

26 | 集成化处理:Boosting与Bagging
王天一

该思维导图由 AI 生成,仅供参考
伊壁鸠鲁(Epicurus)是古希腊一位伟大的哲学家,其哲学思想自成一派。在认识论上,伊壁鸠鲁最核心的观点就是“多重解释原则”(Prinicple of Multiple Explanantions),其内容是当多种理论都能符合观察到的现象时,就要将它们全部保留。这在某种程度上可以看成是机器学习中集成方法的哲学基础。
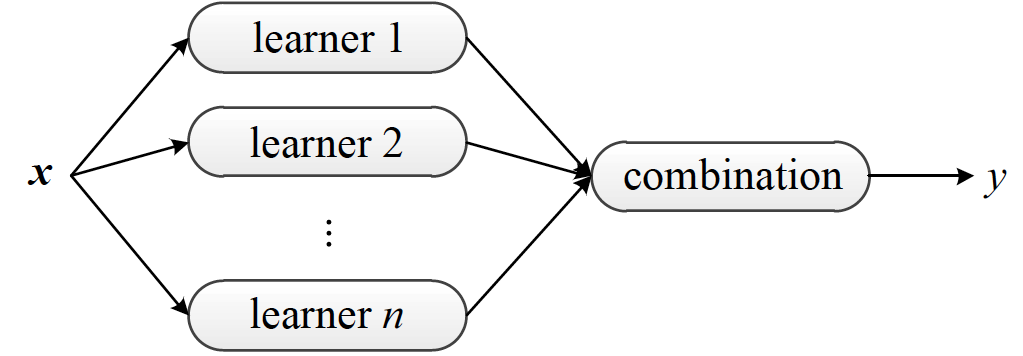
集成学习架构图(图片来自 Ensemble Methods: Foundations and Algorithms,图 1.9)
集成学习的常用架构如上图所示。在统计学习中,集成学习(ensemble learning)是将多个基学习器(base learners)进行集成,以得到比每个单独基学习器更优预测性能的方法。每个用于集成的基学习器都是弱学习器(weak learner),其性能可以只比随机猜测稍微好一点点。
集成学习的作用就是将这多个弱学习器提升成一个强学习器(strong learner),达到任意小的错误率。
在设计算法之前,集成学习先要解决的一个理论问题是集成方法到底有没有提升的效果。虽说三个臭皮匠赛过诸葛亮,但如果皮匠之间没法产生化学反应,别说诸葛亮了,连个蒋琬、费祎恐怕都凑不出来。
在计算学习的理论中,这个问题可以解释成弱可学习问题(weakly learnable)和强可学习问题(strongly learnable)的复杂性是否等价。幸运的是,这个问题的答案是“是”,而实现从弱到强的手段就是提升方法。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

集成学习是一种强大的统计学习方法,通过将多个弱学习器组合成一个强学习器来提升预测性能。其中,提升方法和装袋法是两种重要的集成学习技术。自适应提升(AdaBoost)通过动态调整样本权重来训练弱分类器,并将它们组合成强分类器。另一方面,装袋法通过对训练数据集进行重采样,建立多个预测模型并对其结果进行平均,从而降低统计学习方法的方差。决策树是集成学习中备受青睐的基学习器,而堆叠法则是一种层次化的集成方法,通过组合不同的基学习器来提升整体的预测性能。集成方法超越了简单的模型范畴,是元学习的方法,通过多算法的融合来实现更加灵活的学习。总体而言,集成学习方法通过充分发挥各自优势,提升整体的预测性能。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《机器学习 40 讲》,新⼈⾸单¥59
《机器学习 40 讲》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(6)
- 最新
- 精选
 我心飞扬MultiBoosting由于集合了Bagging,Wagging,AdaBoost,可以有效的降低误差和方差,特别是误差。但是训练成本和预测成本都会显著增加。 Iterative Bagging相比Bagging会降低误差,但是方差上升。由于Bagging本身就是一种降低方差的算法,所以Iterative Bagging相当于Bagging与单分类器的折中。
我心飞扬MultiBoosting由于集合了Bagging,Wagging,AdaBoost,可以有效的降低误差和方差,特别是误差。但是训练成本和预测成本都会显著增加。 Iterative Bagging相比Bagging会降低误差,但是方差上升。由于Bagging本身就是一种降低方差的算法,所以Iterative Bagging相当于Bagging与单分类器的折中。作者回复: 总结得很到位👍
2018-08-023
 InsomniaTony如果对基于决策树的方法感兴趣的话,可以看Gilles Louppe的博士毕业论文Understanding Random Forest。个人觉得很有帮助
InsomniaTony如果对基于决策树的方法感兴趣的话,可以看Gilles Louppe的博士毕业论文Understanding Random Forest。个人觉得很有帮助作者回复: 感谢推荐!
2018-10-20 林彦MultiBoosting如果不引入有泊松分布的权重来对样本作wagging,不知道在性能和效果上是否能比Adaboost达到更好的平衡。 Iterative Boosting方法的文章不好找,有没有更具体的称呼。 从实践中看,这几年GBDT,XGBoost,Random Forest太好用了。除了它们和基本的几类集成学习方法外,介绍其他的延伸集成学习方法通俗易懂,正确,且不只是概述的中文文章在学术领域之外很少。
林彦MultiBoosting如果不引入有泊松分布的权重来对样本作wagging,不知道在性能和效果上是否能比Adaboost达到更好的平衡。 Iterative Boosting方法的文章不好找,有没有更具体的称呼。 从实践中看,这几年GBDT,XGBoost,Random Forest太好用了。除了它们和基本的几类集成学习方法外,介绍其他的延伸集成学习方法通俗易懂,正确,且不只是概述的中文文章在学术领域之外很少。作者回复: Multiboosting相当于AdaBoost和wagging的结合,wagging的作用主要在于通过随机的样本权重扰动降低方差。去掉wagging也就是普通的AdaBoost了。 你说的是iterative bagging吗?可以参考2001年Leo Breiman的论文Using iterated bagging to debias regressions。这种方法也叫adaptive bagging,诞生快20年一直不温不火,没受到多少关注。
2018-08-18 ifelse
ifelse 学习打卡2023-06-11归属地:浙江
学习打卡2023-06-11归属地:浙江- wsstony有没有实际的实战例子,这样结合例子和理论,加深理解。2020-01-16
 周平没看太懂,需要多次学习2018-08-03
周平没看太懂,需要多次学习2018-08-03
收起评论