

25 | 分布式Trace:横跨几十个分布式组件的慢请求要如何排查?
唐扬

该思维导图由 AI 生成,仅供参考
你好,我是唐扬。
经过前面几节课的学习,你的垂直电商系统在引入 RPC 框架和注册中心之后已经完成基本的服务化拆分了,系统架构也有了改变:
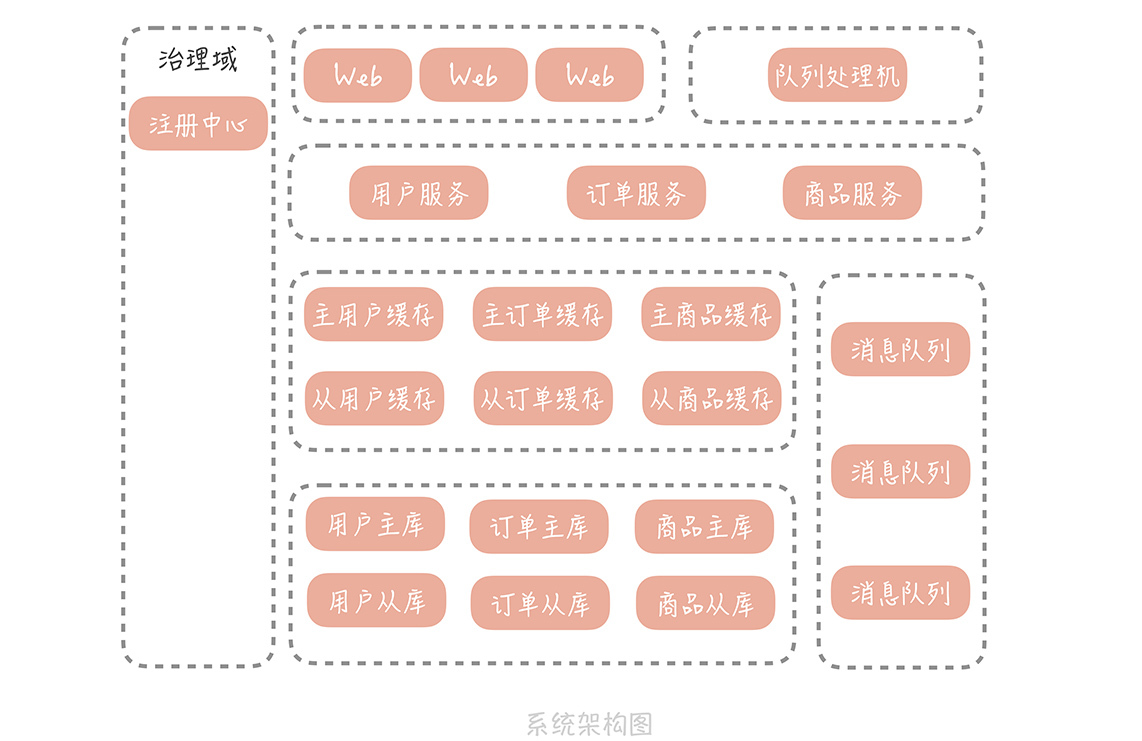
现在,你的系统运行平稳,老板很高兴,你也安心了很多。而且你认为,在经过了服务化拆分之后,服务的可扩展性增强了很多,可以通过横向扩展服务节点的方式平滑地扩容了,对于应对峰值流量也更有信心了。
但是这时出现了问题:你通过监控发现,系统的核心下单接口在晚高峰的时候,会有少量的慢请求,用户也投诉在 APP 上下单时,等待的时间比较长。而下单的过程可能会调用多个 RPC 服务或者使用多个资源,一时之间,你很难快速判断究竟是哪个服务或者资源出了问题,从而导致整体流程变慢。于是你和你的团队开始想办法如何排查这个问题。
一体化架构中的慢请求排查如何做
因为在分布式环境下,请求要在多个服务之间调用,所以对于慢请求问题的排查会更困难,我们不妨从简单的入手,先看看在一体化架构中是如何排查这个慢请求的问题的。
最简单的思路是:打印下单操作的每一个步骤的耗时情况,然后通过比较这些耗时的数据,找到延迟最高的一步,然后再来看看这个步骤要如何优化。如果有必要的话,你还需要针对步骤中的子步骤,再增加日志来继续排查,简单的代码就像下面这样:
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了在分布式系统中排查慢请求的复杂性和关键性。作者首先介绍了在引入RPC框架和注册中心后系统出现慢请求的情况,以及如何排查这些问题。随后,文章重点讨论了如何使用分布式Trace技术来跟踪横跨多个分布式组件的请求,帮助定位慢请求的根本原因。此外,还介绍了如何使用静态代理的方式进行切面编程,避免在业务代码中加入大量打印耗时日志的代码,减少对代码的侵入性。另外,增加日志采样率和使用消息队列将日志集中存储到Elasticsearch中,以便在排查问题时快速定位。总的来说,本文为面临分布式系统慢请求排查问题的技术人员提供了有益的指导和思路。文章内容深入浅出,对于读者快速了解分布式系统慢请求排查问题具有重要参考价值。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《高并发系统设计 40 问》,新⼈⾸单¥59
《高并发系统设计 40 问》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(27)
- 最新
- 精选
 longslee
longslee 打开。感谢老师又给我复习来一遍。 调用链追踪是我们项目比较重要的部分,我们才用的是pinpoint,原生是入HBase,我们改造了一份通过队列入ES。 使用感受 pinpoint 对服务的性能负担很小,网络压力也小(udp)。 调用链追踪体现的始终是在服务之间,我们团队又前移了一步,通过JavaScript对XHR对象拦截,产生一个requestID,附在header上,网关透传,改造了下 pinpoint,使接下来的调用都传递这个 requestID,最后存下来的日志有 traceID 和 requestID 组合,那么监控 nginx 日志的时候,就能知道是哪个前端请求发起的问题,甚至知道是哪个按钮触发的,哪个JavaScript方法触发的,是不是很先进哈哈😂
