

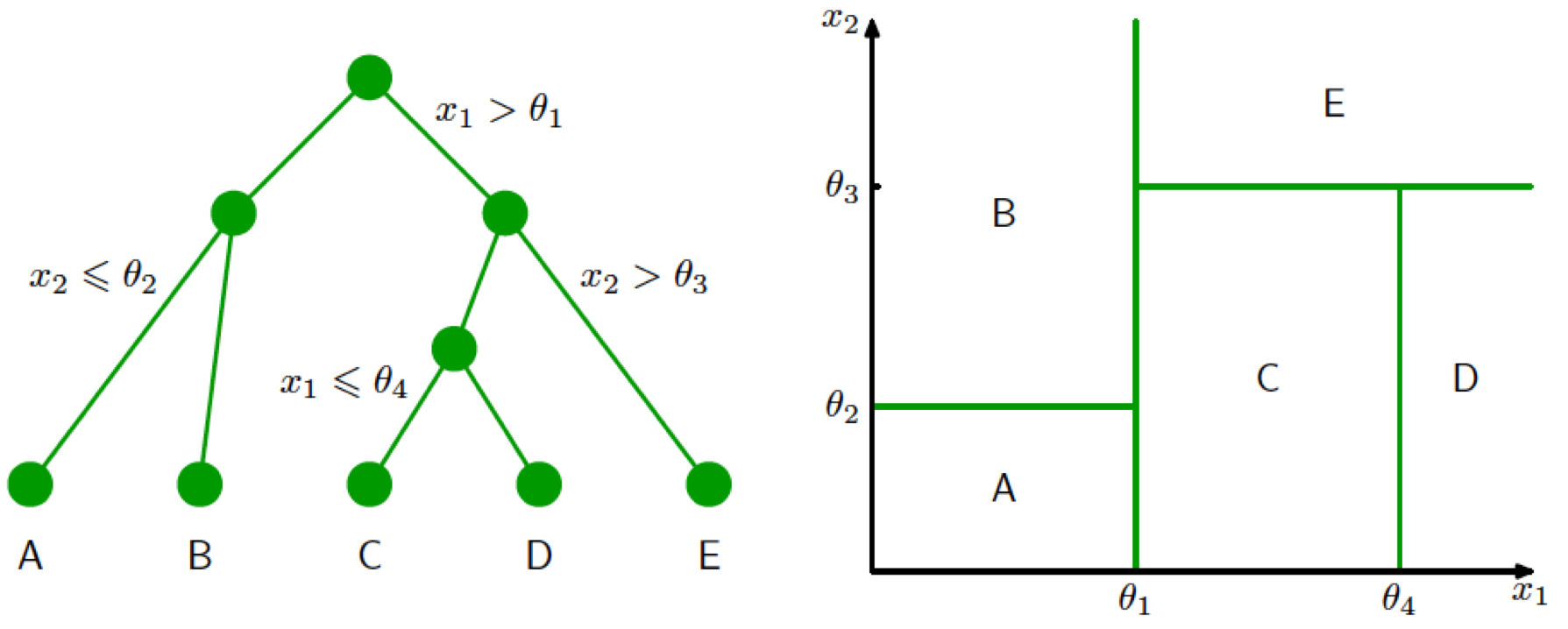
25 | 基于特征的区域划分:树模型

该思维导图由 AI 生成,仅供参考
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

树模型在机器学习中的应用基于“分而治之”的思路,通过递归方式将特征空间划分为若干个矩形的区间,再在每个区间上拟合出一个简单的模型。本文以回归树为例,从线性回归模型的角度出发,介绍了树模型的工作原理和特点。相比全局的线性回归,树模型是局部化的,能够实现非线性的拟合,并且对特征之间的相互作用有更强的刻画能力。文章还详细介绍了回归树的划分方式和拟合过程,以及在实际数据集上的应用效果。通过对英超数据集和位置评分数据的拟合实例,展示了回归树在多元回归问题中的表现和对特征交互的处理方式。决策树的生成算法先将特征空间划分成若干区域,再在每个区域上拟合输出,能够更加灵活地刻画不同属性之间的相互作用。决策树可以看成最简单的集成模型,是一类机器学习的模型,也是决策分析中常用的结构化方法。总的来说,本文通过对树模型的理解,为读者提供了从线性回归角度来理解树模型的新思路,帮助读者更好地理解和应用树模型在机器学习中的作用。
《机器学习 40 讲》,新⼈⾸单¥59

