

08 | 栈:如何实现浏览器的前进和后退功能?
王争

该思维导图由 AI 生成,仅供参考
浏览器的前进、后退功能,我想你肯定很熟悉吧?
当你依次访问完一串页面 a-b-c 之后,点击浏览器的后退按钮,就可以查看之前浏览过的页面 b 和 a。当你后退到页面 a,点击前进按钮,就可以重新查看页面 b 和 c。但是,如果你后退到页面 b 后,点击了新的页面 d,那就无法再通过前进、后退功能查看页面 c 了。
假设你是 Chrome 浏览器的开发工程师,你会如何实现这个功能呢?
这就要用到我们今天要讲的“栈”这种数据结构。带着这个问题,我们来学习今天的内容。
如何理解“栈”?
关于“栈”,我有一个非常贴切的例子,就是一摞叠在一起的盘子。我们平时放盘子的时候,都是从下往上一个一个放;取的时候,我们也是从上往下一个一个地依次取,不能从中间任意抽出。后进者先出,先进者后出,这就是典型的“栈”结构。
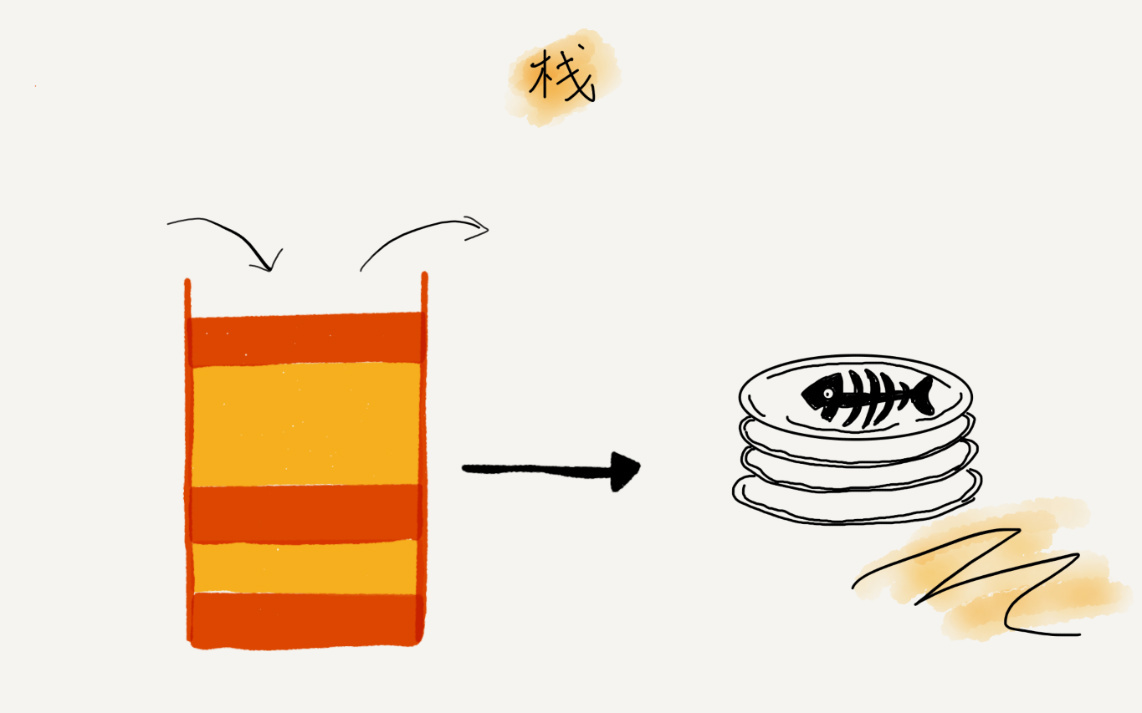
从栈的操作特性上来看,栈是一种“操作受限”的线性表,只允许在一端插入和删除数据。
我第一次接触这种数据结构的时候,就对它存在的意义产生了很大的疑惑。因为我觉得,相比数组和链表,栈带给我的只有限制,并没有任何优势。那我直接使用数组或者链表不就好了吗?为什么还要用这个“操作受限”的“栈”呢?
