

10 | 发号器:如何保证分库分表后ID的全局唯一性?

该思维导图由 AI 生成,仅供参考
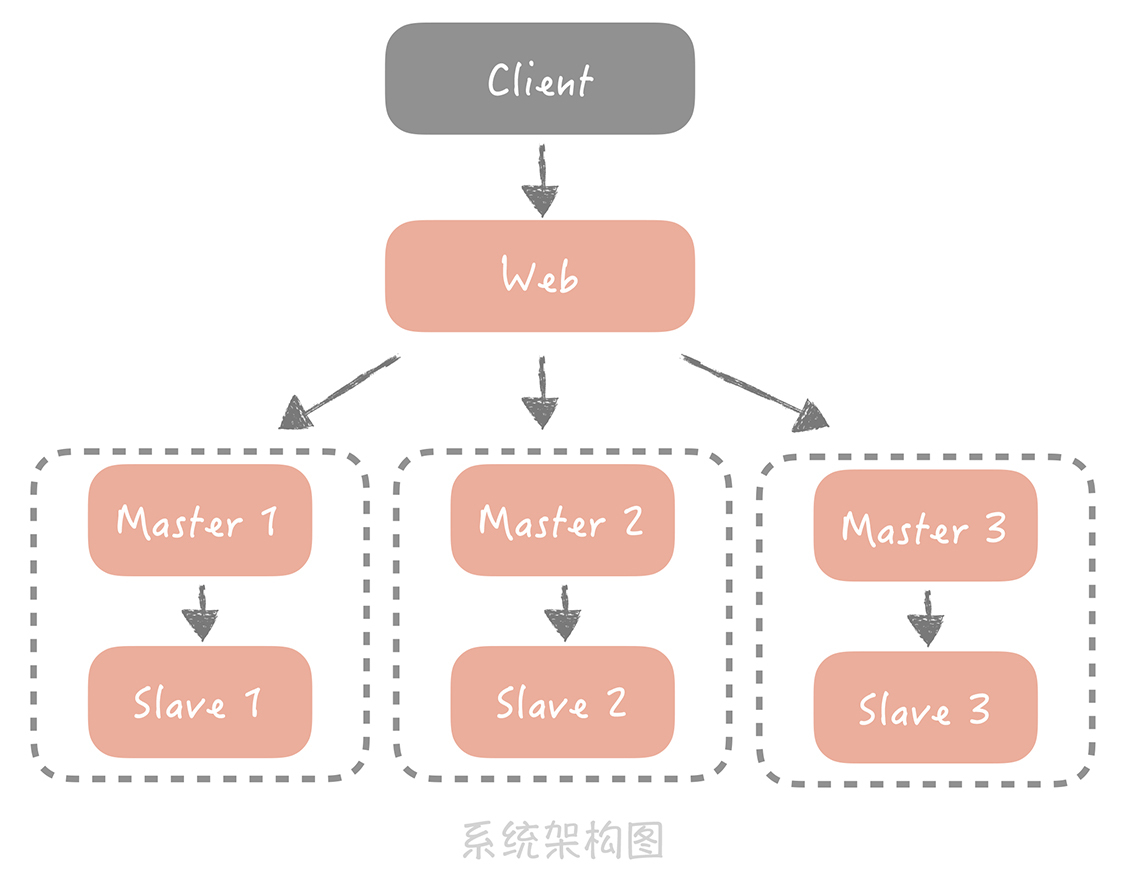
数据库的主键要如何选择?
