

20 | Spark的性能优化案例分析(下)
李智慧

该思维导图由 AI 生成,仅供参考
上一期,我讲了软件性能优化必须经过进行性能测试,并在了解软件架构和技术的基础上进行。今天,我们通过几个 Spark 性能优化的案例,看一看所讲的性能优化原则如何落地。如果你忘记了性能优化的原则,可以返回上一期复习一下。
基于软件性能优化原则和 Spark 的特点,Spark 性能优化可以分解为下面几步。
1. 性能测试,观察 Spark 性能特性和资源(CPU、Memory、Disk、Net)利用情况。
2. 分析、寻找资源瓶颈。
3. 分析系统架构、代码,发现资源利用关键所在,思考优化策略。
4. 代码、架构、基础设施调优,优化、平衡资源利用。
5. 性能测试,观察系统性能特性,是否达到优化目的,以及寻找下一个瓶颈点。
下面我们一起进入详细的案例分析,希望通过这几个案例,可以帮助你更好地理解 Spark 的原理,以及性能优化如何实践落地,希望能对你有所启发。
案例 1:Spark 任务文件初始化调优
首先进行性能测试,发现这个视频图谱 N 度级联关系应用分为 5 个 job,最后一个 job 为保存结果到 HDFS,其余 job 为同样计算过程的反复迭代。但是发现第一个 job 比其他 job 又多了个计算阶段 stage,如图中红圈所示。
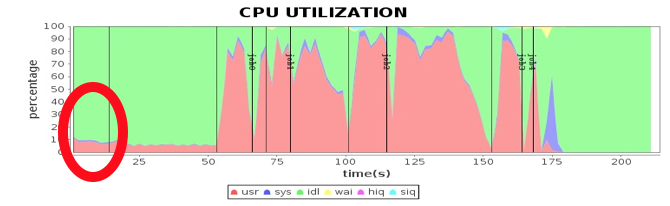
通过阅读程序代码,发现第一个 job 需要初始化一个空数组,从而产生了一个 stage,但是这个 stage 在性能测试结果上显示,花费了 14 秒的时间,远远超出合理的预期范围。同时,发现这段时间网络通信也有一定开销,事实上只是内存数据初始化,代码上看不出需要进行网络通信的地方。下图是其中一台计算节点的通信开销,发现在第一个 stage,写通信操作几乎没有,读通信操作大约每秒几十 MB 的传输速率。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文通过多个Spark性能优化案例,深入分析了性能测试、资源瓶颈分析、系统架构和代码优化、应用配置和操作系统配置优化、硬件优化等步骤,展现了性能优化原则在实践中的应用。案例一中,通过优化Spark任务文件初始化,采用本地文件作为进程间同步的锁,显著降低了初始化时间。案例二则通过调整任务分配策略,解决了计算资源利用不均衡的问题,提高了任务执行效率。案例三和案例四分别从应用配置和操作系统配置两个方面进行了优化,提高了CPU利用率和降低了sys态CPU消耗。最后,案例五介绍了硬件优化,通过升级网卡使用万兆网卡,显著缩短了网络通信时间,提高了整个系统的性能。这些案例展示了性能优化原则在实际应用中的有效性,为读者提供了深入理解Spark性能优化原理和实践落地的实用指导。文章提出了大数据软件性能优化的几个方面,包括硬件、操作系统、大数据产品及其配置、应用程序开发和部署。当性能不能满足需求时,需要综合考虑各项性能指标,合理配置资源或进行系统调优。最后,文章提出了思考题,引导读者思考大数据产品性能优化的可能方向。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《从 0 开始学大数据》,新⼈⾸单¥68
《从 0 开始学大数据》,新⼈⾸单¥68
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(16)
- 最新
- 精选
 吴科🍀我们公司集群作业最多的就是SQL作业约占80%,不管是hive SQL还是spark SQL,presto的SQL引擎都不是完美的,执行任务都有可能卡住99%就不动了。优化业务逻辑,SQL的写法是关键,减少重复计算,共用中间结果,还要有分区表的感念。
吴科🍀我们公司集群作业最多的就是SQL作业约占80%,不管是hive SQL还是spark SQL,presto的SQL引擎都不是完美的,执行任务都有可能卡住99%就不动了。优化业务逻辑,SQL的写法是关键,减少重复计算,共用中间结果,还要有分区表的感念。作者回复: 👍🏻
2018-12-13217 bill老师,文中的图是用什么软件得出的?
bill老师,文中的图是用什么软件得出的?作者回复: 自己开发,后面会讲到。
2018-12-13313 木白在第二个案例中说到,先注册的Executor可能会认领全部的任务,也就是说其所在的物理机会把那个stage的全部工作都做了吗?但是本着“移动计算比移动数据更划算的理论”,如果所有的任务都在一台机器上做岂不是会导致数据的移动?不知道我的理解有没有错哈
木白在第二个案例中说到,先注册的Executor可能会认领全部的任务,也就是说其所在的物理机会把那个stage的全部工作都做了吗?但是本着“移动计算比移动数据更划算的理论”,如果所有的任务都在一台机器上做岂不是会导致数据的移动?不知道我的理解有没有错哈作者回复: 是的,数据会有更多移动
2019-01-083 西南偏北又看了一遍,觉得老师在代码方面功底很强!
