

18 | 消息投递:如何保证消息仅仅被消费一次?
唐扬

该思维导图由 AI 生成,仅供参考
你好,我是唐扬。
通过上一节课,我们在电商系统中增加了消息队列对峰值写流量做削峰填谷,对次要的业务逻辑做异步处理,对不同的系统模块做解耦合。因为业务逻辑从同步代码中移除了,所以我们也要有相应的队列处理程序来处理消息、执行业务逻辑,这时你的系统架构变成了下面的样子:
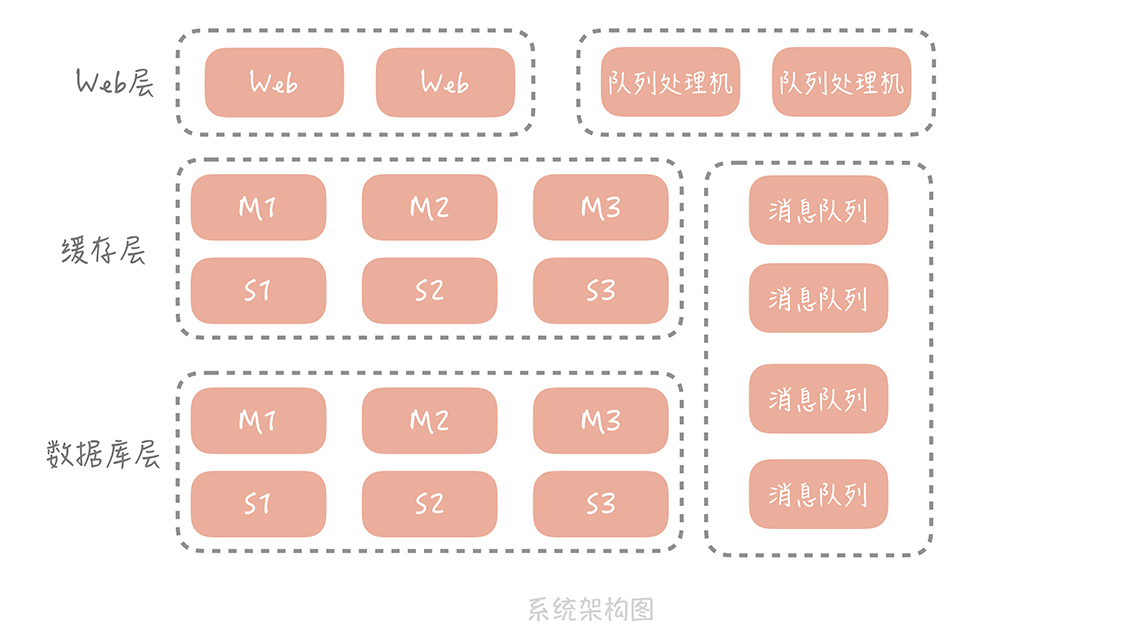
这是一个简化版的架构图,实际上,随着业务逻辑越来越复杂,会引入更多的外部系统和服务来解决业务上的问题。比如我们会引入 Elasticsearch 来解决商品和店铺搜索的问题,也会引入审核系统对售卖的商品、用户的评论做自动的和人工的审核,你会越来越多地使用消息队列与外部系统解耦合以及提升系统性能。
比如你的电商系统需要上一个新的红包功能:用户在购买一定数量的商品之后,由你的系统给用户发一个现金的红包鼓励用户消费。由于发放红包的过程不应该在购买商品的主流程之内,所以你考虑使用消息队列来异步处理。这时你发现了一个问题:如果消息在投递的过程中发生丢失,那么用户就会因为没有得到红包而投诉。相反,如果消息在投递的过程中出现了重复,你的系统就会因为发送两个红包而损失。
那么我们如何保证产生的消息一定会被消费到并且只被消费一次呢?这个问题虽然听起来很浅显、很好理解,但是实际上却藏着很多玄机,本节课我就带你深入探讨。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了消息投递过程中可能出现的问题及解决方案。首先从消息丢失的可能性出发,分析了消息生产、消息队列存储和消息消费三个环节可能出现的问题,并提出了相应的解决方案。在消息生产过程中,建议采用消息重传来应对网络抖动可能导致的消息丢失;在消息队列存储环节,通过集群部署和配置消息队列的同步刷盘策略来减少消息丢失的风险;在消息消费过程中,强调了更新消费进度的重要性,以避免消息丢失。此外,文章还探讨了如何保证消息只被消费一次的问题,强调了“幂等性”的重要性。在生产和消费过程中增加消息幂等性的保证,以及在消息重复的场景下,如何保证尽量不影响消息最终的处理结果也得到了详细阐述。文章最后指出,消息的丢失可以通过生产端的重试、消息队列配置集群模式以及消费端合理处理消费进度三种方式来解决,同时强调了方案设计需根据具体场景,不能一概而论。整体而言,本文对消息投递过程中的问题和解决方案进行了深入浅出的介绍,对需要处理消息队列的开发人员具有一定的参考价值。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《高并发系统设计 40 问》,新⼈⾸单¥59
《高并发系统设计 40 问》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(54)
- 最新
- 精选
 长期规划联想到MongoDB在写策略中有w和j两个参数,w对应同步多个从节点,j是刷journal到磁盘。看来存储系统的技术都差不多。一般设置w=majority就可以,j=false。跟kafka中老师的建议一样。Redis中也有AOF,不同存储系统解决问题不一样,但共性还是很多的。因为都要保证性能,可用性,数据一致性,只是每个存储系统侧重点不一样,Kafka是写性能,Redis是读性能,普通关系数据库是事务