事实上,从功能上来说,数组或链表确实可以替代栈,但你要知道,特定的数据结构是对特定场景的抽象,而且,数组或链表暴露了太多的操作接口,操作上的确灵活自由,但使用时就比较不可控,自然也就更容易出错。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

栈是一种常见的数据结构,通过浏览器的前进和后退功能引出了栈的概念。栈的特点是后进先出,类比为一摞叠在一起的盘子。文章介绍了栈的基本操作,包括入栈和出栈,并给出了基于数组的顺序栈的实现代码。此外,还讨论了支持动态扩容的顺序栈的实现和复杂度分析。文章通过实例分析了入栈操作的均摊时间复杂度,强调了均摊时间复杂度一般等于最好情况时间复杂度。栈在函数调用、表达式求值和括号匹配中的应用也得到了详细阐述。最后,通过浏览器功能引出栈的概念,介绍了栈的基本操作和实现方式,并通过实例分析了复杂度,适合读者快速了解栈的基本概念和实际应用。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《数据结构与算法之美》,新⼈⾸单¥68
《数据结构与算法之美》,新⼈⾸单¥68
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(439)
- 最新
- 精选
 王争置顶为什么函数调用要用“栈”来保存临时变量呢?用其他数据结构不行吗? 其实,我们不一定非要用栈来保存临时变量,只不过如果这个函数调用符合后进先出的特性,用栈这种数据结构来实现,是最顺理成章的选择。 从调用函数进入被调用函数,对于数据来说,变化的是什么呢?是作用域。所以根本上,只要能保证每进入一个新的函数,都是一个新的作用域就可以。而要实现这个,用栈就非常方便。在进入被调用函数的时候,分配一段栈空间给这个函数的变量,在函数结束的时候,将栈顶复位,正好回到调用函数的作用域内。2018-11-0124869
王争置顶为什么函数调用要用“栈”来保存临时变量呢?用其他数据结构不行吗? 其实,我们不一定非要用栈来保存临时变量,只不过如果这个函数调用符合后进先出的特性,用栈这种数据结构来实现,是最顺理成章的选择。 从调用函数进入被调用函数,对于数据来说,变化的是什么呢?是作用域。所以根本上,只要能保证每进入一个新的函数,都是一个新的作用域就可以。而要实现这个,用栈就非常方便。在进入被调用函数的时候,分配一段栈空间给这个函数的变量,在函数结束的时候,将栈顶复位,正好回到调用函数的作用域内。2018-11-0124869 阿杜S考特置顶内存中的堆栈和数据结构堆栈不是一个概念,可以说内存中的堆栈是真实存在的物理区,数据结构中的堆栈是抽象的数据存储结构。 内存空间在逻辑上分为三部分:代码区、静态数据区和动态数据区,动态数据区又分为栈区和堆区。 代码区:存储方法体的二进制代码。高级调度(作业调度)、中级调度(内存调度)、低级调度(进程调度)控制代码区执行代码的切换。 静态数据区:存储全局变量、静态变量、常量,常量包括final修饰的常量和String常量。系统自动分配和回收。 栈区:存储运行方法的形参、局部变量、返回值。由系统自动分配和回收。 堆区:new一个对象的引用或地址存储在栈区,指向该对象存储在堆区中的真实数据。2018-10-0832957
阿杜S考特置顶内存中的堆栈和数据结构堆栈不是一个概念,可以说内存中的堆栈是真实存在的物理区,数据结构中的堆栈是抽象的数据存储结构。 内存空间在逻辑上分为三部分:代码区、静态数据区和动态数据区,动态数据区又分为栈区和堆区。 代码区:存储方法体的二进制代码。高级调度(作业调度)、中级调度(内存调度)、低级调度(进程调度)控制代码区执行代码的切换。 静态数据区:存储全局变量、静态变量、常量,常量包括final修饰的常量和String常量。系统自动分配和回收。 栈区:存储运行方法的形参、局部变量、返回值。由系统自动分配和回收。 堆区:new一个对象的引用或地址存储在栈区,指向该对象存储在堆区中的真实数据。2018-10-0832957- 王争为什么函数调用要用“栈”来保存临时变量呢?用其他数据结构不行吗? 其实,我们不一定非要用栈来保存临时变量,只不过如果这个函数调用符合后进先出的特性,用栈这种数据结构来实现,是最顺理成章的选择。 从调用函数进入被调用函数,对于数据来说,变化的是什么呢?是作用域。所以根本上,只要能保证每进入一个新的函数,都是一个新的作用域就可以。而要实现这个,用栈就非常方便。在进入被调用函数的时候,分配一段栈空间给这个函数的变量,在函数结束的时候,将栈顶复位,正好回到调用函数的作用域内。
