

26 | 互联网产品 + 大数据产品 = 大数据平台
李智慧

该思维导图由 AI 生成,仅供参考
从今天开始,我们进入专栏的“大数据平台与系统集成”模块。
前面我讲了各种大数据技术的原理与架构,大数据计算通过将可执行的代码分发到大规模的服务器集群上进行分布式计算,以处理大规模的数据,即所谓的移动计算比移动数据更划算。但是在分布式系统中分发执行代码并启动执行,这样的计算方式必然不会很快,即使在一个规模不太大的数据集上进行一次简单计算,MapReduce 也可能需要几分钟,Spark 快一点,也至少需要数秒的时间。
而互联网产品处理用户请求,需要毫秒级的响应,也就是说,要在 1 秒内完成计算,因此大数据计算必然不能实现这样的响应要求。但是互联网应用又需要使用大数据,实现统计分析、数据挖掘、关联推荐、用户画像等一系列功能。
那么如何才能弥补这互联网和大数据系统之间的差异呢?解决方案就是将面向用户的互联网产品和后台的大数据系统整合起来,也就是今天我要讲的构建一个大数据平台。
大数据平台,顾名思义就是整合网站应用和大数据系统之间的差异,将应用程序产生的数据导入到大数据系统,经过处理计算后再导出给应用程序使用。
下图是一个典型的互联网大数据平台的架构。
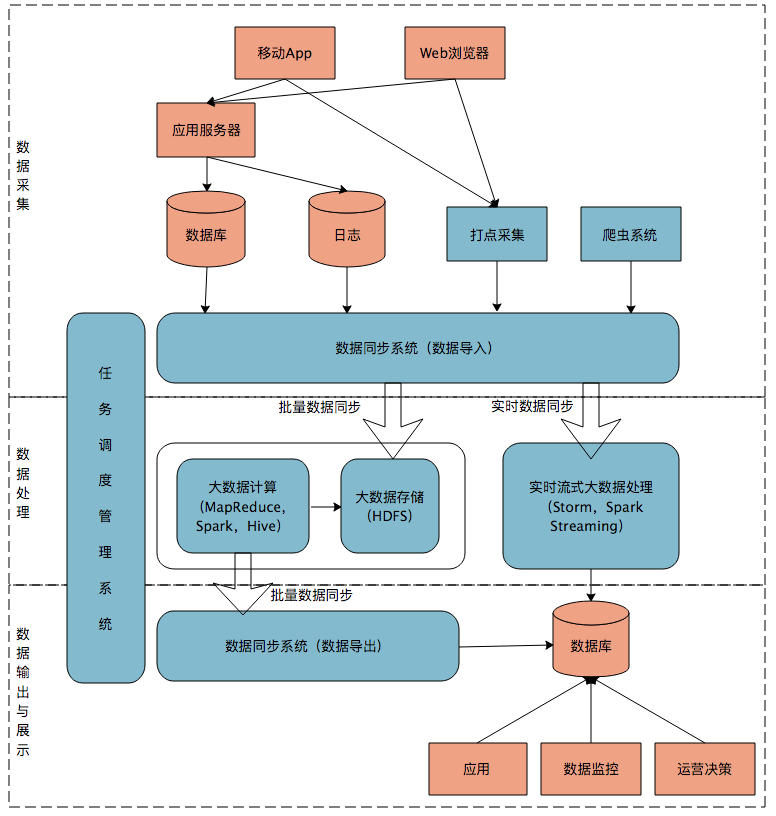
在这张架构图中,大数据平台里面向用户的在线业务处理组件用褐色标示出来,这部分是属于互联网在线应用的部分,其他蓝色的部分属于大数据相关组件,使用开源大数据产品或者自己开发相关大数据组件。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

大数据平台是互联网产品和大数据系统整合的解决方案,满足互联网应用对大数据的需求。该平台包括数据采集、处理、输出与展示三个部分。数据采集阶段通过多个系统将应用程序产生的数据同步到大数据系统中,经过格式化转换后通过消息队列传递。数据处理阶段将数据存储在HDFS,进行离线计算和流式计算,最终导出计算结果到数据库。数据输出与展示阶段实时展示数据给用户,并提供统计报告。任务调度管理系统起着整合作用,负责不同作业的调度和管理。文章还介绍了Lambda架构,即数据同时写入批处理大数据层和流处理大数据层,最终合并计算结果进行数据展示。大数据平台的架构原型方案为Lambda架构,是一种常规的大数据平台构建方案。文章还掴述了在线业务处理、离线数据处理、大数据流式计算等内容,强调大数据平台的粘合剂作用,将互联网线上产生的数据和大数据产品打通。文章提出了思考题,引导读者思考如何开展大数据平台开发工作,从资源申请、团队组织、跨部门协调、架构设计、开发进度、推广实施等多个维度进行思考。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《从 0 开始学大数据》,新⼈⾸单¥68
《从 0 开始学大数据》,新⼈⾸单¥68
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(15)
- 最新
- 精选
- Jack请问老师 采用cdh来搭建大数据平台是否一个好的选择
作者回复: 如果准备付费接受更多商业支持,cdh很好,如果服务器规模很小,cdh可以,如果不打算付费而服务器会持续增加,cdh不是合适
2018-12-2825  君侯如何定义或者区别所谓在线业务,离线业务,实时业务
