

08 | 数据库优化方案(一):查询请求增加时,如何做主从分离?
唐扬

该思维导图由 AI 生成,仅供参考
你好,我是唐扬。
上节课,我们用池化技术解决了数据库连接复用的问题,这时,你的垂直电商系统虽然整体架构上没有变化,但是和数据库交互的过程有了变化,在你的 Web 工程和数据库之间增加了数据库连接池,减少了频繁创建连接的成本,从上节课的测试来看性能上可以提升 80%。现在的架构图如下所示:
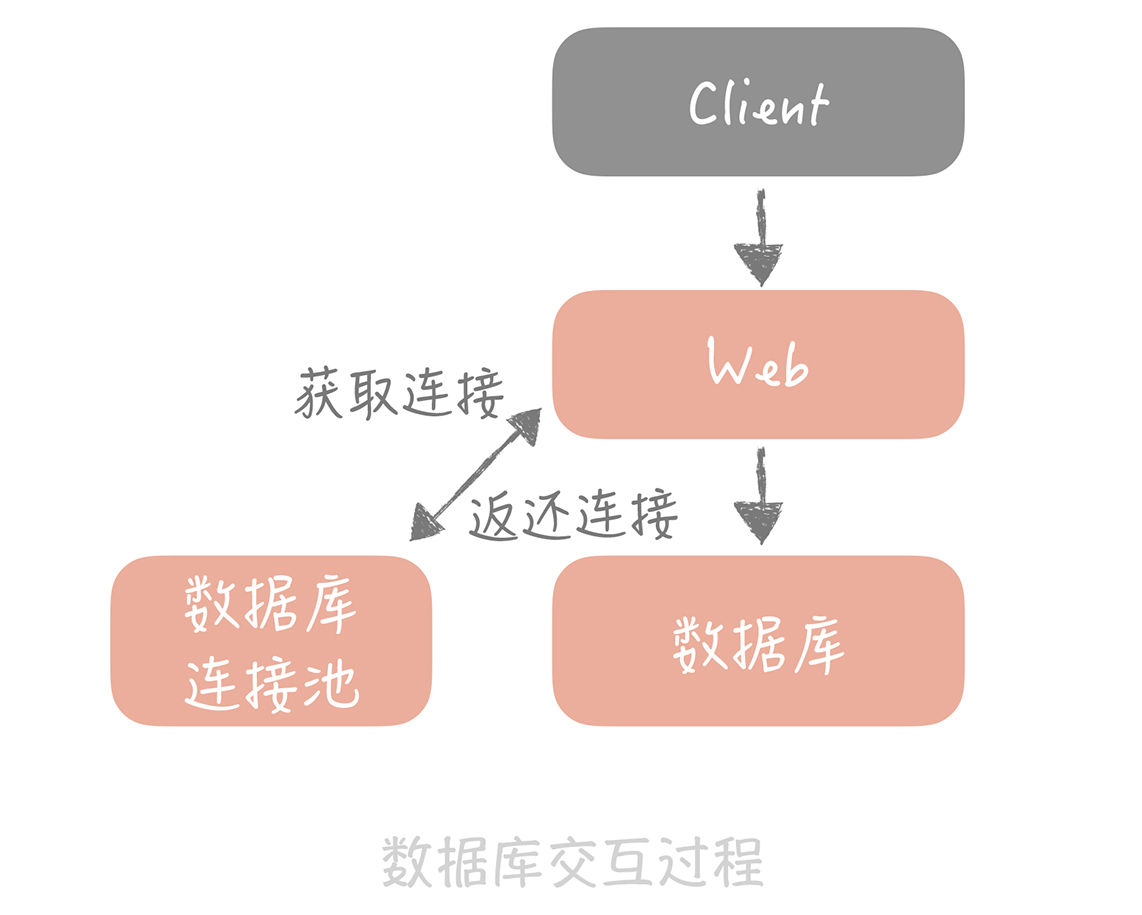
此时,你的数据库还是单机部署,依据一些云厂商的 Benchmark 的结果,在 4 核 8G 的机器上运行 MySQL 5.7 时,大概可以支撑 500 的 TPS 和 10000 的 QPS。这时,运营负责人说正在准备双十一活动,并且公司层面会继续投入资金在全渠道进行推广,这无疑会引发查询量骤然增加的问题。那么今天,我们就一起来看看当查询请求增加时,应该如何做主从分离来解决问题。
主从读写分离
其实,大部分系统的访问模型是读多写少,读写请求量的差距可能达到几个数量级。
这很好理解,刷朋友圈的请求量肯定比发朋友圈的量大,淘宝上一个商品的浏览量也肯定远大于它的下单量。因此,我们优先考虑数据库如何抵抗更高的查询请求,那么首先你需要把读写流量区分开,因为这样才方便针对读流量做单独的扩展,这就是我们所说的主从读写分离。
它其实是个流量分离的问题,就好比道路交通管制一样,一个四车道的大马路划出三个车道给领导外宾通过,另外一个车道给我们使用,优先保证领导先行,就是这个道理。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

主从分离及主从复制技术在处理增加的数据库查询请求方面具有重要意义。通过主从读写分离,可以有效分离数据库的读写流量,优先处理查询请求。主从复制是实现主从读写分离的关键技术,通过记录数据库变化并保存在磁盘上,实现主从数据的一致性。部署多个从库共同承担读流量,可以抵御较高的并发读流量。然而,主从同步延迟可能对业务产生影响,需要采取数据冗余、缓存和查询主库等解决方案。此外,文章还介绍了数据库中间件的两类解决方案,以及在使用中间件时需要深入了解其特性。总的来说,主从复制技术不仅适用于数据库,还可以应用于其他存储组件,提升系统可用性和性能。文章提供了对于读者快速了解主从分离及主从复制技术的概览,以及相关技术特点的详细介绍。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《高并发系统设计 40 问》,新⼈⾸单¥59
