

28 | 知名大厂如何搭建大数据平台?
李智慧

该思维导图由 AI 生成,仅供参考
专栏第 26 期,我介绍了一个常规的大数据平台架构方案,这种架构方案是基于大数据平台 Lamda 架构进行设计的。事实上,业界也基本是按照这种架构模型搭建自己的大数据平台。
今天我们来看一下淘宝、美团和滴滴的大数据平台,一方面进一步学习大厂大数据平台的架构,另一方面也学习大厂的工程师如何画架构图。通过大厂的这些架构图,你就会发现,不但这些知名大厂的大数据平台设计方案大同小异,架构图的画法也有套路可以寻觅。
淘宝大数据平台
淘宝可能是中国互联网业界较早搭建了自己大数据平台的公司,下图是淘宝早期的 Hadoop 大数据平台,比较典型。
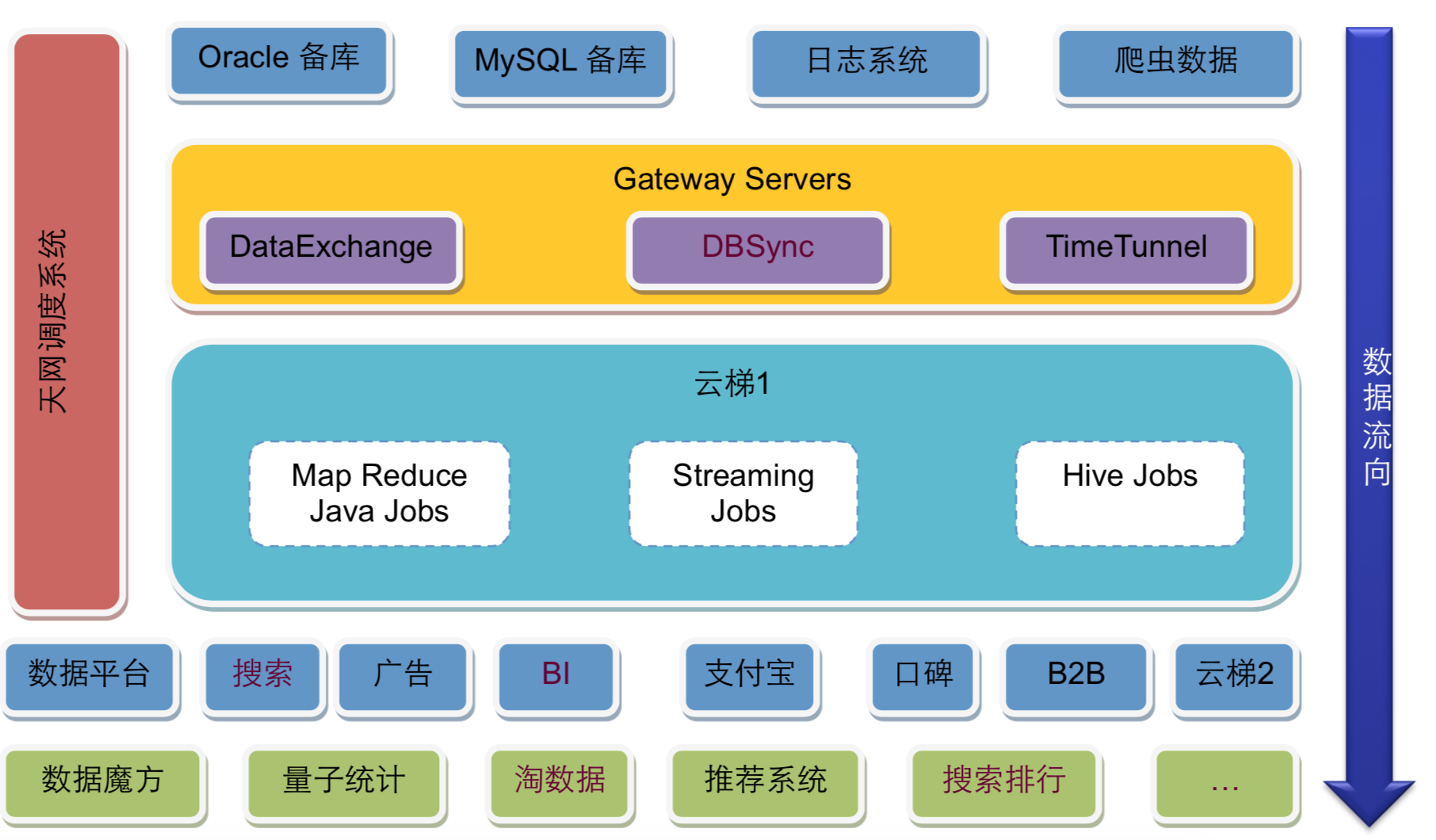
淘宝的大数据平台基本也是分成三个部分,上面是数据源与数据同步;中间是云梯 1,也就是淘宝的 Hadoop 大数据集群;下面是大数据的应用,使用大数据集群的计算结果。
数据源主要来自 Oracle 和 MySQL 的备库,以及日志系统和爬虫系统,这些数据通过数据同步网关服务器导入到 Hadoop 集群中。其中 DataExchange 非实时全量同步数据库数据,DBSync 实时同步数据库增量数据,TimeTunnel 实时同步日志和爬虫数据。数据全部写入到 HDFS 中。
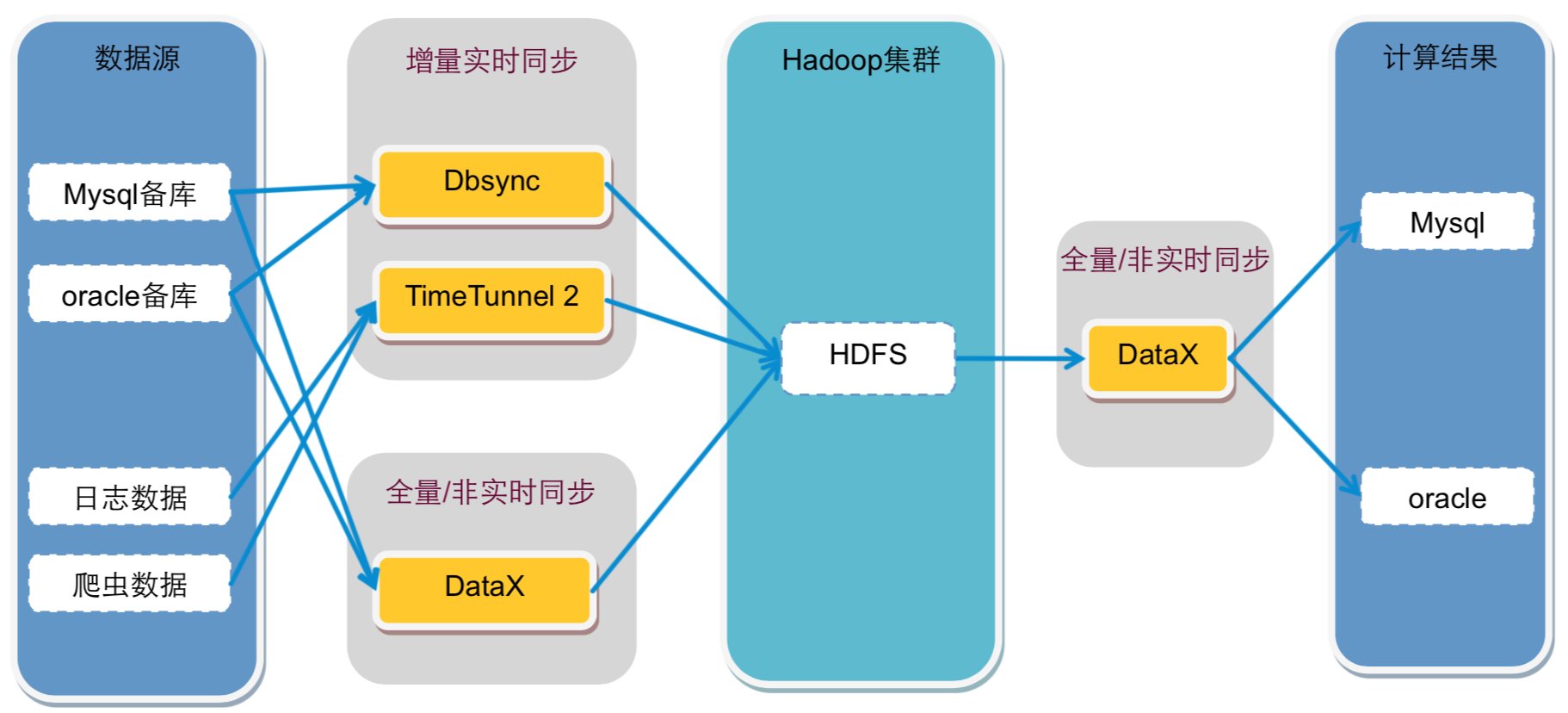
在 Hadoop 中的计算任务会通过天网调度系统,根据集群资源和作业优先级,调度作业的提交和执行。计算结果写入到 HDFS,再经过 DataExchange 同步到 MySQL 和 Oracle 数据库。处于平台下方的数据魔方、推荐系统等从数据库中读取数据,就可以实时响应用户的操作请求。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