全部留言(6)
- 最新
- 精选
 Yukiii🐋老师,如果想自己从头开始写一棵树,有必要自己尝试重写Scikit-learn 库中 tree 模块的 DecisionTreeRegressor 类吗
Yukiii🐋老师,如果想自己从头开始写一棵树,有必要自己尝试重写Scikit-learn 库中 tree 模块的 DecisionTreeRegressor 类吗作者回复: 可以尝试,自己亲自动手写一遍的效果胜过看代码千百遍。
2019-06-211 林彦决策树我的理解过去可以用来搜索知识库和标签基于逻辑做问答。没有机器学习训练大量数据就是一个专家系统,比如哈利波特里面分学院用的帽子,依赖知识和经验。现在有机器学习,网上搜索不用机器学习的决策树案例不那么容易找到。
林彦决策树我的理解过去可以用来搜索知识库和标签基于逻辑做问答。没有机器学习训练大量数据就是一个专家系统,比如哈利波特里面分学院用的帽子,依赖知识和经验。现在有机器学习,网上搜索不用机器学习的决策树案例不那么容易找到。作者回复: 决策树还可以用作概念学习和基于规则的归纳推理,但都是早期的应用,随着符号主义的衰落式微了。
2018-08-14- 林彦看到文中提到决策树和回归样条的关系。有下面的这些延伸思考和问题想请王老师确认。 1. 回归树的特征选择(用来分枝的特征)是基于当前步骤取值区间使得所有决策树分枝的方差下降之和最大化?在每个分枝区间内是一个线性回归模型,计算方差的方式和线性回归模型一样? 2. 三次样条回归是让所有分段的线性回归模型的均方误差之和最小化?三次样条回归每个分段的边界点选择是基于什么指标或什么原则呢?
作者回复: 1. 方差下降是要让划分之后每个区域内的方差尽可能小,这使得每个区域内的数据相似度较高,所以可以用单个常数,通常是分枝区间内的数据均值来拟合这个区域。 想象一下这样的例子:平面左侧和右侧各有一个圆,每个圆里都均匀分布着数据。如果两个圆距离较远,那么数据整体的方差就会比较大。理想的回归树应该把边界画在两个圆中间,这样划分之后每一边的数据各自接近,两边的方差都比较小,和原来相比方差整体的下降就会较大。如果把边界画在其中一个圆的中间,这个圆的半边数据就被归到另一个圆里,计算出来的方差依然会很大,自然就不是最优的边界了。 2. 样条回归拟合的思路和普通线性回归的思路一样,都是让训练集上的均方误差最小化,但没法求解析解。结点位置和数目一般是靠试的,不成文的规则是根据自由度确定结点数目,再让结点在定义域上均匀分布,也就是取定义域的分位点。
2018-08-14  Ophui天一老师,扩充了样本维度形成的高维小样本集即便训练效果很好,是不是因为维度很高,就会有问题?
Ophui天一老师,扩充了样本维度形成的高维小样本集即便训练效果很好,是不是因为维度很高,就会有问题?作者回复: 为什么要扩充维度呢?原则上说,小样本维度过高会造成维数灾难,样本容量撑不起过多的特征。最好对高维特征做个预处理,保留真正有意义的特征。
2018-08-02- never_giveup老师,我又来了😊,据我所知,决策树在游戏AI和项目管理方面有所应用。另外我突然想到想一个问题,回归问题能从概率角度解释吗?好像不行,没有贝叶斯回归这个东西
作者回复: 贝叶斯回归是有的哦,你可以查一查Bayesian regression,和11讲中的贝叶斯方法做个比较。
2018-08-01  ifelse
ifelse 学习打卡2023-06-10归属地:浙江
学习打卡2023-06-10归属地:浙江