《高并发系统设计 40 问》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(73)
- 最新
- 精选
 老男孩置顶我觉得进入演进篇以后干货越来越多了。关于理论基础大家都能泛泛的谈一谈,可具体落地实操,老师的经验和能力就体现出来了。关于读写分离,主从同步延时出现的诡异现象,我之前也遇到过。我之前项目最开始没有只是配置了2个数据源,由开发人员选择写主库,读存库。后来发现很多读操作也放到主库上了,理由就是在一些场景下会出现诡异的数据不一致。于是,使用了mycat做代理,开发是比以前方便了,但诡异问题依然存在,又换成了atlas,还是不行。就如同老师说的一样,在没有完全深入了解组件的情况下贸然使用,本来是玩组件,结果被组件玩了。没办法,只好把查询放到一个事务里边,这样代理就会去主库中执行,但这样无异于还是增加的主库的压力。老师在专栏中提供基于消息队列和缓存的方案给我很好的启发,期待后续更多干货。2019-10-09560
老男孩置顶我觉得进入演进篇以后干货越来越多了。关于理论基础大家都能泛泛的谈一谈,可具体落地实操,老师的经验和能力就体现出来了。关于读写分离,主从同步延时出现的诡异现象,我之前也遇到过。我之前项目最开始没有只是配置了2个数据源,由开发人员选择写主库,读存库。后来发现很多读操作也放到主库上了,理由就是在一些场景下会出现诡异的数据不一致。于是,使用了mycat做代理,开发是比以前方便了,但诡异问题依然存在,又换成了atlas,还是不行。就如同老师说的一样,在没有完全深入了解组件的情况下贸然使用,本来是玩组件,结果被组件玩了。没办法,只好把查询放到一个事务里边,这样代理就会去主库中执行,但这样无异于还是增加的主库的压力。老师在专栏中提供基于消息队列和缓存的方案给我很好的启发,期待后续更多干货。2019-10-09560- 被过去推开老师你好,我以前想要给公司分库分表,后来觉得有几个问题放在我面前,就搁浅了,现在只是挂了一个从库。 最主要的问题:我们公司每天产生许多业务订单,如果以用户id进行hash计算,分发到不同的库,对前台用户订单查询有利,但后台系统页面需要查看全部订单,以倒序排列,这样子的sql会不会执行很慢,毕竟是订单分散到几个库了。老师有好的分库分表方案吗?