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

分库分表是解决数据库扩展性问题的有效方式,但在此过程中,全局唯一性的主键生成成为一个挑战。文章介绍了在分库分表后如何保证ID的全局唯一性,提出了使用生成的唯一ID作为主键的建议。对于单库单表的场景,可以使用数据库的自增字段作为ID,但在分库分表后,这种方式无法保证ID的全局唯一性。因此,建议搭建发号器服务来生成全局唯一的ID。这样可以确保在分布到多个库中的同一个逻辑表的数据中,ID仍然是全局唯一的。文章还介绍了选择主键的两种方式:使用业务字段或者生成的唯一ID,并分析了它们的适用场景和局限性。文章内容深入浅出,为读者提供了解决分库分表后ID全局唯一性问题的有效方法。 文章还介绍了Snowflake算法的原理和设计思想,以及如何将其工程化应用来生成全局唯一的ID。Snowflake算法通过将64位的二进制数字分成若干部分,存储时间戳、机器ID、序列号等数据,最终生成全局唯一的有序ID。该算法简单高效,能够生成具有全局唯一性、单调递增性和有业务含义的ID。然而,它也存在一些缺点,如依赖系统时间戳可能导致生成重复ID,以及在低QPS情况下可能造成数据分配不均匀的问题。作者还分享了对Snowflake算法的改造和优化方法,以及其他公司基于数据库生成ID的方案。这些方法都能解决分布式环境下ID全局唯一性的问题,读者可以从中寻找适合自己业务场景的解决方案。 总的来说,本文通过介绍分库分表后ID全局唯一性的问题和Snowflake算法的应用,为读者提供了解决数据库扩展性和ID生成问题的有效方法,同时也启发读者多角度了解不同的方法,找到最适合自己业务场景的解决方案。
《高并发系统设计 40 问》,新⼈⾸单¥59

全部留言(57)
- 最新
- 精选
 阿杜不仅仅是分库分表后的数据库,很多业务场景都需要分布式发号器,使用snowflake是个很好的选择,不过一般都是用的snowflake雪花算法,实现上会有所差异,比如机器位数和序号位数的选取就不同,1+41位时间戳+10机器区间位+12号递增或随机的数字,类似这种。uuid长度过长,也不递增,使用受限。不过snowflake算法有个问题就是服务器时间回拨的问题,就是时间可能不准,这个时候不能停止发号,我觉得可以采取的方式是:每个服务器存储最新的一个maxNewId,起个线程监控服务器时间是否正确,不正确就从maxNewId递增1获取,同事调准服务器时间,直到服务器时间正确。
阿杜不仅仅是分库分表后的数据库,很多业务场景都需要分布式发号器,使用snowflake是个很好的选择,不过一般都是用的snowflake雪花算法,实现上会有所差异,比如机器位数和序号位数的选取就不同,1+41位时间戳+10机器区间位+12号递增或随机的数字,类似这种。uuid长度过长,也不递增,使用受限。不过snowflake算法有个问题就是服务器时间回拨的问题,就是时间可能不准,这个时候不能停止发号,我觉得可以采取的方式是:每个服务器存储最新的一个maxNewId,起个线程监控服务器时间是否正确,不正确就从maxNewId递增1获取,同事调准服务器时间,直到服务器时间正确。作者回复: 应该可行
2019-12-2020- 程序水果宝老师说如果我们发现系统时钟不准,就可以让发号器暂时拒绝发号,直到时钟准确为止。我们的程序本身就是运行在系统中的,如何来判断系统中的时间是否准确呢?
作者回复: 可以暂时记录上次发好的时间,然后和这次的时间比较
2019-10-09518  张珂老师好,想了解部署一套snowflake,性能怎么样?还有一个问题是,发号器虽然可以保证递增发号,但写入数据库时(假设有两个事务要写同一个表),那对于底层B+树也不一定顺序写入,无法利用磁盘顺序写的性能优化吧?
张珂老师好,想了解部署一套snowflake,性能怎么样?还有一个问题是,发号器虽然可以保证递增发号,但写入数据库时(假设有两个事务要写同一个表),那对于底层B+树也不一定顺序写入,无法利用磁盘顺序写的性能优化吧?作者回复: 性能在单实例单核可以达到2亿万次每秒 发号器一般是改的redis
2020-01-2128 小喵喵但是当数据库分库分表后,使用自增字段就无法保证 ID 的全局唯一性了? 1.使用数据库的自增,设置起始值和步长不一样,不是一样可以实现吗? 2.预估每天的数据量,预先生成ID存入缓存(比如Redis)里面,然后去取,这种方法也简单?