打开。感谢老师又给我复习来一遍。 调用链追踪是我们项目比较重要的部分,我们才用的是pinpoint,原生是入HBase,我们改造了一份通过队列入ES。 使用感受 pinpoint 对服务的性能负担很小,网络压力也小(udp)。 调用链追踪体现的始终是在服务之间,我们团队又前移了一步,通过JavaScript对XHR对象拦截,产生一个requestID,附在header上,网关透传,改造了下 pinpoint,使接下来的调用都传递这个 requestID,最后存下来的日志有 traceID 和 requestID 组合,那么监控 nginx 日志的时候,就能知道是哪个前端请求发起的问题,甚至知道是哪个按钮触发的,哪个JavaScript方法触发的,是不是很先进哈哈😂作者回复: 很赞~
2019-11-241160 阿土对于老旧系统如何引入分布式Trace跟踪呢?不改代码的前提下
阿土对于老旧系统如何引入分布式Trace跟踪呢?不改代码的前提下作者回复: 这要分布式Trace组件来解决,比如java可以通过java agent的方式来在启动之前植入trace的代码
2019-11-2725 吃饭饭这不就是链路追踪
吃饭饭这不就是链路追踪作者回复: 是的
2019-11-205 水目沾老师,所有的日志都采集到一起,最终的数据量会不会非常大?一般放在什么样的系统中?
水目沾老师,所有的日志都采集到一起,最终的数据量会不会非常大?一般放在什么样的系统中?作者回复: 一般写在nosql数据库里面,比如hbase
2019-11-204 钱思路都是一样,目前公司在用的一个日志分析系统就是这么玩的,不过打印日志需要改造一下,这个有成本。比较倾向于使用方法监控来做分析,对慢请求定位也非常方便,方法调用量、TPS、是否可用、以及其他的聚合信息一目了然,再加上方法调用链的串接慢请求具体位置非常简单就能定位到,而且自己方法的各种信息也一目了然。
钱思路都是一样,目前公司在用的一个日志分析系统就是这么玩的,不过打印日志需要改造一下,这个有成本。比较倾向于使用方法监控来做分析,对慢请求定位也非常方便,方法调用量、TPS、是否可用、以及其他的聚合信息一目了然,再加上方法调用链的串接慢请求具体位置非常简单就能定位到,而且自己方法的各种信息也一目了然。作者回复: 👍
2020-04-272 枫紫深蓝发送到请求体中有什么特定作用吗?请求体本身已经带走当前调用的数据了,将requestId放在请求头中会不会更好?
枫紫深蓝发送到请求体中有什么特定作用吗?请求体本身已经带走当前调用的数据了,将requestId放在请求头中会不会更好?作者回复: 其实都好,我们习惯放在请求体里面
2019-11-252 Alex Liu日志采样比例的选择是需要足够业务经验才能做出的决策?还是一般都是按照10%采样?
Alex Liu日志采样比例的选择是需要足够业务经验才能做出的决策?还是一般都是按照10%采样?作者回复: 按照你的业务量级会产生多少日志量
2020-03-2621 道编译期做切面代码注入,让原来的引用指向代理对象。查阅了下AspectJ,基本是android环境,分布式服务端如何做静态代理
道编译期做切面代码注入,让原来的引用指向代理对象。查阅了下AspectJ,基本是android环境,分布式服务端如何做静态代理作者回复: 不是的吧 AspectJ可以结合spring使用的
2020-06-01 如歌最近在做网关 可能会涉及到追踪的问题 学习一下
如歌最近在做网关 可能会涉及到追踪的问题 学习一下作者回复: 👍
2020-03-28 我行我素记得spring Cloud中就有对应的配置,开启后就能在es中根据requestId追踪日志
我行我素记得spring Cloud中就有对应的配置,开启后就能在es中根据requestId追踪日志作者回复: :) 这个对于追踪问题帮助很大
2020-02-154
收起评论