知名大厂如淘宝、美团和滴滴在搭建大数据平台时,采用了类似的架构模型,基本分为数据源与数据同步、大数据计算集群和应用三个部分。以淘宝为例,其大数据平台主要包括数据源、Hadoop大数据集群和应用三部分,其中数据源主要来自Oracle和MySQL的备库,通过数据同步网关服务器导入到Hadoop集群中,计算任务通过天网调度系统进行调度执行。美团的大数据平台则通过Canal获取MySQL的binlog和Flume获取日志,数据经过Kafka后被流式计算和批处理计算两个引擎分别消费,最终结果输出到HBase或数据库。而滴滴的大数据平台则分为实时计算平台和离线计算平台,实时计算平台使用Kafka进行数据采集,输出到Spark Streaming或Flink进行清洗、转换、处理后记录到HDFS中,离线计算平台则基于Hadoop 2和Spark构建,使用自己的调度系统和开发系统。这些大厂的大数据平台架构虽有细微差异,但整体思路基本一致,都是根据各自场景和技术栈的不同进行调整,展现了大同小异的特点。这种相似性让人更加了解大数据平台架构,对架构师来说,提高编程水平的同时,多看架构设计文档、参加架构师技术大会也是很有帮助的。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《从 0 开始学大数据》,新⼈⾸单¥68
《从 0 开始学大数据》,新⼈⾸单¥68
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(17)
- 最新
- 精选