作者回复: 后台系统不能直接查询分库分表的数据,可以把数据同步到单独的一个后台库中,或者同步到es里面
2019-11-271133  Hwan老师,为啥优先读写分离,然后再缓存呢,是从那方面考虑的呢
Hwan老师,为啥优先读写分离,然后再缓存呢,是从那方面考虑的呢作者回复: 从开发和维护的难度考虑。引入缓存会引入复杂度,你要考虑缓存数据一致性,穿透,防雪崩等问题,并且也多维护一类组件
2019-10-29324
 无形之前发生过的一个问题,用Redis主从同步,写入Redis的数据量太大,没加频次控制,导致每秒几十万写入,主从延迟过大,运维频频报警,在主库不挂掉的情况下,这样大量写入会不会造成数据丢失?
无形之前发生过的一个问题,用Redis主从同步,写入Redis的数据量太大,没加频次控制,导致每秒几十万写入,主从延迟过大,运维频频报警,在主库不挂掉的情况下,这样大量写入会不会造成数据丢失?作者回复: 之前遇到过 如果主从延迟很大,数据会堆积到redis主库的发送缓冲区,会导致主库oom
2019-11-01321 _Axios丶靜ﻩ老师你好数据库的qps可以使用什么工具来监控
_Axios丶靜ﻩ老师你好数据库的qps可以使用什么工具来监控作者回复: open falcon
2019-10-3019 metasearch总结 1 主从原理:主库通过同步binlog到从库,relaylog去读 2 从库有延迟可以通过缓存 冗余数据来解决 3 4核8g TPS 500 QPS 10000
metasearch总结 1 主从原理:主库通过同步binlog到从库,relaylog去读 2 从库有延迟可以通过缓存 冗余数据来解决 3 4核8g TPS 500 QPS 10000作者回复: 👍
2019-10-06518 helloworld给主从复制增加延迟告警的思路很好,另外,老师能具体讲解下QPS和TPS的区别?网上查询了很多资料没有权威的解释。感谢!打卡08
helloworld给主从复制增加延迟告警的思路很好,另外,老师能具体讲解下QPS和TPS的区别?网上查询了很多资料没有权威的解释。感谢!打卡08作者回复: 我理解的QPS是每秒查询数,是针对读请求的 TPS是每秒执行事务数,倾向于写请求
2019-10-08616 张珂老师你好,我想讲我之前的一个面试,面试官问存储层的高可用怎么搞。 我是这么回答的:存储用最熟悉的MySQL,架起主备,主备前用keepalive + VIP漂移,可以达到秒级切换。主从复制选用半同步复制,保证数据从binlog传输到备库后再返回请求。当主库发生异常时,需要切换,但需要备库应用完本地的relay log后才能成为主库。在这之前不能写,读的话会有少量不一致性。 面试官说:半同步复制可能延时有点大,而且你还相当于“停服”了。说说改成异步复制呢? 我针对异步复制,先分析了一下当主库挂的时候,可能会丢失一些数据。这个时候可以立即切换到备库成为主库,但影响是原主库挂之前一些提交的事务都丢失了,对于业务来说可能表现成用户做了某件事但结果却没做,比如支付了订单但后来发现没有该订单,而且余额也没少。这个时候要做好产品上的公告,表明事故以及让用户重新支付等。而且原主库要做好binlog上跳过那些跟原备库(现在的主库)不一致的部分。但这个方案依然需要等待备库应用完本地的relay log完毕才能切,只要没有长事务,一般很快。 面试官又在更高机房的层次上,提出让我设计一个方案,做到一定的“可伸缩”性,。比如A机房挂了,流量切到B机房,机房可以做到一变二,二变三等,这个时候系统的实战细节等。 这个地方我实在缺乏经验,我的回答是这样的:如果启用多个机房分别服务不同的用户群,想要达到流量切换,势必需要互相同步数据,但这里有个时间窗口不一致的问题,如果A机房挂了,马上切给B,依然采用刚才的思路,没有同步过来的数据算作“没有产生过”,业务有损。这样起码可以保证数据本身的一致性。 上面的三条回答面试官有些不满意,就结束了面试。老师您能帮我看看评价一下我的回答,看是否还有更好的方案?
