

04 | 计算学习理论

该思维导图由 AI 生成,仅供参考
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

这篇文章介绍了机器学习中的计算学习理论,涉及频率学派和贝叶斯学派方法。通过讨论样本容量对估计精度的影响、训练误差和泛化误差的关系、PAC学习理论、样本复杂度和VC维对PAC可学习性的影响等内容,阐述了学习任务的不确定性以及利用概率理论指导通用学习问题求解的基本原则。此外,还介绍了VC维对模型特性的影响,以及Rademacher复杂度在刻画训练误差和泛化误差之间的区别。这些理论框架和概念对于理解机器学习的数学分析和模型泛化误差具有重要意义。总的来说,本文深入探讨了计算学习理论的核心概念,为读者提供了对机器学习理论基础的全面了解。
《机器学习 40 讲》,新⼈⾸单¥59

全部留言(19)
- 最新
- 精选
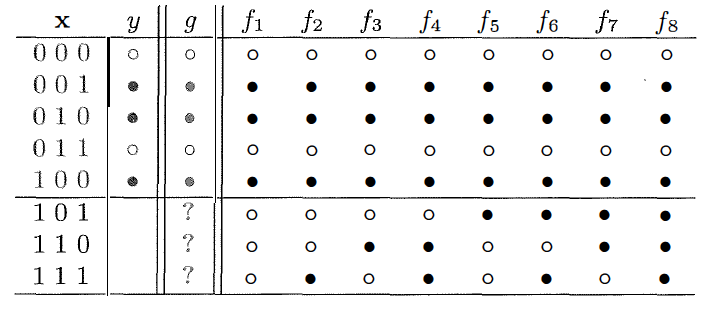
 Will王志翔(大象)以问答的方式,做了文章的笔记。 ❶ 给出问题,一问是否可解,二是如何解?频率学派和贝叶斯学派都在讲如何解,即回答问题二。那是否可解,但往往不是非此即彼,更多的问法,是在投入计算资源之前,先评估一下机器学习能够学到说明什么程度?(就如软件工程中可行性分析) 答:所以,有了“计算学习理论”来回答这个问题。 ❷ 那时什么是“计算学习理论”呢?从一个例子入手,5个三维(0/1)输出,预测3个数据,用机器学习训练,发现,“不管生成机制到底如何,训练数据都没有给出足以决定最优假设的信息。” 那机器学习在学习什么呢? 答:“概率”,不能给出最优解,可以给出近似解啊! ❸ 第二个例子:“红球与白球”,既然用“概率”工具,那么用 ν 来近似 μ 有多高的精确度呢?有没有理论支撑? 答:可以用“Hoeffding不等式”回答,“Hoeffding不等式”描述了训练误差和泛化误差之间的近似关系。 训练误差是模型在训练集上的误差,泛化误差是用来衡量模型的泛化性。 结论是总会存在一个足够大的样本容量 N 使两者近似相等,这时就可以根据模型的训练误差来推导其泛化误差,从而获得关于真实情况的一些信息。 ❹ 现在有了“概率”工具,说明问题的可学习性,那需要多少训练数据才能达到给定的准确度参数和置信参数呢? 答:我们可以用“样本复杂度”(sample complexity)来表示。所有假设空间有限的问题都是“概率近似正确”PAC 可学习的,其样本复杂度有固定的下界,输出假设的泛化误差会随着样本数目的增加以一定速度收敛到0。 ❺ 有限空间有了,那如何判断具有无限假设空间的问题是否是 PAC 可学习的呢? 答:用“VC维”:对无限假设空间复杂度的一种度量方式。任何 VC 维有限的假设空间都是 PAC 可学习的。由于 VC 维并不依赖于数据分布的先验信息,因此它得到的结果是个松散的误差界(error bound),这个误差界适用于任意分布的数据。 ❻ “松散的误差界”?是不是可用性较差?不能加入数据分布的先验信息呢? 答:所以有了“Rademacher 复杂度”。在已知的数据分布下,Rademacher 复杂度既可以表示函数空间的复杂度,也可以用来计算泛化误差界 ❼ 学习理论的研究对解决实际问题到底具有什么样的指导意义呢? 答:举一个例子:神经网络的VC维相对较高,因而它的表达能力非常强,可以用来处理任何复杂的分类问题。要充分训练该神经网络,所需样本量为10倍的VC维。如此大的训练数据量,是不可能达到的。所以在20世纪,复杂神经网络模型在out of sample的表现不是很好,容易overfit。但现在为什么深度学习的表现越来越好? 其中一条是:通过修改神经网络模型的结构,以及提出新的regularization方法,使得神经网络模型的VC维相对减小了。例如卷积神经网络,通过修改模型结构(局部感受野和权值共享),减少了参数个数,降低了VC维。2012年的AlexNet,8层网络,参数个数只有60M;而2014年的GoogLeNet,22层网络,参数个数只有7M。再例如dropout,drop connect,denosing等regularization方法的提出,也一定程度上增加了神经网络的泛化能力。 —— 例子参考《VC维的来龙去脉》