 西南偏北老师你好 我们公司是做互联网金融的,流处理需求很少,大多都是批处理之后生成的报表 每天基本上就是用sqoop增量的把MySQL中前一天的业务数据导入到hive。然后做一些业务上的报表计算,另外还有我负责的风控中请求的几个第三方数据,每天大概有五六十GB的样子,还有用户的通讯录数据等,以及一些相关报表的计算,数据量的话多的也就二三十亿条,离线计算都是Spark on yarn,调度系统是azkaban。 因为现在没有业务需求会用到hbase, 有很少的埋点数据,用kafka,Sparkstreaming处理一下。 感觉现在的那些批处理的东西都用的差不多了,天天觉得没啥有挑战的事情做,觉得心里挺空的,想过了年换工作,但是目前,各大公司也都在裁员,很是纠结。希望老师给点建议😁
西南偏北老师你好 我们公司是做互联网金融的,流处理需求很少,大多都是批处理之后生成的报表 每天基本上就是用sqoop增量的把MySQL中前一天的业务数据导入到hive。然后做一些业务上的报表计算,另外还有我负责的风控中请求的几个第三方数据,每天大概有五六十GB的样子,还有用户的通讯录数据等,以及一些相关报表的计算,数据量的话多的也就二三十亿条,离线计算都是Spark on yarn,调度系统是azkaban。 因为现在没有业务需求会用到hbase, 有很少的埋点数据,用kafka,Sparkstreaming处理一下。 感觉现在的那些批处理的东西都用的差不多了,天天觉得没啥有挑战的事情做,觉得心里挺空的,想过了年换工作,但是目前,各大公司也都在裁员,很是纠结。希望老师给点建议😁作者回复: 多了解业务,了解哪些业务的问题可以用大数据解决,走出去而不是等需求,多学习大数据的知识,扩展知识面,思考哪些大数据技术可以用到自己的工作中,会有很多机会的
2019-01-01347 鹿鸣老师你好,我所在的公司目前正在准备上大数据平台,我想请教下老师,关于这个平台的使用,是把数据导入到hdfs上 ,然后经过hive 等计算,再导出到数据库中吗?因为我们公司还准备用Kafka,还是把hive 计算好的数据直接导出到Kafka然后后续直接调用Kafka的数据呢?
