

09 | 数据库优化方案(二):写入数据量增加时,如何实现分库分表?

该思维导图由 AI 生成,仅供参考
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

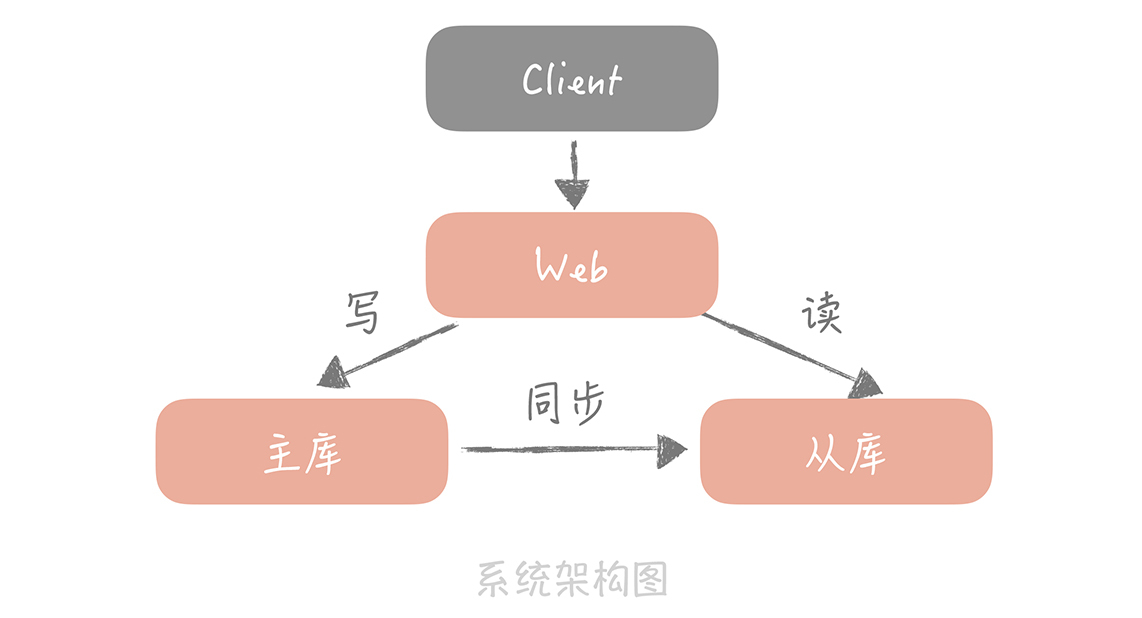
数据库优化方案(二):写入数据量增加时,如何实现分库分表? 本文介绍了在面对写入数据量增加时,如何实现分库分表来优化数据库的方案。文章首先介绍了在高并发下数据库的优化方案:读写分离,通过主从复制技术实现数据复制为多份,增强了数据库的抵抗大量并发读请求的能力。然后,文章列举了在面对大量写入请求时需要考虑的问题,包括数据量增加导致的查询性能下降、磁盘空间占用增加、不同模块数据存储在同一主库中导致的故障隔离问题等。为了解决这些问题,文章提出了对数据进行分片的解决方案,即分库分表。 在介绍分库分表的基本思想后,文章详细讨论了垂直拆分和水平拆分两种分库分表的方式。垂直拆分是将数据库的表按业务类型拆分到不同的数据库中,实现了专库专用的原则,解决了不同业务数据存储在同一主库中的故障隔离问题。而水平拆分则是将数据拆分到多个数据库和数据表中,解决了某一业务库数据量暴增的问题。 总的来说,文章通过介绍分库分表的方式,帮助读者了解了在面对大量写入请求时,如何通过分片来分摊数据库的读写压力,解决存储瓶颈和提升数据查询性能的问题。文章还强调了在实施分库分表时需要注意的问题,帮助读者避免在实践中踩坑。文章内容深入浅出,对分库分表技术进行了全面的介绍,对于需要优化数据库写入性能的读者具有很高的参考价值。
《高并发系统设计 40 问》,新⼈⾸单¥59

全部留言(89)
- 最新
- 精选
 每天晒白牙主要内容梳理 写入请求量大会造成性能和可用性的问题,如何应对呢? 采取对数据进行"分片",这是一种思想,在数据库中就是分库分表,Kafka中是分区,ES中是分片 分库分表的思想是根据某种分配策略把数据尽量均匀的分到多个数据库节点或多个表中,这样每个数据库节点和表都只存储部分数据,这样对数据的存储、读和写都有意义 存储:因为分库分表后每个节点和表只存储部分数据,这样就能解决数据存储的瓶颈 读:因为每个节点和表存储部分数据,数据量变小,可以提升查询性能 写:数据写入被分摊到多个节点和表,写入性能提高 分库分表有两种方式:垂直拆分和水平拆分 垂直拆分的关注点在业务相关性,原则是按照业务拆分,核心思想是专库专用,将业务耦合度高的拆分到单独库中 水平拆分是把单一数据库按照某种规则拆分到多个数据库和多个数据表中,关注点在数据的特点 水平拆分的两种方法 1.根据某个字段的hash值拆分 比如想把用户表拆成16库64表,方案如下 先对id进行hash操作hash(id),这样有助于打散数据 然后对16取余 hash(id)%16,这样就得到了分库后的索引 最后对64取余 hash(id)%16%64,这样就得到了分表后的索引值 2.根据某个字段的区间或范围拆分 可以根据时间拆分 引入分库分表确实有很多优点,但也会引入新的问题 1.引入了分区分表键,也叫分区键 因为我们需要对分区键进行hash进行索引,这样就导致我们查询都要带上该分区键,比较好的解决办法是用id做分区键,但是如果有根据用户昵称查询的需求怎么办呢? 解决办法就是建立一个昵称和id的映射表 2.