Will王志翔(大象)以问答的方式,做了文章的笔记。 ❶ 给出问题,一问是否可解,二是如何解?频率学派和贝叶斯学派都在讲如何解,即回答问题二。那是否可解,但往往不是非此即彼,更多的问法,是在投入计算资源之前,先评估一下机器学习能够学到说明什么程度?(就如软件工程中可行性分析) 答:所以,有了“计算学习理论”来回答这个问题。 ❷ 那时什么是“计算学习理论”呢?从一个例子入手,5个三维(0/1)输出,预测3个数据,用机器学习训练,发现,“不管生成机制到底如何,训练数据都没有给出足以决定最优假设的信息。” 那机器学习在学习什么呢? 答:“概率”,不能给出最优解,可以给出近似解啊! ❸ 第二个例子:“红球与白球”,既然用“概率”工具,那么用 ν 来近似 μ 有多高的精确度呢?有没有理论支撑? 答:可以用“Hoeffding不等式”回答,“Hoeffding不等式”描述了训练误差和泛化误差之间的近似关系。 训练误差是模型在训练集上的误差,泛化误差是用来衡量模型的泛化性。 结论是总会存在一个足够大的样本容量 N 使两者近似相等,这时就可以根据模型的训练误差来推导其泛化误差,从而获得关于真实情况的一些信息。 ❹ 现在有了“概率”工具,说明问题的可学习性,那需要多少训练数据才能达到给定的准确度参数和置信参数呢? 答:我们可以用“样本复杂度”(sample complexity)来表示。所有假设空间有限的问题都是“概率近似正确”PAC 可学习的,其样本复杂度有固定的下界,输出假设的泛化误差会随着样本数目的增加以一定速度收敛到0。 ❺ 有限空间有了,那如何判断具有无限假设空间的问题是否是 PAC 可学习的呢? 答:用“VC维”:对无限假设空间复杂度的一种度量方式。任何 VC 维有限的假设空间都是 PAC 可学习的。由于 VC 维并不依赖于数据分布的先验信息,因此它得到的结果是个松散的误差界(error bound),这个误差界适用于任意分布的数据。 ❻ “松散的误差界”?是不是可用性较差?不能加入数据分布的先验信息呢? 答:所以有了“Rademacher 复杂度”。在已知的数据分布下,Rademacher 复杂度既可以表示函数空间的复杂度,也可以用来计算泛化误差界 ❼ 学习理论的研究对解决实际问题到底具有什么样的指导意义呢? 答:举一个例子:神经网络的VC维相对较高,因而它的表达能力非常强,可以用来处理任何复杂的分类问题。要充分训练该神经网络,所需样本量为10倍的VC维。如此大的训练数据量,是不可能达到的。所以在20世纪,复杂神经网络模型在out of sample的表现不是很好,容易overfit。但现在为什么深度学习的表现越来越好? 其中一条是:通过修改神经网络模型的结构,以及提出新的regularization方法,使得神经网络模型的VC维相对减小了。例如卷积神经网络,通过修改模型结构(局部感受野和权值共享),减少了参数个数,降低了VC维。2012年的AlexNet,8层网络,参数个数只有60M;而2014年的GoogLeNet,22层网络,参数个数只有7M。再例如dropout,drop connect,denosing等regularization方法的提出,也一定程度上增加了神经网络的泛化能力。 —— 例子参考《VC维的来龙去脉》作者回复: 回答如此认真,值得点赞👍您的深入思考才是专栏最理想的效果
2018-06-30267 Spencer可以增加一些参考论文吗?
Spencer可以增加一些参考论文吗?作者回复: VC维这部分可以看看Abu-Mostafa的教材Learning from Data,本文的内容也是参考他的课程,真的深入浅出,水平很高。 计算学习理论可以看以色列人的教材Understanding Machine Learning: From Theory to Algorithm,有中译本。直接以PAC作为基础开始讲起,偏数学推导,比较难读。
2018-06-129 安邦讲得非常好,但是模仿机器学习基石中的内容,会不会不太好
安邦讲得非常好,但是模仿机器学习基石中的内容,会不会不太好作者回复: 这部分参考的是加州理工Abu-Mostafa的教材Learning from Data,机器学习基石的主讲应该是他的学生或者同事。Abu-Mostafa教授关于学习理论的讲解我认为是最清晰明了的,与其班门弄斧,不如将大师成熟的想法直接呈现出来,也算是见贤思齐吧。
2018-06-147- Geek_4ca45d老师,请问学这类课题是不是,主要掌握概率学就基本可以了?还有机器学习是不是人工智能?