君侯如何定义或者区别所谓在线业务,离线业务,实时业务作者回复: 用户请求需要即时响应的:在线业务,实时业务 不需要即时响应的:离线业务
2020-06-113- 西瓜一楼那位兄弟,你应该是把资源调度和任务调度的概念弄混了2018-12-2723
 纯洁的憎恶在工业上,很多大数据计算的结果,要应用到互联网产品中。然而前者的计算时长难以保证实时性,后者又有很高的响应及时性要求。于是需要找到一个途径,整合前后两端的差异,这就是大数据平台的使命。它从前端应用程序获取数据,倒入后台的大数据系统计算,再将结果返还给应用程序。由此大数据平台自上而下分为数据采集、数据处理、数据展示三个部分。 数据采集。数据采集的来源可能有数据库、日志、网络爬虫,不同来源的数据质量各异,日志与爬虫数据在导入前需要预处理(清洗、转化)。 数据处理。倒入大数据系统的数据被存储在分布式文件系统中(如HDFS),大数据批处理和产品离线计算保存在分布式文件系统中的被倒入数据,并将结果也写入分布式文件系统。大数据流处理产品计算输入数据并直接输出。 数据展示。大数据离线处理的计算结果存储在分布式文件系统中,无法被应用程序直接调用,需要同步后导出到数据库。 当然还需要一个任务调度系统将上述三部分组织起来。简单的调度策略按先后次序,复杂的要依据依赖关系(DAG图)。2018-12-3011
纯洁的憎恶在工业上,很多大数据计算的结果,要应用到互联网产品中。然而前者的计算时长难以保证实时性,后者又有很高的响应及时性要求。于是需要找到一个途径,整合前后两端的差异,这就是大数据平台的使命。它从前端应用程序获取数据,倒入后台的大数据系统计算,再将结果返还给应用程序。由此大数据平台自上而下分为数据采集、数据处理、数据展示三个部分。 数据采集。数据采集的来源可能有数据库、日志、网络爬虫,不同来源的数据质量各异,日志与爬虫数据在导入前需要预处理(清洗、转化)。 数据处理。倒入大数据系统的数据被存储在分布式文件系统中(如HDFS),大数据批处理和产品离线计算保存在分布式文件系统中的被倒入数据,并将结果也写入分布式文件系统。大数据流处理产品计算输入数据并直接输出。 数据展示。大数据离线处理的计算结果存储在分布式文件系统中,无法被应用程序直接调用,需要同步后导出到数据库。 当然还需要一个任务调度系统将上述三部分组织起来。简单的调度策略按先后次序,复杂的要依据依赖关系(DAG图)。2018-12-3011 笨小康1,日志同步可以理解为在app或web浏览器中部署埋点sdk,将埋点数据上报给应用服务器,应用服务器上的日志在经过 flume 接入到 HDFS。想问一下老师“打点采集”一般是在什么场景下会涉及到呢?又有什么方式实现“打点采集”? 2,我接触到的大数据平台中,有这样一种实现方式:日志同步通过 flume-agent 接入,然后打到 kafka,kafka 的数据同时供离线和实时计算消费,个人感觉这种方式的实时效果不一定会很好,请问老师怎么看待这种方式? 3,比较奇怪的是老师在资源调度系统里为啥没有提到 yarn,个人认为 crontab 只是决定任务的启动方式和时间,而真正做资源调度的应该主要是 yarn。2018-12-2725