长期规划联想到MongoDB在写策略中有w和j两个参数,w对应同步多个从节点,j是刷journal到磁盘。看来存储系统的技术都差不多。一般设置w=majority就可以,j=false。跟kafka中老师的建议一样。Redis中也有AOF,不同存储系统解决问题不一样,但共性还是很多的。因为都要保证性能,可用性,数据一致性,只是每个存储系统侧重点不一样,Kafka是写性能,Redis是读性能,普通关系数据库是事务作者回复: 👍
2019-12-2139 Ricky Fung消费端 消息处理的幂等性:1.增加去重表(通用);2.根据业务数据状态来判断(例如 订单支付后变更状态为已支付,如果订单当前状态已经为已支付则忽略此消息)。
Ricky Fung消费端 消息处理的幂等性:1.增加去重表(通用);2.根据业务数据状态来判断(例如 订单支付后变更状态为已支付,如果订单当前状态已经为已支付则忽略此消息)。作者回复: 赞~
2019-12-2428 黎我们目前是在消费消息后,将消息id(业务上定义的唯一标识)放入redis。消费前,先去redis查找,也算是业务上的一种防重复吧
黎我们目前是在消费消息后,将消息id(业务上定义的唯一标识)放入redis。消费前,先去redis查找,也算是业务上的一种防重复吧作者回复: 嗯那 这个也是的
2019-10-301425 钱消息发送的三种语义 1:至少发送一次,存在重复发送,但不会丢消息 2:之多发送一次,存在丢失消息,但不会重复发 3:仅且发送一次,最理想情况,但是很难做到 所以,大部分消息中间件都会采用1,这样就会出现重复发生消息的风险,需要做幂等处理,做幂等处理就必须有全局唯一值。 第一:利用消息的全局唯一值来做处理,比如:消息的key 第二:利用业务的全局唯一值来做处理,比如:数据库的主键或唯一键 怎么处理? 那么先查询,判断是否重复,然后再做处理 要么利用存储系统的特点,吞掉重复异常,比如:DB 或者加锁,加乐观锁,视具体业务来定 不过全局唯一值是少不了的,具体是什么?存储在哪里?是先查还是吞异常也看具体业务。 如果是数据库,先查再判断性能堪忧,最好采用唯一键,重复吞异常的方式。
钱消息发送的三种语义 1:至少发送一次,存在重复发送,但不会丢消息 2:之多发送一次,存在丢失消息,但不会重复发 3:仅且发送一次,最理想情况,但是很难做到 所以,大部分消息中间件都会采用1,这样就会出现重复发生消息的风险,需要做幂等处理,做幂等处理就必须有全局唯一值。 第一:利用消息的全局唯一值来做处理,比如:消息的key 第二:利用业务的全局唯一值来做处理,比如:数据库的主键或唯一键 怎么处理? 那么先查询,判断是否重复,然后再做处理 要么利用存储系统的特点,吞掉重复异常,比如:DB 或者加锁,加乐观锁,视具体业务来定 不过全局唯一值是少不了的,具体是什么?存储在哪里?是先查还是吞异常也看具体业务。 如果是数据库,先查再判断性能堪忧,最好采用唯一键,重复吞异常的方式。作者回复: 👍