作者回复: 计算学习理论涉及的数学很深的,概率主要是用到一些概率不等式,包括介绍到的Hoeffding和没介绍的其他不等式。你可以看看vapnik关于统计学习的书,直观感受一下这部分内容。 机器学习是人工智能发展最快的一个领域,不能说它就是人工智能。人工智能还包括知识表示、推理这些方向。
2018-06-124  Float周志华在书上说,计算学习理论是机器学习的理论基础,可以根据它来分析学习任务并指导算法设计。但是想请问老师,在具体问题上,是怎么使用它的呢?或者它还有其他什么作用吗?
Float周志华在书上说,计算学习理论是机器学习的理论基础,可以根据它来分析学习任务并指导算法设计。但是想请问老师,在具体问题上,是怎么使用它的呢?或者它还有其他什么作用吗?作者回复: 现实中的问题没有非黑即白,我们只能给出一个近似的答案。学习理论的意义就在于对问题的近似能达到什么样的精确程度,这是可以用通用公式算出来的。 但是这套理论给出的是独立于问题的结果,在实际中总会有一些问题接近这个界,另一些问题远离这个界。这时就得具体情况具体分析,利用问题自身的先验来优化。
2018-06-133 风的轨迹王老师,我可以这么理解吗? 整篇文章都是围绕着“如何刻画训练误差和泛化误差之间的精度”来进行阐述的 1. 如果在某种条件(样本容量足够大的情况下)下,精度足够小,那么通过计算的方法来学到最优假设是可行的。 2. 引入两个维度来描述样本的复杂度,使我们了解到样本的复杂度其实是会影响到训练误差和泛化误差的精度的。 由此我们可以在设计机器学习任务的时候能够考虑到更多的因素从而使各方面达到一个比较好的均衡。
风的轨迹王老师,我可以这么理解吗? 整篇文章都是围绕着“如何刻画训练误差和泛化误差之间的精度”来进行阐述的 1. 如果在某种条件(样本容量足够大的情况下)下,精度足够小,那么通过计算的方法来学到最优假设是可行的。 2. 引入两个维度来描述样本的复杂度,使我们了解到样本的复杂度其实是会影响到训练误差和泛化误差的精度的。 由此我们可以在设计机器学习任务的时候能够考虑到更多的因素从而使各方面达到一个比较好的均衡。作者回复: 你理解的没问题,学习理论就是要从理论上证明训练误差可以足够接近泛化误差。只要假设不要太复杂,并且数据足够多,训练误差都能收敛到泛化误差上,学习方法也就是有效的。
2018-06-123 Addison您好,我想问下:“在打散的基础上可以进一步定义 VC 维。假设空间的 VC 维是能被这个假设空间打散的最大集合的大小,它表示的是完全正确分类的最大能力。上面的例子告诉我们,对于具有两个自由度的线性模型来说”这句话的,具有两个自由度的线形模型中的两个自由度是不是理解为:y=kx+b中,k和b是两个可以自由定义的变量?
Addison您好,我想问下:“在打散的基础上可以进一步定义 VC 维。假设空间的 VC 维是能被这个假设空间打散的最大集合的大小,它表示的是完全正确分类的最大能力。上面的例子告诉我们,对于具有两个自由度的线性模型来说”这句话的,具有两个自由度的线形模型中的两个自由度是不是理解为:y=kx+b中,k和b是两个可以自由定义的变量?作者回复: 是的,有些时候也会限制直线的截距为0,这时就只剩一个了。
2018-06-192 知足太书面化了,就没有一种比较生动形象的描述么?
知足太书面化了,就没有一种比较生动形象的描述么?作者回复: 这部分内容确实偏理论一些。
2018-06-17 林彦有了这些理论基础,明白哪些方式是降低训练误差,哪些方式是减少训练误差和泛化误差的差距的,结合模型的表现判断和选择合适的优化方向或方式,这是我的理解。
林彦有了这些理论基础,明白哪些方式是降低训练误差,哪些方式是减少训练误差和泛化误差的差距的,结合模型的表现判断和选择合适的优化方向或方式,这是我的理解。作者回复: 还可以给出独立于问题的性能评估方式。
2018-06-12 刘艾伦04166666一个具有无穷 VC 维的假设空间是 y=sin(kx),原因: 傅里叶变换可以拟合任意函数2021-01-013
刘艾伦04166666一个具有无穷 VC 维的假设空间是 y=sin(kx),原因: 傅里叶变换可以拟合任意函数2021-01-013