鹿鸣老师你好,我所在的公司目前正在准备上大数据平台,我想请教下老师,关于这个平台的使用,是把数据导入到hdfs上 ,然后经过hive 等计算,再导出到数据库中吗?因为我们公司还准备用Kafka,还是把hive 计算好的数据直接导出到Kafka然后后续直接调用Kafka的数据呢?作者回复: hive的计算结果是一批数据,用Kafka导出似乎不是很合常理。
2020-02-051 小老鼠大数据实际工作中必须布署在云平台上吗
小老鼠大数据实际工作中必须布署在云平台上吗作者回复: 自己搭大数据集群也可以,数据量不大单机也可以。
2019-01-221 方得始终Apache Airflow是一个的编排,调度和监控工作流的开源工具。它的工作流设计是基于DAG,而且是用Python来编写,可以说是workflow as code。我目前正在学习使用。2019-01-0218
方得始终Apache Airflow是一个的编排,调度和监控工作流的开源工具。它的工作流设计是基于DAG,而且是用Python来编写,可以说是workflow as code。我目前正在学习使用。2019-01-0218 1请问老师,这些架构设计文档可以从哪些途径获得。2019-01-109
1请问老师,这些架构设计文档可以从哪些途径获得。2019-01-109 不记年腾讯大数据平台的数据来源于产品(应该还是日志数据和埋点数据),对数据的采集分为实时采集和离线采集(批处理),实时采集的数据经过流式计算后将结果写入数据仓库以及分发系统,离线采集是将数据写入数据仓库,经过批量计算后将结果写入分发系统。分发系统可以实时分发和批量分发以应对不同的业务需求。数据分析师通过BI分析库对离线大数据进行查看分析2020-03-185
不记年腾讯大数据平台的数据来源于产品(应该还是日志数据和埋点数据),对数据的采集分为实时采集和离线采集(批处理),实时采集的数据经过流式计算后将结果写入数据仓库以及分发系统,离线采集是将数据写入数据仓库,经过批量计算后将结果写入分发系统。分发系统可以实时分发和批量分发以应对不同的业务需求。数据分析师通过BI分析库对离线大数据进行查看分析2020-03-185 杰之7通过这一节的阅读,熟悉了各大互联网公司的大数据平台。大致模式是通过某种方式,对数据库中的数据进行提取,导入到大数据平台中,然后对数据平台的数据进行计算,返回可使用的数据。 对整个过程的调度和把控,淘宝、美团、滴滴各自用自身公司开发的调度管理系统,处理调度的优先级和执行顺序。 生活在今天这个时代,每个人都能享受这种数据智能的便捷,除了计算机本身的功能,更有一大批从事数据工作的人为我们提供了这样的服务。数据能如此精准,那同样我们对于我们的工作和生活,也应有像数据人那样,认真对待,这样才会工作之余更好的跟上数据智能时代的节奏,把握我们自身的生活。2019-01-015
杰之7通过这一节的阅读,熟悉了各大互联网公司的大数据平台。大致模式是通过某种方式,对数据库中的数据进行提取,导入到大数据平台中,然后对数据平台的数据进行计算,返回可使用的数据。 对整个过程的调度和把控,淘宝、美团、滴滴各自用自身公司开发的调度管理系统,处理调度的优先级和执行顺序。 生活在今天这个时代,每个人都能享受这种数据智能的便捷,除了计算机本身的功能,更有一大批从事数据工作的人为我们提供了这样的服务。数据能如此精准,那同样我们对于我们的工作和生活,也应有像数据人那样,认真对待,这样才会工作之余更好的跟上数据智能时代的节奏,把握我们自身的生活。2019-01-015 你为啥那么牛我司的架构也是这样,不过数据基本来自于终端信息采集,比如tbox、智能终端,涉及gps、车身发动机信息。每天数据最多达两三百G,19年的数据,今年应该会翻三五倍。数据通过tcp协议走网关处理,然后分发到kafka,再存入hbase,最新数据存redis。引入了spark进行批处理、流处理,分析结果存入mysql。历史数据直接查hbase,分析后的汇总数据查mysql。但是,hbase只能走key查询,对于业务组合字段查询难以为继,只能安排es了。任务调度系统还没上,只能人工介入。2021-03-073
你为啥那么牛我司的架构也是这样,不过数据基本来自于终端信息采集,比如tbox、智能终端,涉及gps、车身发动机信息。每天数据最多达两三百G,19年的数据,今年应该会翻三五倍。数据通过tcp协议走网关处理,然后分发到kafka,再存入hbase,最新数据存redis。引入了spark进行批处理、流处理,分析结果存入mysql。历史数据直接查hbase,分析后的汇总数据查mysql。但是,hbase只能走key查询,对于业务组合字段查询难以为继,只能安排es了。任务调度系统还没上,只能人工介入。2021-03-073 小桥流水可否推荐几款好的任务调度开源工具2019-01-0213
小桥流水可否推荐几款好的任务调度开源工具2019-01-0213 钱阅过留痕 大厂的大数据平台建设,数据的处理核心就三步:数据采集+数据处理+数据挖掘,具体到每一步实现的方式也许有所不同,但是这三步就类似三个接口一样,具体实现可以变化,不过本质就那样,不易变化。2020-02-101
钱阅过留痕 大厂的大数据平台建设,数据的处理核心就三步:数据采集+数据处理+数据挖掘,具体到每一步实现的方式也许有所不同,但是这三步就类似三个接口一样,具体实现可以变化,不过本质就那样,不易变化。2020-02-101
收起评论