张珂老师你好,我想讲我之前的一个面试,面试官问存储层的高可用怎么搞。 我是这么回答的:存储用最熟悉的MySQL,架起主备,主备前用keepalive + VIP漂移,可以达到秒级切换。主从复制选用半同步复制,保证数据从binlog传输到备库后再返回请求。当主库发生异常时,需要切换,但需要备库应用完本地的relay log后才能成为主库。在这之前不能写,读的话会有少量不一致性。 面试官说:半同步复制可能延时有点大,而且你还相当于“停服”了。说说改成异步复制呢? 我针对异步复制,先分析了一下当主库挂的时候,可能会丢失一些数据。这个时候可以立即切换到备库成为主库,但影响是原主库挂之前一些提交的事务都丢失了,对于业务来说可能表现成用户做了某件事但结果却没做,比如支付了订单但后来发现没有该订单,而且余额也没少。这个时候要做好产品上的公告,表明事故以及让用户重新支付等。而且原主库要做好binlog上跳过那些跟原备库(现在的主库)不一致的部分。但这个方案依然需要等待备库应用完本地的relay log完毕才能切,只要没有长事务,一般很快。 面试官又在更高机房的层次上,提出让我设计一个方案,做到一定的“可伸缩”性,。比如A机房挂了,流量切到B机房,机房可以做到一变二,二变三等,这个时候系统的实战细节等。 这个地方我实在缺乏经验,我的回答是这样的:如果启用多个机房分别服务不同的用户群,想要达到流量切换,势必需要互相同步数据,但这里有个时间窗口不一致的问题,如果A机房挂了,马上切给B,依然采用刚才的思路,没有同步过来的数据算作“没有产生过”,业务有损。这样起码可以保证数据本身的一致性。 上面的三条回答面试官有些不满意,就结束了面试。老师您能帮我看看评价一下我的回答,看是否还有更好的方案?作者回复: 其实我觉得对于数据库切换的回答是没有啥问题的 多机房最主要的是数据的用户延迟,一般会自建一些工具
2020-01-2168 Adrian文章里说通过冗余数据来解决主从延迟的问题,我有些异议,这种方式会造成缺乏扩展性,消息承载的数据很多消息组件都会有字节大小的限制,这样的话,如果后续数据量随着业务进行了扩展,就难免不会产生问题,持续扩展能力相对较差,我的理解倒是可以通过消息重试的方式来解决这个问题,如果主从同步延迟,那就消息重试,直到数据同步过来即可,这种解决方案通常业务上也是能忍受的,当然还是要按照具体case具体分析
Adrian文章里说通过冗余数据来解决主从延迟的问题,我有些异议,这种方式会造成缺乏扩展性,消息承载的数据很多消息组件都会有字节大小的限制,这样的话,如果后续数据量随着业务进行了扩展,就难免不会产生问题,持续扩展能力相对较差,我的理解倒是可以通过消息重试的方式来解决这个问题,如果主从同步延迟,那就消息重试,直到数据同步过来即可,这种解决方案通常业务上也是能忍受的,当然还是要按照具体case具体分析作者回复: 一般使用的比较多的是种缓存 重试其实用处不大,因为你不知道获取的数据究竟是不是延迟的数据
2019-12-2128 三年过后老师讲得很好!案例说到主从的延迟时间预警,未能详细到如何通过哪个数据库中的哪个指标来判别?经验中,我记得是,在从从库中,通过监控show slave status\G命令输出的Seconds_Behind_Master参数的值来判断,是否有发生主从延时。这个参数值是通过比较sql_thread执行的event的timestamp和io_thread复制好的 event的timestamp(简写为ts)进行比较,而得到的这么一个差值。 但是,问题来了,如果复制同步主库bin_log日志的io_thread线程负载过高的话,那么,Seconds_Behind_Master这个值就一直处于0。也是无法预警的,确切地说,通过Seconds_Behind_Master这个值来判断延迟是不够准确的。 不知,还有其他更好的方式?
三年过后老师讲得很好!案例说到主从的延迟时间预警,未能详细到如何通过哪个数据库中的哪个指标来判别?经验中,我记得是,在从从库中,通过监控show slave status\G命令输出的Seconds_Behind_Master参数的值来判断,是否有发生主从延时。这个参数值是通过比较sql_thread执行的event的timestamp和io_thread复制好的 event的timestamp(简写为ts)进行比较,而得到的这么一个差值。 但是,问题来了,如果复制同步主库bin_log日志的io_thread线程负载过高的话,那么,Seconds_Behind_Master这个值就一直处于0。也是无法预警的,确切地说,通过Seconds_Behind_Master这个值来判断延迟是不够准确的。 不知,还有其他更好的方式?作者回复: 印象中可以通过比对master和slave的bin log位置
2019-10-048
收起评论