西南偏北又看了一遍,觉得老师在代码方面功底很强!作者回复: ^_^
2019-09-12 sunlight001在公司里没有接触大数据的机会,要想深入学习的话,需要怎么办呢,现在不管是看书,看demo,等总是感觉不深入,有什么好的办法吗2018-12-13122
sunlight001在公司里没有接触大数据的机会,要想深入学习的话,需要怎么办呢,现在不管是看书,看demo,等总是感觉不深入,有什么好的办法吗2018-12-13122 杰之7通过这节的阅读学习,通过第一个大数据实战产品,了解了性能调优的一般流程,通过性能测试,分析资源瓶颈,分析系统架构及代码,通过架构,代码及基础设施来进行调优,最后在进行测试。 老师通过5个方面进行的分析说明,1,Spark任务文件初始化调优,2,Spark任务调度优化,3,Spark应用配置优化,4,操作系统优化,5,硬件优化。通过这些维度的分析,我进一步的知道,做大数据开发,一样需要有好的计算机基本功,这是每一个技术人员的底层能力。 所以大数据开发中都会涉及到硬件,系统,大数据产品及其配置,应用程序开发和部署等实际经验,学习到这里,我需要真正做一判断,是真正决定走技术路,在接下来至少10年的时间去做技术呢?还是为了仅仅熟悉大数据方面的知识,适可而止呢? 我作为一名平凡而不想平庸的人,过程中再难我也会一路前行。2018-12-138
杰之7通过这节的阅读学习,通过第一个大数据实战产品,了解了性能调优的一般流程,通过性能测试,分析资源瓶颈,分析系统架构及代码,通过架构,代码及基础设施来进行调优,最后在进行测试。 老师通过5个方面进行的分析说明,1,Spark任务文件初始化调优,2,Spark任务调度优化,3,Spark应用配置优化,4,操作系统优化,5,硬件优化。通过这些维度的分析,我进一步的知道,做大数据开发,一样需要有好的计算机基本功,这是每一个技术人员的底层能力。 所以大数据开发中都会涉及到硬件,系统,大数据产品及其配置,应用程序开发和部署等实际经验,学习到这里,我需要真正做一判断,是真正决定走技术路,在接下来至少10年的时间去做技术呢?还是为了仅仅熟悉大数据方面的知识,适可而止呢? 我作为一名平凡而不想平庸的人,过程中再难我也会一路前行。2018-12-138 Knuth操作系统究竟在忙什么,占用了这么多 CPU 时间?通过跟踪 Linux 内核执行指令。。。。。。。。。 具体是怎么发现的呢,可以列一下详细的步骤么?2020-03-015
Knuth操作系统究竟在忙什么,占用了这么多 CPU 时间?通过跟踪 Linux 内核执行指令。。。。。。。。。 具体是怎么发现的呢,可以列一下详细的步骤么?2020-03-015 暴风雪1.第一个案例的代码,关于文件锁的范围,我有强迫症,就是把锁的范围再缩小一点,仅仅锁住判断下载的那段代码就好啦。 2.关于案例5,我有点看不懂网络使用率的图,为什么是50多秒的延迟,能不能用红圈圈一下。2018-12-1413
暴风雪1.第一个案例的代码,关于文件锁的范围,我有强迫症,就是把锁的范围再缩小一点,仅仅锁住判断下载的那段代码就好啦。 2.关于案例5,我有点看不懂网络使用率的图,为什么是50多秒的延迟,能不能用红圈圈一下。2018-12-1413 往事随风,顺其自然怎么实现操作的,讲解安利有什么具体指标?超过多少算不合理2018-12-133
往事随风,顺其自然怎么实现操作的,讲解安利有什么具体指标?超过多少算不合理2018-12-133 桃园悠然在第三步【分析系统架构、代码,发现资源利用关键所在,思考优化策略】思考过程中可以拿阿姆达尔法则做指引,选出优化收益最大的模块2018-12-132
桃园悠然在第三步【分析系统架构、代码,发现资源利用关键所在,思考优化策略】思考过程中可以拿阿姆达尔法则做指引,选出优化收益最大的模块2018-12-132
收起评论

