

29|高性能:Kafka 为什么性能那么好?

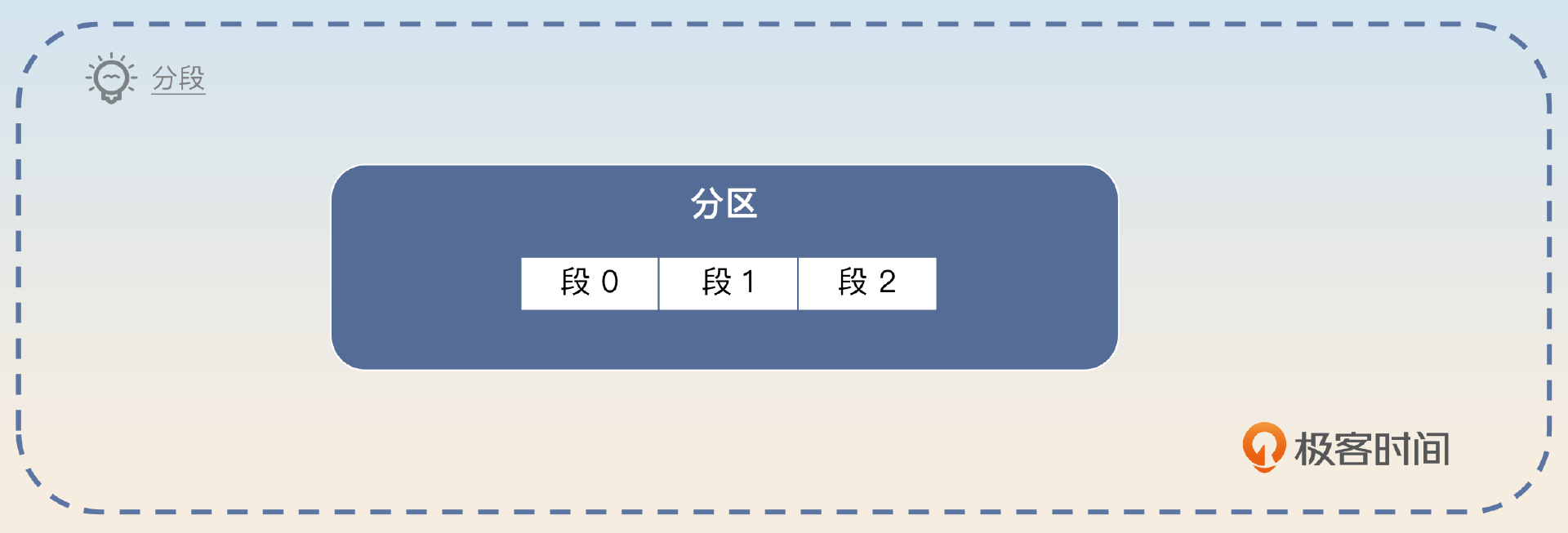
Kafka 分段与索引
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

Kafka高性能原因总结 Kafka的高性能得益于多种优化手段,包括分段与索引、零拷贝和批量操作。首先,Kafka利用偏移量和时间索引文件实现快速消息查找,同时应用零拷贝技术减少内核态与用户态的切换,提高性能。此外,批量操作减少了系统调用和内核态与用户态的切换,高效利用网络带宽。Kafka还充分利用了page cache,将数据写入page cache而不是直接刷新到磁盘上,有效减少了真实的IO操作次数。此外,Kafka充分利用了顺序写的特性,针对每一个分区有一个只追加的日志文件,提高了写入性能。然而,分区过多可能导致性能下降,因此需要合理规划分区数量。最后,Kafka的分区机制也能提高性能,减少并发竞争。整体而言,Kafka的高性能源自其多方面的优化策略,使其成为一款性能出色的消息中间件。 Kafka还采用了批量处理来提高性能。Kafka的客户端在发送的时候,并不是说每来一条消息就发送到broker上,而是说聚合够一批再发送。而在broker这一端,Kafka也是同样按照批次来处理的,显然即便同样是顺序写,一次性写入数据都要比分多次快很多。批量处理能够提升性能的原因是非常直观的,有两方面。一方面是减少系统调用和内核态与用户态切换的次数。另外一方面,批量处理也有利于网络传输。在网络传输中,一个难以避免的问题就是网络协议自身的开销。比如说协议头开销。那么如果发送100次请求,就需要传输100次协议头。如果100个请求合并为一批,那就只需要一个协议头。 Kafka为了进一步降低网络传输和存储的压力,还对消息进行了压缩。这种压缩是端到端的压缩,也就是生产者压缩,broker直接存储压缩后的数据,只有消费者才会解压缩。它带来的好处就是,网络传输的时候传输的数据会更少,存储的时候需要的磁盘空间也更少。当然,缺点就是压缩还是会消耗CPU。 总的来说,Kafka的高性能源自多方面的优化策略,包括分段与索引、零拷贝、批量处理和消息压缩等技术手段。这些优化策略使Kafka成为一款性能出色的消息中间件,为高并发和大数据场景提供了可靠的消息传输和存储解决方案。
《后端工程师的高阶面经》,新⼈⾸单¥59

