

24 | 从大数据性能测试工具Dew看如何快速开发大数据系统
李智慧

该思维导图由 AI 生成,仅供参考
我们在Spark 性能优化案例分析这一期中,通过对大量的 Spark 服务器的性能数据进行可视化分析,发现了 Spark 在程序代码和运行环境中的各种性能问题,并做了相应优化,使 Spark 运行效率得到了极大提升。
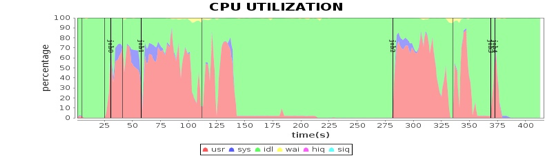
很多同学也在问,这些可视化的性能数据从何而来呢?如何在图中将性能指标和任务进度结合起来,可以一目了然看清应用在不同运行阶段的资源使用状况呢?事实上,当时为了进行 Spark 性能优化,我和团队小伙伴们开发了一个专门的大数据性能测试工具Dew。
Dew 设计与开发
Dew 自身也是一个分布式的大数据系统,部署在整个 Hadoop 大数据集群的所有服务器上。它可以实时采集服务器上的性能数据和作业日志,收集起来以后解析这些日志数据,将作业运行时间和采集性能指标的时间在同一个坐标系绘制出来,就得到上面的可视化性能图表。Dew 的部署模型如下。
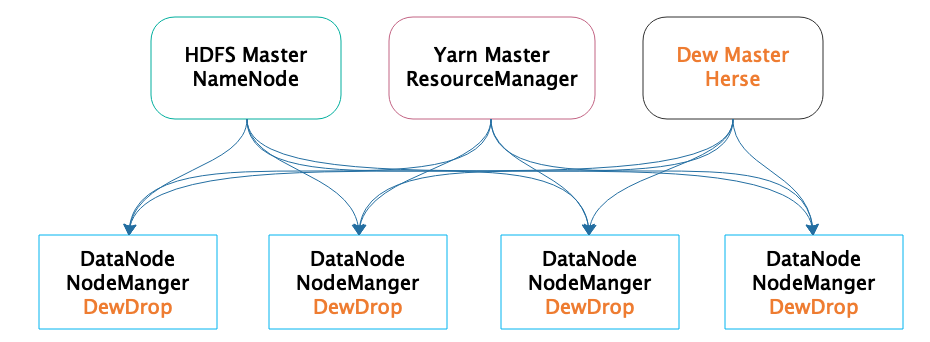
从图中看,Dew 的核心进程有两种,一种是 Dew Master 进程 Herse,另一种是管理集群中每台服务器的 Dew Agent 进程 DewDrop,Dew Agent 监控整个 Hadoop 集群的每台服务器。Herse 独立部署一台服务器,而 DewDrop 则和 HDFS 的 DataNode、Yarn 的 NodeManager 部署在大数据集群的其他所有服务器上,也就是每台服务器都同时运行 DataNode、NodeManager、DewDrop 进程。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文介绍了如何利用大数据性能测试工具Dew快速开发大数据系统。作者通过对Spark服务器的性能数据进行可视化分析,发现了Spark在程序代码和运行环境中的性能问题,并做了相应优化,使Spark运行效率得到了提升。文章详细介绍了Dew的设计与开发,以及使用Akka框架搭建Dew的底层通信和消息传输机制的过程。同时,还阐述了Akka的原理和应用,以及如何利用Akka实现分布式服务和流式分布式服务。通过本文,读者可以了解到如何利用Dew和Akka快速开发大数据系统,并深入了解Akka的Actor编程模型及其在分布式系统中的应用。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《从 0 开始学大数据》,新⼈⾸单¥68
《从 0 开始学大数据》,新⼈⾸单¥68
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(22)
- 最新
- 精选
 李智慧这个思考题写完后,我自己思考了下,基于这个思考题思路,和小伙伴们一起开发了一个反应式编程框架Flower,支持异步流式微服务:https://github.com/zhihuili/flower
李智慧这个思考题写完后,我自己思考了下,基于这个思考题思路,和小伙伴们一起开发了一个反应式编程框架Flower,支持异步流式微服务:https://github.com/zhihuili/flower作者回复: 给自己点个赞,哈哈~
2021-07-1328 吴科🍀spark在1.6后,使用netty完全代替akka了。主要还是看业务场景吧
吴科🍀spark在1.6后,使用netty完全代替akka了。主要还是看业务场景吧作者回复: spark放弃akka,主要原因是当时akka不稳定,akka还是要持续改进呀。
2018-12-2418 孔祥阳关于响应式有个小问题,如果 A通知 和 B通知同事修改一个数据怎么办?就像现实开发企业应用中,A领导拍了这个需求,B领导又出来指点一番,代码上是如何鉴定数据的理想性呢?
