

12 | 缓存:数据库成为瓶颈后,动态数据的查询要如何加速?
唐扬

该思维导图由 AI 生成,仅供参考
你好,我是唐扬。
通过前面数据库篇的学习,你已经了解了在高并发大流量下,数据库层的演进过程以及库表设计上的考虑点。你的垂直电商系统在完成了对数据库的主从分离和分库分表之后,已经可以支撑十几万 DAU 了,整体系统的架构也变成了下面这样:
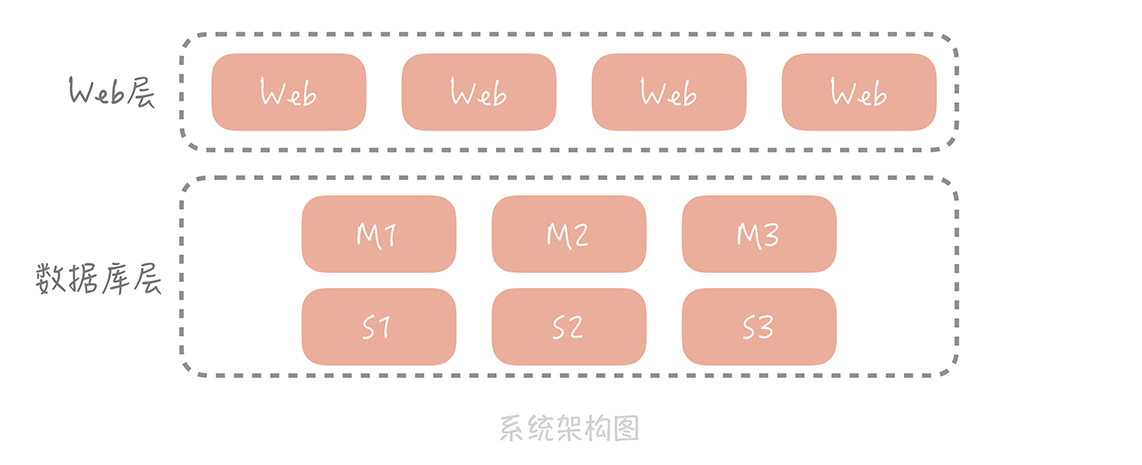
从整体上看,数据库分成了主库和从库,数据也被切分到多个数据库节点上。但随着并发的增加,存储数据量的增多,数据库的磁盘 IO 逐渐成了系统的瓶颈,我们需要一种访问更快的组件来降低请求响应时间,提升整体系统性能。这时我们就会使用缓存。那么什么是缓存,我们又该如何将它的优势最大化呢?
本节课是缓存篇的总纲,我将从缓存定义、缓存分类和缓存优势劣势三个方面全方位带你掌握缓存的设计思想和理念,再用剩下 4 节课的时间,带你针对性地掌握使用缓存的正确姿势,以便让你在实际工作中能够更好地使用缓存提升整体系统的性能。
接下来,让我们进入今天的课程吧!
