

14 | 缓存的使用姿势(二):缓存如何做到高可用?
唐扬

该思维导图由 AI 生成,仅供参考
你好,我是唐扬。
前面几节课,我带你了解了缓存的原理、分类以及常用缓存的使用技巧。我们开始用缓存承担大部分的读压力,从而缓解数据库的查询压力,在提升性能的同时保证系统的稳定性。这时,你的电商系统整体的架构演变成下图的样子:
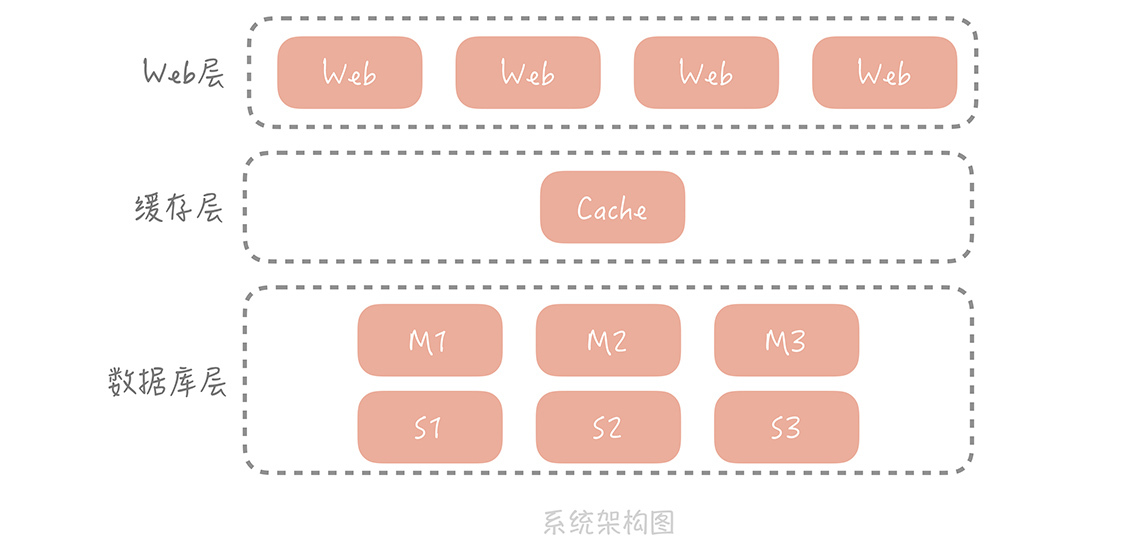
我们在 Web 层和数据库层之间增加了缓存层,请求会首先查询缓存,只有当缓存中没有需要的数据时才会查询数据库。
在这里,你需要关注缓存命中率这个指标(缓存命中率 = 命中缓存的请求数 / 总请求数)。一般来说,在你的电商系统中,核心缓存的命中率需要维持在 99% 甚至是 99.9%,哪怕下降 1%,系统都会遭受毁灭性的打击。
这绝不是危言耸听,我们来计算一下。假设系统的 QPS 是 10000/s,每次调用会访问 10 次缓存或者数据库中的数据,那么当缓存命中率仅仅减少 1%,数据库每秒就会增加 10000 * 10 * 1% = 1000 次请求。而一般来说我们单个 MySQL 节点的读请求量峰值就在 1500/s 左右,增加的这 1000 次请求很可能会给数据库造成极大的冲击。
命中率仅仅下降 1% 造成的影响就如此可怕,更不要说缓存节点故障了。而图中单点部署的缓存节点就成了整体系统中最大的隐患,那我们要如何来解决这个问题,提升缓存的可用性呢?