孔祥阳关于响应式有个小问题,如果 A通知 和 B通知同事修改一个数据怎么办?就像现实开发企业应用中,A领导拍了这个需求,B领导又出来指点一番,代码上是如何鉴定数据的理想性呢?作者回复: A和B如果同时修改一个数据,应该将修改消息发送给C,由C修改,而C的修改操作是串行的,即使A和B的消息同时发送给C,C也是一个消息一个消息轮流处理,不会出现并发同步问题。 更多细节请参考Akka文档。
2019-03-1928 冷锋相形见绌,拼音是xiāngxíngjiànchù
冷锋相形见绌,拼音是xiāngxíngjiànchù作者回复: 谢谢指正
2018-12-225 yang我根据自己理解的回复一下,老师可以看着答复一下哈:(/:抠鼻) 1.Akka天生支持分布式(配置远程Ptops)、天生支持高并发(Actor之间使用MailBox队列实现、无需锁等待…) 2.瞄了一眼GearPumps,感觉好厉害,四个节点,每秒可以处理1千8百万个长度为100byte的消息,仅有8ms延迟。那它们这个数据,貌似没说网络、机器配置是什么哇~ 可能说的不对……
yang我根据自己理解的回复一下,老师可以看着答复一下哈:(/:抠鼻) 1.Akka天生支持分布式(配置远程Ptops)、天生支持高并发(Actor之间使用MailBox队列实现、无需锁等待…) 2.瞄了一眼GearPumps,感觉好厉害,四个节点,每秒可以处理1千8百万个长度为100byte的消息,仅有8ms延迟。那它们这个数据,貌似没说网络、机器配置是什么哇~ 可能说的不对……作者回复: 是的
2018-12-2434 Geek_89bbab老师,在你的回答中 作为actor的b如果因为代码异常挂了,重启后会继续处理消息。如果是机器挂了,就没有了。 机器挂了该怎么处理,是系统架构要考虑的。 ———- A,b两个actor处于不同的进程中,a向b发信息,现在邮箱有未处理完的消息,b由于一些原因挂掉,重启为什么还可以继续处理邮箱的消息呢?难道消息持久化到文件中了吗?
Geek_89bbab老师,在你的回答中 作为actor的b如果因为代码异常挂了,重启后会继续处理消息。如果是机器挂了,就没有了。 机器挂了该怎么处理,是系统架构要考虑的。 ———- A,b两个actor处于不同的进程中,a向b发信息,现在邮箱有未处理完的消息,b由于一些原因挂掉,重启为什么还可以继续处理邮箱的消息呢?难道消息持久化到文件中了吗?作者回复: 我说的是进程内actor因为代码执行异常挂了,重启是restart actor,不是重启进程。如果是进程挂了,等同于机器挂了,
2019-01-062- Geek_89bbab老师,像akka中两个actor进行通信,它们在不同的进程中,如果actorA把消息发送到actorB的邮箱,B挂掉了。B的邮箱中还存在未处理的消息,重启后还可以重新处理吗?还是邮箱的存在内存中的,无法恢复?那如果B服务挂了,没有来得及处理A发送过去的消息,这该怎么办?
作者回复: 作为actor的b如果因为代码异常挂了,重启后会继续处理消息。如果是机器挂了,就没有了。 机器挂了该怎么处理,是系统架构要考虑的。
2019-01-04  Riordon老师,Dew子项目sparklogparser中Matcher是否支持spark 1.6.x和2.x呢?看项目创建比较早期。
Riordon老师,Dew子项目sparklogparser中Matcher是否支持spark 1.6.x和2.x呢?看项目创建比较早期。作者回复: 应该是不支持了,不过解析策略应该还是有效,跑一下,如果log解析异常,改一下相关代码就可以。
2018-12-22 老男孩使用akka实现传统的web应用功能用户注册,是否可以这样实现。首先通信方式是异步的,用户发起注册请求后,服务端收到请求后直接回复:已经受理了您的注册请求,稍后会将激活码下发邮箱或者手机。同时用户注册的actor就会把任务分解发给它的下一级actor处理,发给用户服务actor新增用户,发给积分兑换服务actor为新用户赠送注册积分和礼券。然后调用通知actor给用户的邮箱或者手机发送注册成功信息以及激活码等。感觉类似rabbitmq的消息队列也可以实现akka的异步和分布式通信。2018-12-2619
老男孩使用akka实现传统的web应用功能用户注册,是否可以这样实现。首先通信方式是异步的,用户发起注册请求后,服务端收到请求后直接回复:已经受理了您的注册请求,稍后会将激活码下发邮箱或者手机。同时用户注册的actor就会把任务分解发给它的下一级actor处理,发给用户服务actor新增用户,发给积分兑换服务actor为新用户赠送注册积分和礼券。然后调用通知actor给用户的邮箱或者手机发送注册成功信息以及激活码等。感觉类似rabbitmq的消息队列也可以实现akka的异步和分布式通信。2018-12-2619 纯洁的憎恶计算机产业变化太快了,我上学的时候还是过程化编程、模块化编程、面向对象的演进路线,这才没几年,已经又演化出新模式了——响应编程模式。2018-12-228
纯洁的憎恶计算机产业变化太快了,我上学的时候还是过程化编程、模块化编程、面向对象的演进路线,这才没几年,已经又演化出新模式了——响应编程模式。2018-12-228
收起评论