什么是缓存
缓存,是一种存储数据的组件,它的作用是让对数据的请求更快地返回。
我们经常会把缓存放在内存中来存储, 所以有人就把内存和缓存画上了等号,这完全是外行人的见解。作为业内人士,你要知道在某些场景下我们可能还会使用 SSD 作为冷数据的缓存。比如说 360 开源的 Pika 就是使用 SSD 存储数据解决 Redis 的容量瓶颈的。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

缓存在系统性能优化中扮演着重要角色。本文介绍了缓存的定义、分类和优劣势,以及在不同场景下的应用。静态缓存、分布式缓存和热点本地缓存是常见的缓存类型,分别适用于不同的数据访问需求。静态缓存适合缓存静态数据,而分布式缓存则能应对动态请求,而热点本地缓存则用于阻挡热点查询对分布式缓存节点或数据库的压力。文章还指出了缓存的不足之处,如适用场景受限、复杂度增加、数据不一致风险以及运维成本。然而,尽管存在这些不足,缓存对性能提升的作用是不可否认的。读者需要理解缓存不仅是一种组件,更是一种设计思想,能够加速读请求的组件和设计方案都是缓存思想的体现。在实际工作中,当遇到性能问题时,缓存是首要考虑的解决方案。整体而言,本文通过生动的案例和简洁明了的语言,帮助读者快速了解了缓存的概念及其在系统性能优化中的重要作用。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《高并发系统设计 40 问》,新⼈⾸单¥59
《高并发系统设计 40 问》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(37)
- 最新
- 精选
- 被过去推开方便面那个比喻好评。缓存和缓冲区对应的英语是cache和buffer,buffer的存在是为了解决数据不能一次性读写完成或某次的数据量太小,io成本又太高的折中方案
作者回复: 谢谢~
2019-11-27241  咻的一下涉及到排序分页的动态数据有没有什么好的缓存解决办法呢,比如外卖店铺首页,根据用户的配送距离进行排序分页显示,难道每个用户都缓存一份数据么,感觉缓存是不是不适用于这种场景
咻的一下涉及到排序分页的动态数据有没有什么好的缓存解决办法呢,比如外卖店铺首页,根据用户的配送距离进行排序分页显示,难道每个用户都缓存一份数据么,感觉缓存是不是不适用于这种场景作者回复: redis支持geohash,应该可以解决这个问题
2019-12-25525 高志强老师,热点本地缓存使用组件 Guava Cache ,这个东西能存多大量呢,感觉像一个数据库,还有个问题一直困扰我,像股票之类的app页面数据时时刷新,这个是怎么做到的,是否用了缓存如何使用的缓存呢,希望老师能给解答,谢谢~
高志强老师,热点本地缓存使用组件 Guava Cache ,这个东西能存多大量呢,感觉像一个数据库,还有个问题一直困扰我,像股票之类的app页面数据时时刷新,这个是怎么做到的,是否用了缓存如何使用的缓存呢,希望老师能给解答,谢谢~作者回复: 1.guava cache本身没有限制,注意看存大量是否对gc有影响 2. 股票的话,应该有分布式缓存,但是这个缓存更新频率高,需要用队列削峰填谷
2019-10-151021 钱浅显易懂,缓存目前是标配之一(互联网开发三剑客:RPC/MQ/REDIS),凡是需要提速的地方,也许缓存就能排上用场,至少缓存的思想必然会被用上。 好处:服务提速 坏处:数据不一致风险,引入复杂度。 原则,简单优先,能不用就不用,实在不行就需要好好考虑一凡了,缓存穿透怎么解决?缓存击穿怎么解决?缓存雪崩怎么解决?数据不一致性问题怎么解决?数据结构众多怎么选择合适的数据结构?缓存的key:value怎么设计?缓存怎么加载?过期时间怎么设置?补偿机制怎么设计?缓存具体选择什么方案?需不需要多层缓存?多层缓存的复杂度怎么控制? 希望,后面有提及这些,不过这些对于面试用处不大,面试会问各种底层结构?以及怎么优化的?怎么选择某种数据结构的?所有的一切,都是为了高性能而存在。
钱浅显易懂,缓存目前是标配之一(互联网开发三剑客:RPC/MQ/REDIS),凡是需要提速的地方,也许缓存就能排上用场,至少缓存的思想必然会被用上。 好处:服务提速 坏处:数据不一致风险,引入复杂度。 原则,简单优先,能不用就不用,实在不行就需要好好考虑一凡了,缓存穿透怎么解决?缓存击穿怎么解决?缓存雪崩怎么解决?数据不一致性问题怎么解决?数据结构众多怎么选择合适的数据结构?缓存的key:value怎么设计?缓存怎么加载?过期时间怎么设置?补偿机制怎么设计?缓存具体选择什么方案?需不需要多层缓存?多层缓存的复杂度怎么控制? 希望,后面有提及这些,不过这些对于面试用处不大,面试会问各种底层结构?以及怎么优化的?怎么选择某种数据结构的?所有的一切,都是为了高性能而存在。作者回复: 是的,缓存使用简单,但是深入难
2020-04-21314 fomy感谢老师的分享,让我知道了Java中可以使用Guava cache和Ehcache实现缓存过期的,也是对HashMap的一种补充吧。 有个问题问一下:缓存的命中率一般怎么统计的?有什么开源工具或者框架吗?
