

21|正反馈和负反馈:如何将评估专家应用到大模型测评中?
蓝金伟

你好,我是金伟。
上节课说的数字孪生的数据质量好坏判断,是一个典型的符合预期 / 不符合预期的二值评估场景,那在大模型最核心的结果测评步骤里,基于私有 task 结合评估专家的评估则可以转为一个典型的二值倾向性评估。这个过程如何实现完全自动化呢?这就是这节课的主要内容了。
我们知道,一个 DPO 的倾向性评估意味着需要在两个输出之间选择倾向性,那对大模型结果而言,可以用前后两个版本的大模型输出比较,也可以在大模型输出和人类答案之间比较。这个问题的核心还是在测评算法的选择上。
评分算法
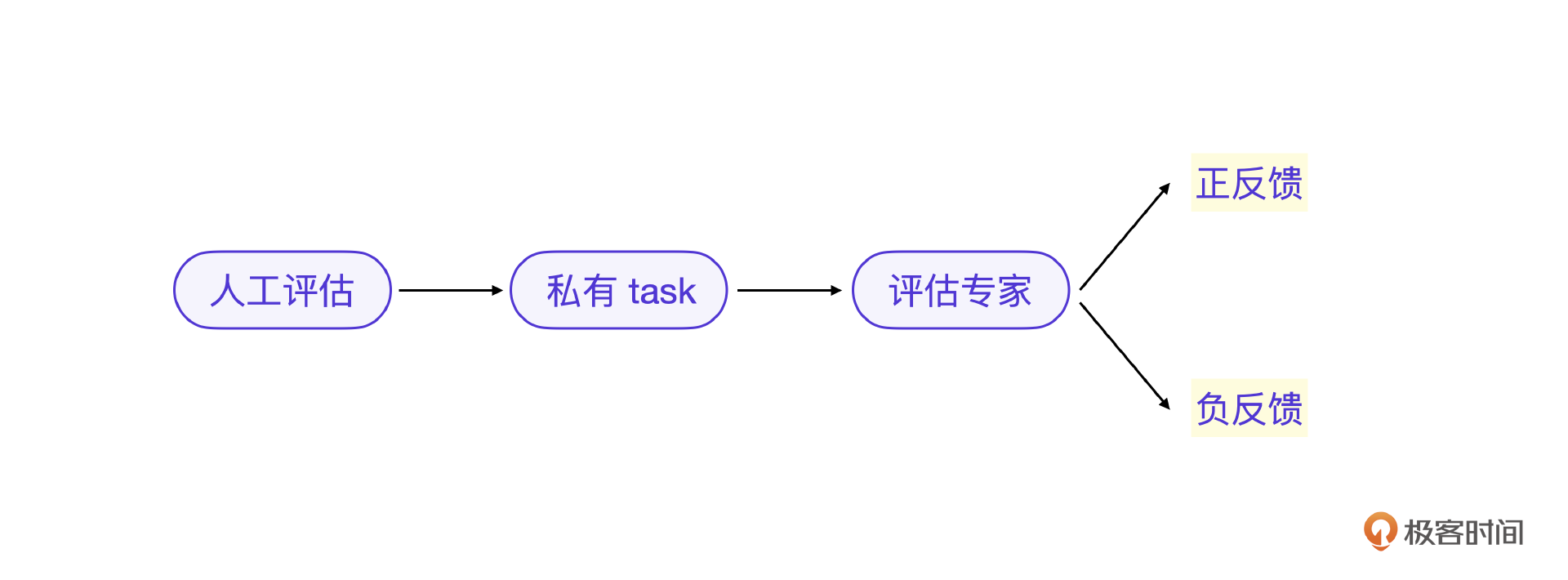
我们先来看一下不同的评估方法的核心原理。之前的课程提到,传统的大模型评估主要依赖人工评估的评分,人工评估就是对大模型训练完成后形成输出做出好和不好的打分,具体分值是 1 分和 0 分。
如果是评估专家来做评估,则是大模型替代人类评估判断,得出评分 1 还是 0。私有 task 传统的方式是用语义距离等算法来判断评分 1 还是 0,如果将语义距离算法改为评估专家算法,还是判断评分 1 还是 0。
这里的评分 1 就是正反馈,评分 0 就是负反馈。
当然,具体项目里的大模型评估要根据实际需求来做评分算法,也不都是 1 和 0 这样的二值评分。比如我们要微调的大模型能力是对文章的分类,那大模型的输出是一个明确的值,可以用 KTO 类的输出判断方法,也就是输出符合预期 / 不符合预期。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

1. 大模型评估中的正反馈和负反馈是指评估专家对模型输出进行判断,得出评分1或0。 2. 评分算法的选择取决于具体的大模型评估需求,可以采用不同的方法如语义距离算法、KTO类的输出判断方法、DPO的评估方法或RLHF的方法。 3. 对于客观问题的评估,可以采用私有task评估的过程,包括加载BLEU评估函数和计算整体BLEU分数。 4. 在实际工程中,大模型的输出和答案可能存在较大差异,因此需要对模型输出进行关键信息抽取,xFinder是一个解决这一问题的工具。 5. xFinder可以作为信息抽取算法使用,也可以作为整体评估工具来用,支持完全的评估整个结果。 6. xFinder的底层实际上是基于大模型针对信息抽取问题做的微调,可以通过提示词调用微调后的xFinder模型进行答案抽取。 7. xFinder的信息抽取可以提高评估算法的准确率,从而更准确地评估大模型的输出。 8. xFinder还可以作为整体评估工具来使用,是工程中常用的方法。 9. 在大模型评估中,评分只是第一步,真正的核心在于评分的统计细化,最好是多维度的分析不同类问题的评分变化,以便准确地反馈给大模型工程师进行进一步调整。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《AI 大模型项目落地实战》,新⼈⾸单¥59
《AI 大模型项目落地实战》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论