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了电商系统中缓存高可用性的重要性以及解决方案。首先强调了缓存命中率对系统稳定性的重要性,即使1%的下降也可能对系统造成毁灭性打击。针对缓存高可用性问题,文章提出了三大类高可用方案:客户端方案、中间代理层方案和服务端方案。客户端方案通过配置多个缓存节点实现分布式,中间代理层方案在应用代码和缓存节点之间增加代理层,内置高可用策略,而服务端方案则是Redis Sentinel方案。此外,文章还探讨了客户端方案中的数据分片和一致性Hash算法、Memcached的主从机制以及引入多副本层的实现。对于中间代理层方案和服务端方案也进行了详细的介绍和分析。最后,文章总结了分布式缓存的三种方案各自的优缺点,并指出具体的选择应根据团队的实际情况而定。 总的来说,本文内容深入浅出,为读者提供了解决缓存高可用性问题的实用方案,涵盖了客户端方案、中间代理层方案和服务端方案,帮助读者快速了解缓存高可用性的重要性以及解决方案。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《高并发系统设计 40 问》,新⼈⾸单¥59
《高并发系统设计 40 问》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(56)
- 最新
- 精选
 👽大概总结了一下: 实现高可用的核心依旧是集群。多个缓存节点,提高容错率。 客户端实现:由客户端的策略决定如何写缓存,如何读缓存。性能高,但是逻辑复杂,无法跨平台。 中间件实现:所有客户端先访问中间件,然后中间件决定了缓存策略。因为引入了中间件,所以性能较差,但是可以跨平台,并且有能力的公司还可以自研中间件。 服务端实现:主从切换由服务端实现。最大的缺点是增加了运维成本。 不知道我的理解是否正确。
👽大概总结了一下: 实现高可用的核心依旧是集群。多个缓存节点,提高容错率。 客户端实现:由客户端的策略决定如何写缓存,如何读缓存。性能高,但是逻辑复杂,无法跨平台。 中间件实现:所有客户端先访问中间件,然后中间件决定了缓存策略。因为引入了中间件,所以性能较差,但是可以跨平台,并且有能力的公司还可以自研中间件。 服务端实现:主从切换由服务端实现。最大的缺点是增加了运维成本。 不知道我的理解是否正确。作者回复: 是的👍
2019-10-2245 钱高可用的设计思路没有其他的核心就是增加副本,针对数据就增加数据副本,针对服务就增加服务副本,针对机房就增加机房副本,增加副本引入的新问题是数据不一致性,下面各种算法什么的都是为了解决因增加副本而带来的数据不一致性问题或者节点挂了怎么使服务继续可用的策略。比如:数据怎么迁移?故障怎么隔离?故障节点恢复后怎么是否加入?怎么加入?最近热上了看火影,影分术就是鸣人的高可用方式,其他的高可用思路和这个如出一辙。从动漫中也可以看出,这个需要更多能量,对公司而言,需要更多机器和存储空间,技术复杂度也会增加一些,幸好有现成的组件避免人人都重复造轮子的资源浪费。
钱高可用的设计思路没有其他的核心就是增加副本,针对数据就增加数据副本,针对服务就增加服务副本,针对机房就增加机房副本,增加副本引入的新问题是数据不一致性,下面各种算法什么的都是为了解决因增加副本而带来的数据不一致性问题或者节点挂了怎么使服务继续可用的策略。比如:数据怎么迁移?故障怎么隔离?故障节点恢复后怎么是否加入?怎么加入?最近热上了看火影,影分术就是鸣人的高可用方式,其他的高可用思路和这个如出一辙。从动漫中也可以看出,这个需要更多能量,对公司而言,需要更多机器和存储空间,技术复杂度也会增加一些,幸好有现成的组件避免人人都重复造轮子的资源浪费。作者回复: 👍
2020-04-24518 长期规划老师,您之前说4核8G的机器上,MySQL最高支撑QPS为1万,怎样本文开头又说MySQL读峰值才1500/s呢
长期规划老师,您之前说4核8G的机器上,MySQL最高支撑QPS为1万,怎样本文开头又说MySQL读峰值才1500/s呢作者回复: 1万是基准测试的结果,在实际中sql更复杂,达不到这个性能