一些数据库的特性的实现变得困难 (1)夸库join不可用 解决办法是在业务代码中做处理 (2)求count 采取第三方组件例如redis实现 课后思考题 大数据的存储组件一般都涉及数据分片技术 例如Kafka的分区,ES的分片等等 拿Kafka的分区来举例 Kafka会对消息的key进行hash然后对分区数量取模,这样就得到了topic对应的分区索引 疑问点 1.老师我想请教下就是多库join的问题,如果采用在业务代码中进行处理不太妥吧,数据量太大了,如果有分页或排序的需求,这是要把各个库的数据都查出来,在内存中进行操作,这样会想当耗费内存,且性能低,老师有啥好办法吗? 2.如果一个订单库采用了买家id做为分区键,这样查询买家的订单非常容易,那要查询卖家的订单是不是和文中根据昵称查询一样,建立一个卖家和买家的映射表解决? 3.文中老师说如果要做分库分表留言一次性做到位,但这样在开始会很浪费空间,所以一般公司还是会采取慢慢扩容的方式,这样就引入了不停机迁移数据的问题,针对这种情况,老师是怎么做的呢? 谢谢老师
每天晒白牙主要内容梳理 写入请求量大会造成性能和可用性的问题,如何应对呢? 采取对数据进行"分片",这是一种思想,在数据库中就是分库分表,Kafka中是分区,ES中是分片 分库分表的思想是根据某种分配策略把数据尽量均匀的分到多个数据库节点或多个表中,这样每个数据库节点和表都只存储部分数据,这样对数据的存储、读和写都有意义 存储:因为分库分表后每个节点和表只存储部分数据,这样就能解决数据存储的瓶颈 读:因为每个节点和表存储部分数据,数据量变小,可以提升查询性能 写:数据写入被分摊到多个节点和表,写入性能提高 分库分表有两种方式:垂直拆分和水平拆分 垂直拆分的关注点在业务相关性,原则是按照业务拆分,核心思想是专库专用,将业务耦合度高的拆分到单独库中 水平拆分是把单一数据库按照某种规则拆分到多个数据库和多个数据表中,关注点在数据的特点 水平拆分的两种方法 1.根据某个字段的hash值拆分 比如想把用户表拆成16库64表,方案如下 先对id进行hash操作hash(id),这样有助于打散数据 然后对16取余 hash(id)%16,这样就得到了分库后的索引 最后对64取余 hash(id)%16%64,这样就得到了分表后的索引值 2.根据某个字段的区间或范围拆分 可以根据时间拆分 引入分库分表确实有很多优点,但也会引入新的问题 1.引入了分区分表键,也叫分区键 因为我们需要对分区键进行hash进行索引,这样就导致我们查询都要带上该分区键,比较好的解决办法是用id做分区键,但是如果有根据用户昵称查询的需求怎么办呢? 解决办法就是建立一个昵称和id的映射表 2.一些数据库的特性的实现变得困难 (1)夸库join不可用 解决办法是在业务代码中做处理 (2)求count 采取第三方组件例如redis实现 课后思考题 大数据的存储组件一般都涉及数据分片技术 例如Kafka的分区,ES的分片等等 拿Kafka的分区来举例 Kafka会对消息的key进行hash然后对分区数量取模,这样就得到了topic对应的分区索引 疑问点 1.老师我想请教下就是多库join的问题,如果采用在业务代码中进行处理不太妥吧,数据量太大了,如果有分页或排序的需求,这是要把各个库的数据都查出来,在内存中进行操作,这样会想当耗费内存,且性能低,老师有啥好办法吗? 2.如果一个订单库采用了买家id做为分区键,这样查询买家的订单非常容易,那要查询卖家的订单是不是和文中根据昵称查询一样,建立一个卖家和买家的映射表解决? 3.文中老师说如果要做分库分表留言一次性做到位,但这样在开始会很浪费空间,所以一般公司还是会采取慢慢扩容的方式,这样就引入了不停机迁移数据的问题,针对这种情况,老师是怎么做的呢? 谢谢老师作者回复: 1.多表join一般不会是全量数据,是分页数据,所以只有一少部分 2.建议是订单ID分库分表,然后建立买家ID和卖家ID和订单ID的映射 3. 一般是先双写两个库,然后校验数据,然后灰度切读,最后全量切读