笨小康1,日志同步可以理解为在app或web浏览器中部署埋点sdk,将埋点数据上报给应用服务器,应用服务器上的日志在经过 flume 接入到 HDFS。想问一下老师“打点采集”一般是在什么场景下会涉及到呢?又有什么方式实现“打点采集”? 2,我接触到的大数据平台中,有这样一种实现方式:日志同步通过 flume-agent 接入,然后打到 kafka,kafka 的数据同时供离线和实时计算消费,个人感觉这种方式的实时效果不一定会很好,请问老师怎么看待这种方式? 3,比较奇怪的是老师在资源调度系统里为啥没有提到 yarn,个人认为 crontab 只是决定任务的启动方式和时间,而真正做资源调度的应该主要是 yarn。2018-12-2725 special学习大数据将近一年,对Hadoop各种工具的特点、原理以及编程使用有较为全面的总结,大数据小白入门的好帮手。 欢迎关注公众号: 程序员的修身养性 一起交流学习!2018-12-284
special学习大数据将近一年,对Hadoop各种工具的特点、原理以及编程使用有较为全面的总结,大数据小白入门的好帮手。 欢迎关注公众号: 程序员的修身养性 一起交流学习!2018-12-284 达子不一般lamda给我的印象应该是java的lamda表达式,这个lamda架构貌似看不出来跟lamda本意有啥关联?2019-10-113
达子不一般lamda给我的印象应该是java的lamda表达式,这个lamda架构貌似看不出来跟lamda本意有啥关联?2019-10-113 哥们,走起!!老师,请问您是去哪找论文看的2018-12-313
哥们,走起!!老师,请问您是去哪找论文看的2018-12-313 杰之7通过这一节的学习,理解了互联网产品加大数据产品等于大数据平台。 整个大数据平台的流程图老师已经给我们展示,我理解的是通过用户对App或者是网页的使用产生的数据,通过服务器传输到数据库中,这样就有了数据的获取。接着通过数据同步系统将获取的数据导入大数据产品中进行计算处理。计算处理主要分两类,批处理和流式计算,两者结合可以将过去到此刻的数据处理完成。最后将处理好的数据导出到数据库中给用户或者相关人员使用。 在上述的整个过程中,任务调度管理系统进行调度的优先级和执行顺序。 基础薄弱甚至没有计算机科班基础,依然可以学习数据技术,执着的相信有一天是一名真正的数据人。2019-01-011
杰之7通过这一节的学习,理解了互联网产品加大数据产品等于大数据平台。 整个大数据平台的流程图老师已经给我们展示,我理解的是通过用户对App或者是网页的使用产生的数据,通过服务器传输到数据库中,这样就有了数据的获取。接着通过数据同步系统将获取的数据导入大数据产品中进行计算处理。计算处理主要分两类,批处理和流式计算,两者结合可以将过去到此刻的数据处理完成。最后将处理好的数据导出到数据库中给用户或者相关人员使用。 在上述的整个过程中,任务调度管理系统进行调度的优先级和执行顺序。 基础薄弱甚至没有计算机科班基础,依然可以学习数据技术,执着的相信有一天是一名真正的数据人。2019-01-011 helloWorld老师,我昨天看了腾讯TEG团队的一篇文章,他们做了一个流计算平台,其中提到了在Web页面通过画板构建一个流计算应用,想请教一下这样的功能实现的思路是什么2018-12-2721
helloWorld老师,我昨天看了腾讯TEG团队的一篇文章,他们做了一个流计算平台,其中提到了在Web页面通过画板构建一个流计算应用,想请教一下这样的功能实现的思路是什么2018-12-2721
收起评论