fomy感谢老师的分享,让我知道了Java中可以使用Guava cache和Ehcache实现缓存过期的,也是对HashMap的一种补充吧。 有个问题问一下:缓存的命中率一般怎么统计的?有什么开源工具或者框架吗?作者回复: guava cache可以打印统计信息的
2019-11-1914 👽没有达到需要引用缓存需要的情况下,尽量不要过早使用缓存。 缓存的坑很多,并且维护成本极高。在处理缓存的适合需要多考虑很多问题。 曾经碰到这样的情况: 调用别人写的查询服务,但是查找到的数据却迟迟无法更新为最新数据。最后,重新写了直接查库的接口,才解决问题。 并且,缓存如果频繁更新,频繁失效 反而会带来性能的消耗。 再带上杨晓峰老师的一句话:“过早的优化是万恶之源"
👽没有达到需要引用缓存需要的情况下,尽量不要过早使用缓存。 缓存的坑很多,并且维护成本极高。在处理缓存的适合需要多考虑很多问题。 曾经碰到这样的情况: 调用别人写的查询服务,但是查找到的数据却迟迟无法更新为最新数据。最后,重新写了直接查库的接口,才解决问题。 并且,缓存如果频繁更新,频繁失效 反而会带来性能的消耗。 再带上杨晓峰老师的一句话:“过早的优化是万恶之源"作者回复: 是的
2019-10-177 lofaith老师,热点缓存是存在本地内存之中吗,后台的列表数据有很多查询条件还有分页这种,能用缓存吗,如果能用,老师有什么好的缓存方案吗
lofaith老师,热点缓存是存在本地内存之中吗,后台的列表数据有很多查询条件还有分页这种,能用缓存吗,如果能用,老师有什么好的缓存方案吗作者回复: 有做过这种keylist的存储,一般要么缓存整体,要么缓存前几页的热点数据
2020-03-2726 尔冬橙老师您说的缓存挡在上层是,这里的上层下层是指?我记得网络分层应用层是最上层
尔冬橙老师您说的缓存挡在上层是,这里的上层下层是指?我记得网络分层应用层是最上层作者回复: 我们认为越靠近用户的 越是上层,比如nginx在应用的上层,缓存在数据库的上层
2020-01-315 helloworld接@饭团的疑问,当涉及到更新数据库时,如何保证数据库和缓存的一致性?通过在代码中加入逻辑判断或者是异常捕获从而确认当第一步更新成功后,再进行第二步?希望老师能给出稍微具体一点点的建议。感谢
helloworld接@饭团的疑问,当涉及到更新数据库时,如何保证数据库和缓存的一致性?通过在代码中加入逻辑判断或者是异常捕获从而确认当第一步更新成功后,再进行第二步?希望老师能给出稍微具体一点点的建议。感谢作者回复: 可以参考一下缓存的cache aside使用方式,或者保证最终一致性
2019-10-2845 Keep-Moving#### 缓存的分类 * 静态缓存 * 分布式缓存 * 热点本地缓存 #### 缓存的不足 * 适用手读多写入的场景,并且数据最好有一定的热点属性 * 缓存会使系统更复杂,并且带来数据不一致的风险 * 缓存通常使用内存作为存储介质,但内存是有限的 * 缓存会增加运维的成本
Keep-Moving#### 缓存的分类 * 静态缓存 * 分布式缓存 * 热点本地缓存 #### 缓存的不足 * 适用手读多写入的场景,并且数据最好有一定的热点属性 * 缓存会使系统更复杂,并且带来数据不一致的风险 * 缓存通常使用内存作为存储介质,但内存是有限的 * 缓存会增加运维的成本作者回复: 👍
2019-10-145
收起评论