2019-10-071089 Xiang介绍一个 range+hash 分库分表的方案吧,分库分表?如何做到永不迁移数据和避免热点? https://mp.weixin.qq.com/s/QFlUPS8X0errMwpxdBMHvg
Xiang介绍一个 range+hash 分库分表的方案吧,分库分表?如何做到永不迁移数据和避免热点? https://mp.weixin.qq.com/s/QFlUPS8X0errMwpxdBMHvg作者回复: 👍
2020-02-221034 撒旦的堕落老师说的道理 我都明白 只是如果现在有一张上亿的表 并且存在特定属性更新 那么如何不停机 进行分库分表 有木有具体的实践
撒旦的堕落老师说的道理 我都明白 只是如果现在有一张上亿的表 并且存在特定属性更新 那么如何不停机 进行分库分表 有木有具体的实践作者回复: 可以搭建新的库之后,先在业务上双写,然后校验两边的数据,再灰度切读,再全量切读
2019-10-09629- 逍遥飞鹤如果是因读性能引起的分库分表,可考虑ES或MongoDB、HBase的数据重构方式,避免在MySQL做文章 如果是写性能引起的分库分表,可按老师上面的这些原则进行实践和改造
作者回复: 是的
2020-03-25419  正在减肥的胖籽。分库分表之后,对于app端查询的问题还比较好解决。但是后端运营系统查询就麻烦,比如订单分库分表后,运营系统查询订单的时候可能根据多维度查询,这种方案您在工作中是怎么去解决的?我现在的做法就是同步到es里面。用ES去查。
正在减肥的胖籽。分库分表之后,对于app端查询的问题还比较好解决。但是后端运营系统查询就麻烦,比如订单分库分表后,运营系统查询订单的时候可能根据多维度查询,这种方案您在工作中是怎么去解决的?我现在的做法就是同步到es里面。用ES去查。作者回复: 可以的,也可以同步到一个大库中,不过性能有点儿差
2019-10-09311 枫叶11公司小业务少时,不可能一开始就规划很多库和表(如16*64),就像很多项目开始都只有一个库,但是我们做架构时可以预先考虑到后面可能会分库分表。请问老师,能不能讲一下最开始设计数据库时需要为今后分库分表考虑哪些因素,和一旦扩容后数据迁移的方案和注意点。谢谢。
枫叶11公司小业务少时,不可能一开始就规划很多库和表(如16*64),就像很多项目开始都只有一个库,但是我们做架构时可以预先考虑到后面可能会分库分表。请问老师,能不能讲一下最开始设计数据库时需要为今后分库分表考虑哪些因素,和一旦扩容后数据迁移的方案和注意点。谢谢。作者回复: 主要考虑数据的增长情况,数据迁移一般是先双写旧库和新库,然后校验数据,然后灰度切读,最后全量切读,注意点就是数据校验过程,会比较繁琐
2019-10-07511 Chocolate老师,请问下昵称和 ID 的映射表怎么建立,是按照昵称进行分库分表吗,即先查询这个昵称在哪个库哪个表,然后找到 ID,根据 ID 所在的库和表进行查询吗?