作者回复: 答案 大家可以参考下
2018-11-019325  清以轻尘关于这个浏览器的前进和后退,老师您说的是用两个栈实现,其实开篇我已经想到,但是,我还有一个很不错的解决思路,对于内存消耗可能会高点,但是时间复杂度也很低,就是使用双向链表,用 pre和next 来实现前进和后退
清以轻尘关于这个浏览器的前进和后退,老师您说的是用两个栈实现,其实开篇我已经想到,但是,我还有一个很不错的解决思路,对于内存消耗可能会高点,但是时间复杂度也很低,就是使用双向链表,用 pre和next 来实现前进和后退作者回复: 也可以的 👍
2018-10-22594 Monday对于每次留下的思考题都希望老师在n(n>1)天后给出权威的答案,谢谢。 国庆在家里只看文档和听音频没有记录笔记,回去工作了,一定补上。个人认为本课题是最实惠的知识付费,没有之一。❤
Monday对于每次留下的思考题都希望老师在n(n>1)天后给出权威的答案,谢谢。 国庆在家里只看文档和听音频没有记录笔记,回去工作了,一定补上。个人认为本课题是最实惠的知识付费,没有之一。❤作者回复: 关于思考题 很多同学的留言都已经回答的很好了 关于权威答案 我可以集中写篇文章说说
2018-10-0942 荣思敏
荣思敏 王老师,”你应该可以看出来,这 K 次入栈操作,总共涉及了 K 个数据搬移,以及 K 次 simple-push 操作“-----文章中的这句话,我觉得应该是2K次入栈操作,前K次做了数据搬移(时间复杂度O(1)),第K+1次要扩容,对应的时间复杂度是O(k),后面的k-1时间复杂度是O(1),所以这2K次的操作平摊下来就是O(1)-----是这么理解么?我并不是想钻牛角尖,只是希望真正理解你说的这个概念哈,虽然结果是一样,但我想知道我想错了没有
王老师,”你应该可以看出来,这 K 次入栈操作,总共涉及了 K 个数据搬移,以及 K 次 simple-push 操作“-----文章中的这句话,我觉得应该是2K次入栈操作,前K次做了数据搬移(时间复杂度O(1)),第K+1次要扩容,对应的时间复杂度是O(k),后面的k-1时间复杂度是O(1),所以这2K次的操作平摊下来就是O(1)-----是这么理解么?我并不是想钻牛角尖,只是希望真正理解你说的这个概念哈,虽然结果是一样,但我想知道我想错了没有作者回复: 你说的没错!是的。
2019-03-07216 乘坐Tornado的线程魔法师想借此机会请教一个问题,同时也算是给大家的一道思考题。如果文中计算表达式的例子 涉及到小括号(默认小括号使用合法) 该如何处理呢?
乘坐Tornado的线程魔法师想借此机会请教一个问题,同时也算是给大家的一道思考题。如果文中计算表达式的例子 涉及到小括号(默认小括号使用合法) 该如何处理呢?作者回复: 思路一样的 可以把右括号看作优先级最高的 至于左括号怎么处理 留给你思考吧😄
2018-10-08915 hao请问老师,3+5*8-6的栈计算演示图的第5步和第6步中间是不是省略了一步40 3 + 啊?不然如果表达式是3+5*8/2-6的结果就不对了。谢谢您
hao请问老师,3+5*8-6的栈计算演示图的第5步和第6步中间是不是省略了一步40 3 + 啊?不然如果表达式是3+5*8/2-6的结果就不对了。谢谢您作者回复: 是的 第六步 处理了2个操作符
2018-10-1513 飞羽看到有人问小括号的情况怎么办,我写了个JS的示例,抛砖引玉哈。 主要思路就是遇到小括号时,将小括号内的表达式提取出来,然后进行递归调用。 使用ES6写的,Git地址: https://github.com/taifu5522/ProblemSet
飞羽看到有人问小括号的情况怎么办,我写了个JS的示例,抛砖引玉哈。 主要思路就是遇到小括号时,将小括号内的表达式提取出来,然后进行递归调用。 使用ES6写的,Git地址: https://github.com/taifu5522/ProblemSet作者回复: 👍 不过不需要用递归的
2018-10-099 learning例子举得不恰当,一堆碟子是可以随意抽取的
learning例子举得不恰当,一堆碟子是可以随意抽取的作者回复: 😄 还是比较难抽出来吧 摔坏了咋办
2018-10-09117
收起评论

