多级索引了?作者回复: 使用数组作为索引,如果不建立多级索引,那就只有一层索引,那一层索引的的情况下,我们不仅要维护数组的有序性,还要动态维护索引数组中元素,数组的插入、删除操作的时间复杂度都很高呢,而且如果数组中元素的个数太少,也起不到加速查找的目的呢。
2019-08-235 Smallfly老师想问下文章中出现的等比数列求和怎么算的,因为整数除法是取整的,所以公式好像不好使……,用数据代入老师的公式又是正确的,希望能指点一下。
Smallfly老师想问下文章中出现的等比数列求和怎么算的,因为整数除法是取整的,所以公式好像不好使……,用数据代入老师的公式又是正确的,希望能指点一下。作者回复: 整数除法是取取整的是什么意思啊
2018-10-2955
收起评论