小喵喵但是当数据库分库分表后,使用自增字段就无法保证 ID 的全局唯一性了? 1.使用数据库的自增,设置起始值和步长不一样,不是一样可以实现吗? 2.预估每天的数据量,预先生成ID存入缓存(比如Redis)里面,然后去取,这种方法也简单?作者回复: 其实很难预估数据量,某一天有活动咋办?不同的起始值也可,只是增加人工成本,增加了库表咋办?忘了设置咋办?
2019-10-0937 Lane老师我有疑问:中间的机器ID,同一毫秒内,3号机器先注册了一个用户,1号机器再注册一个用户。这样的话也不是顺序的了。
Lane老师我有疑问:中间的机器ID,同一毫秒内,3号机器先注册了一个用户,1号机器再注册一个用户。这样的话也不是顺序的了。作者回复: 是的,如果是独立部署的话就可以保证了
2020-01-3135 长期规划老师,序列号占12位,对应序列号最大值4096,如果一毫秒内请求生成唯一键的次数大于此值怎么办呢?我能想到的办法是当生成的序列号达到4096时,延时1毫秒,再生成。实际中,是这样处理吗?
长期规划老师,序列号占12位,对应序列号最大值4096,如果一毫秒内请求生成唯一键的次数大于此值怎么办呢?我能想到的办法是当生成的序列号达到4096时,延时1毫秒,再生成。实际中,是这样处理吗?作者回复: 会发这么多号吗……
2019-10-225 王肖武snowflake不能保证单调递增吧?首先,服务器的时钟可能有快有慢;其次,同一时刻,机器号大的机器生成的ID总是大于机器号小的机器,但他的请求可能是先到达了数据库。个人观点:主键还是要用数据库的自增id,另外再加个全局唯一的code作为业务主键。
王肖武snowflake不能保证单调递增吧?首先,服务器的时钟可能有快有慢;其次,同一时刻,机器号大的机器生成的ID总是大于机器号小的机器,但他的请求可能是先到达了数据库。个人观点:主键还是要用数据库的自增id,另外再加个全局唯一的code作为业务主键。作者回复: 首先,服务器的时钟一般是对时的 其次,如果是单独部署的发号器,没有机器ID是可以保证单调递增的
2019-10-1255 stg609假设通过容器化来部署发号器,且同时会有多个发号器容器运行,那这个 worker Id 如何生成。容器自身的 id 是一串很长的16进制,无法转换为 worker id 吧?难道也需要引入 zookeeper 吗?有没有其他简单可行的方案?
stg609假设通过容器化来部署发号器,且同时会有多个发号器容器运行,那这个 worker Id 如何生成。容器自身的 id 是一串很长的16进制,无法转换为 worker id 吧?难道也需要引入 zookeeper 吗?有没有其他简单可行的方案?作者回复: 容器ID太长了。。。 其实引入zk也还好,对于zk是弱依赖,只是启动的时候拉一下机器ID
2019-10-0925 jimmysnowflake方案中 现在一般公司都有容器虚拟化,所以每个实例都有自己的实例ID,以此作为唯一ID即可,另外保险起见在服务启动的时候可以向其他启动的服务发送check请求,确保ID全局唯一,这样可以不引入zk,让系统更简单些~
jimmysnowflake方案中 现在一般公司都有容器虚拟化,所以每个实例都有自己的实例ID,以此作为唯一ID即可,另外保险起见在服务启动的时候可以向其他启动的服务发送check请求,确保ID全局唯一,这样可以不引入zk,让系统更简单些~作者回复: 容器ID太长了吧,比较占发号器的位数
2019-10-095 helloworld老师,有相关的示例代码不?我的理解是每一个毫秒将下41时间戳加1,10位的机器不变,12的序列号先随机生成一个数字,然后再在这个基础上生成这一毫秒所需要的全局id的数量。不知道我理解的对不对。打卡09.
helloworld老师,有相关的示例代码不?我的理解是每一个毫秒将下41时间戳加1,10位的机器不变,12的序列号先随机生成一个数字,然后再在这个基础上生成这一毫秒所需要的全局id的数量。不知道我理解的对不对。打卡09.作者回复: 是的,没错
2019-10-2124