Chocolate老师,请问下昵称和 ID 的映射表怎么建立,是按照昵称进行分库分表吗,即先查询这个昵称在哪个库哪个表,然后找到 ID,根据 ID 所在的库和表进行查询吗?作者回复: 是的,没错
2019-10-0759 深深的人老师查询conut怎么做冗余,那种有where条件的
深深的人老师查询conut怎么做冗余,那种有where条件的作者回复: 可以考虑用es
2019-10-156
 黑暗浪子这个东西能不用就不用。毕竟很多老系统还有超多join操作,你一开始分库分表,所有代码都要重写。我倒觉得换es,mongodb是个好思路
黑暗浪子这个东西能不用就不用。毕竟很多老系统还有超多join操作,你一开始分库分表,所有代码都要重写。我倒觉得换es,mongodb是个好思路作者回复: 如果有运维能力也可
2019-10-1026 jc9090kkk感谢老师分享,对于分表有点疑问: 1.如果是用户信息表需要分表,数据量大的前提下,需要准备一个映射表来存储昵称+uid的对应关系,文中提到了映射表也可以做分库分表,基本的思路是什么?用户在做登录相关操作的时候,都不知道昵称+uid的映射关系在哪张表中,难道是通过昵称算出hash值来确定分区键? 2.如果hash分表的策略又达到了瓶颈,需要更多的容量呢?基于对业务影响最小的方案是采用数据冗余+新的分区表还是重建分表规则做数据迁移?这一部分没有讲到哦,后面能否专门讲解下,一般应该是前者吧,因为后者在数据量大的情况下做一次数据迁移成本太高了? 3.对于文中提到的,16个库每个库中64张表,1024个张表,这个分表策略的理由是什么?个人感觉这个分表规则显得有些太浮夸了,因为有些业务压根用不到这么多表,甚至有时候分表操作是分表策略(局部分表)+当前模式(局部不分表)公用的方式来协调的,一步一步迭代过来的?不是很理解文中提到的这个策略的容量是如何计算出来的?如果数据量压根用不到这么多表,数据过于分散,对于管理和维护成本来讲有点小题大做了吧? 另外有一点,文中提到的总计数的问题,用redis存储的前提是当前的业务逻辑不是敏感的,用redis可以提升性能,如果是敏感业务的话,在更新数据库后还没有写入redis中的这个时间差,请求并发没办法估量和控制,所以最后的数据总量仅仅是最终的数据是一致的,但是逻辑是不一致的,核心原因是redis和mysql是属于不同的存储系统,无法做到两个系统公共支持一个分布式事物,无法拿到精确一致的视图,当然如果是非敏感业务,在保证性能的前提下,逻辑不一致可以容忍的话是可以考虑这种方案的。
jc9090kkk感谢老师分享,对于分表有点疑问: 1.如果是用户信息表需要分表,数据量大的前提下,需要准备一个映射表来存储昵称+uid的对应关系,文中提到了映射表也可以做分库分表,基本的思路是什么?用户在做登录相关操作的时候,都不知道昵称+uid的映射关系在哪张表中,难道是通过昵称算出hash值来确定分区键? 2.如果hash分表的策略又达到了瓶颈,需要更多的容量呢?基于对业务影响最小的方案是采用数据冗余+新的分区表还是重建分表规则做数据迁移?这一部分没有讲到哦,后面能否专门讲解下,一般应该是前者吧,因为后者在数据量大的情况下做一次数据迁移成本太高了? 3.对于文中提到的,16个库每个库中64张表,1024个张表,这个分表策略的理由是什么?个人感觉这个分表规则显得有些太浮夸了,因为有些业务压根用不到这么多表,甚至有时候分表操作是分表策略(局部分表)+当前模式(局部不分表)公用的方式来协调的,一步一步迭代过来的?不是很理解文中提到的这个策略的容量是如何计算出来的?如果数据量压根用不到这么多表,数据过于分散,对于管理和维护成本来讲有点小题大做了吧? 另外有一点,文中提到的总计数的问题,用redis存储的前提是当前的业务逻辑不是敏感的,用redis可以提升性能,如果是敏感业务的话,在更新数据库后还没有写入redis中的这个时间差,请求并发没办法估量和控制,所以最后的数据总量仅仅是最终的数据是一致的,但是逻辑是不一致的,核心原因是redis和mysql是属于不同的存储系统,无法做到两个系统公共支持一个分布式事物,无法拿到精确一致的视图,当然如果是非敏感业务,在保证性能的前提下,逻辑不一致可以容忍的话是可以考虑这种方案的。作者回复: 1. 是对昵称做hash,登陆的时候不需要知道昵称呀,可以针对手机号做hash,昵称是用来判断昵称是否存在 2. 不太清楚数据冗余 + 新的分区表的意思,是增加新的分区表吗?那么就要改分库分表的规则,那这样原先的数据就读不到了?是要做数据迁移? 3. 是需要一步步迭代,这里是说这些库表是足够了,如果业务没有那么大数据量,可以按照业务来 4. 计数是最终一致就好了
2019-10-0826