2020-04-2518 发条橙子 。我们在生产环境中为了避免重复消费使用了全局唯一ID的方式,每次业务逻辑前都会从库中查一下。但是会出现两条消息瞬时并发处理问题,这时事务都没提交所以都查不到。这时可以用老师说的版本乐观锁来解决 , 我们目前的方式是增加了分布式锁
发条橙子 。我们在生产环境中为了避免重复消费使用了全局唯一ID的方式,每次业务逻辑前都会从库中查一下。但是会出现两条消息瞬时并发处理问题,这时事务都没提交所以都查不到。这时可以用老师说的版本乐观锁来解决 , 我们目前的方式是增加了分布式锁作者回复: 👍
2019-12-15711 阿杜生产者判重交给消息中间件自行处理,加判重表。消费端的重复消费通过分布式锁控制,过期时间可以放长些。
阿杜生产者判重交给消息中间件自行处理,加判重表。消费端的重复消费通过分布式锁控制,过期时间可以放长些。作者回复: 👍
2019-12-2138 寒溪看了老师整个课程,知识体系非常全面且深入。但是mq这块儿有一个很重要的方面没有设计,mq消息乱序的问题,想知道老师工作中是怎么处理这个问题的。
寒溪看了老师整个课程,知识体系非常全面且深入。但是mq这块儿有一个很重要的方面没有设计,mq消息乱序的问题,想知道老师工作中是怎么处理这个问题的。作者回复: 有一个办法是可以把相关的数据写入到同一个partition
2019-12-3136 Lane推荐使用多副本而不是每次刷盘。我不太理解,难道每次都刷盘(flush),性能应该比每次都要多次网络调用要强得多啊(备份同步)
Lane推荐使用多副本而不是每次刷盘。我不太理解,难道每次都刷盘(flush),性能应该比每次都要多次网络调用要强得多啊(备份同步)作者回复: 从性能数据看,网络调用耗时要比磁盘写入耗时低
2020-02-0245 罗力友消息队列的服务端会存储 < 生产者 ID,最后一条消息 ID> 的映射。当某一个生产者产生新的消息时,消息队列服务端会比对消息 ID 是否与存储的最后一条 ID 一致,如果一致,就认为是重复的消息,服务端会自动丢弃。 老师,只校验最后一条ID应该不能完全保证消息不重复吧?
罗力友消息队列的服务端会存储 < 生产者 ID,最后一条消息 ID> 的映射。当某一个生产者产生新的消息时,消息队列服务端会比对消息 ID 是否与存储的最后一条 ID 一致,如果一致,就认为是重复的消息,服务端会自动丢弃。 老师,只校验最后一条ID应该不能完全保证消息不重复吧?作者回复: 如果每条消息生产时都使用发号器发一个唯一的号就好了
2019-10-3134 高源老师请教一个问题,例如我开发个服务端程序,我想知道我开发的服务程序性能指标,怎么得的,例如机器配置 cpu有i3 i5的那个更适合怎么测试出来的,另外qps吞吐率等这些都是用工具测试的吗😊
高源老师请教一个问题,例如我开发个服务端程序,我想知道我开发的服务程序性能指标,怎么得的,例如机器配置 cpu有i3 i5的那个更适合怎么测试出来的,另外qps吞吐率等这些都是用工具测试的吗😊作者回复: 用哪种机器都可以,只是你在出性能报告的时候需要说明机器的配置:) qps的话一般会收集访问日志来统计,后面我讲到监控时会提到的
2019-10-3023
收起评论