2019-10-24416 longslee
longslee 打卡。 老师好,提问:一致性Hash中,比如存在A(k1)、B(k2)、C(k3),3个节点,括号中为分配的Key,假如B节点剔除了,那么k2会漂移到C节点。 那么此时客户端请求get k2的时候,是被计算好从C节点获取呢,还是完全就拿不到需要去数据库查?如果是从C节点获取,那感觉命中率完全没有下降。 这一点确实没搞清楚,忘老师解惑,谢谢🙏
打卡。 老师好,提问:一致性Hash中,比如存在A(k1)、B(k2)、C(k3),3个节点,括号中为分配的Key,假如B节点剔除了,那么k2会漂移到C节点。 那么此时客户端请求get k2的时候,是被计算好从C节点获取呢,还是完全就拿不到需要去数据库查?如果是从C节点获取,那感觉命中率完全没有下降。 这一点确实没搞清楚,忘老师解惑,谢谢🙏作者回复: 1. 如果B节点剔除,那么K2的读写都会到C节点上 2. 命中率会下降,因为B节点没有被删除的时候,C节点上是没有K2数据的。B节点剔除后,第一次从C节点获取K2数据是要穿透的
2019-10-18516- 👽另外就客户端和服务端的理解: 老实说一开始我也一脸懵逼。以为客户端就是用户端。 但是后来想通了。 应用服务器为用户提供数据接口,用户就是客户端,应用就是服务端。 但是缓存为应用服务器提供缓存服务,这时候对于缓存服务器来说应用服务器就是客户端,而缓存就是服务端。
作者回复: 是的 :)
2019-10-22410 - 长期规划老师,主从会有延迟,写入主库,但延迟同步到从库,在同步完成前去从库读数据,读不到,这如何解决呢
作者回复: 1. 写入的时候中缓存,这样从缓存里面读就实时了 2. 直接读主库
2019-12-1895 
 无形还没看完就想说一下我之前的做法,我们有两级缓存,服务器应用程序自身有一个内存缓存,再有Redis缓存,如果内存缓存没有命中,应用程序会创建一个单机的资源锁(go语言,用map+chan实现),大量请求进来,只有第一个请求会获取锁,其他请求获取锁失败,调用wait方法,等待第一个请求获取数据,第一个请求先从Redis中获取数据写入到内存缓存,Redis没有命中再读取MySQL,写会到Redis,执行结束后会通过close chan的方式广播消息,通知其他请求拿到了数据,从内存中读取数据,再释放锁。这样就解决了缓存穿透的问题,同一时刻,不论多大的并发量,真正到存储查询数据的请求只会有一个。
无形还没看完就想说一下我之前的做法,我们有两级缓存,服务器应用程序自身有一个内存缓存,再有Redis缓存,如果内存缓存没有命中,应用程序会创建一个单机的资源锁(go语言,用map+chan实现),大量请求进来,只有第一个请求会获取锁,其他请求获取锁失败,调用wait方法,等待第一个请求获取数据,第一个请求先从Redis中获取数据写入到内存缓存,Redis没有命中再读取MySQL,写会到Redis,执行结束后会通过close chan的方式广播消息,通知其他请求拿到了数据,从内存中读取数据,再释放锁。这样就解决了缓存穿透的问题,同一时刻,不论多大的并发量,真正到存储查询数据的请求只会有一个。作者回复: 其实更多的会在redis和mysql之间增加并发的控制,因为redis还是可以扛很好的并发的
2019-11-0495 阿卡牛老师,这个客户端方案中的客户端指哪里。一般我理解的客户端是浏览器或手机app...
阿卡牛老师,这个客户端方案中的客户端指哪里。一般我理解的客户端是浏览器或手机app...作者回复: 指的是你的应用服务器,是缓存的使用者
2019-10-294- kamida分片策略是怎么配置的呢 比如说客户端或者中间层怎么知道哪个node负责consistent hash ring上的key的?有zookeeper? 还有我记得sentinel不支持分片的吧
作者回复: 分片策略是由算法确定的
2020-03-2132 - 长期规划老师,Redis Cluster中使用了hash槽,我理解跟一致性hash其实是等价的,对吧。不过,Redis在分片间还实现了在新增节点时自动迁移数据
作者回复: 算法上不太一样哦
2019-12-1932
收起评论