全部留言(11)
- 最新
- 精选

 陈斌老师这节课讲的很好,之前也看过其他人讲过Kafka为什么性能高,但是都讲的不全面,学习到了。 page cache 技术,MySQL、 Redis、Elasticsearch 也用到了。 顺序写 Hive、Spark、ClickHouse 都使用到了。 零拷贝 技术 Netty, RocketMQ肯定使用到了。 分区可以用来缩小并发粒度,减轻并发竞争: JDK1.8 之前实现的 ConcurrentHashMap 版本。HashTable 是基于一个数组 + 链表实现的,所以在并发读写操作集合时,存在激烈的锁资源竞争,也因此性能会存在瓶颈。而 ConcurrentHashMap 就很很巧妙地使用了分段锁 Segment 来降低锁资源竞争
陈斌老师这节课讲的很好,之前也看过其他人讲过Kafka为什么性能高,但是都讲的不全面,学习到了。 page cache 技术,MySQL、 Redis、Elasticsearch 也用到了。 顺序写 Hive、Spark、ClickHouse 都使用到了。 零拷贝 技术 Netty, RocketMQ肯定使用到了。 分区可以用来缩小并发粒度,减轻并发竞争: JDK1.8 之前实现的 ConcurrentHashMap 版本。HashTable 是基于一个数组 + 链表实现的,所以在并发读写操作集合时,存在激烈的锁资源竞争,也因此性能会存在瓶颈。而 ConcurrentHashMap 就很很巧妙地使用了分段锁 Segment 来降低锁资源竞争作者回复: 赞!在面试中要记得这种横向对比的面试技巧!
2023-08-23归属地:广东1 KK请问老师一个问题:kafka 多分区,在写入的时候,是同时写入多个分区吗?还是只写主分区,然后同步到从分区?
KK请问老师一个问题:kafka 多分区,在写入的时候,是同时写入多个分区吗?还是只写主分区,然后同步到从分区?作者回复: 这个是和你的生产者的 acks 设置有关的。如果你选择要同步到从分区,那么就是写主分区,然后同步到从分区之后,才算是写入成功了。
2023-11-03归属地:北京- KK“可以确定 20000 这条消息应该放在 010031.log 这个文件里面。”,这里的20000是不是写错了,应该是2000? 根据描述:假如说一个文件的名字是 N.log,那么就表示这个段文件里第一条消息的偏移量是 N + 1。
作者回复: 我应该没写错吧?这里就是整个偏移量是 20000,010031 的第一条应该是 10032,20000 在这个文件。
2023-11-03归属地:北京2  Lum锁分离(Lock Separation):在高并发环境下,锁竞争可能会成为瓶颈。锁分离是一种将锁拆分成多个细粒度锁的技术,以减少锁竞争和提高并发性能。例如,在数据库中,可以将表锁拆分为行锁或列锁。 数据分片(Data Sharding):数据分片是一种将数据拆分成多个分片的技术,以提高并发性能和可扩展性。每个分片可以独立处理请求,从而减少竞争和提高吞吐量。例如,在分布式数据库中,可以将数据按照某种规则(如哈希或范围)划分到不同的节点上。 缓存(Caching):缓存是一种将数据存储在内存中,以加速读写操作和减少对后端存储系统的访问的技术。例如,在 Web 应用中,可以使用缓存来缓存页面、结果集或对象,以减少数据库访问和提高响应速度。 异步处理(Asynchronous Processing):异步处理是一种将请求和响应分离的技术,以提高并发性能和可扩展性。例如,在 Web 应用中,可以使用异步 Servlet 或异步消息处理器来处理请求,从而释放线程资源和提高吞吐量。 无锁编程(Lock-free Programming):无锁编程是一种不使用锁的并发编程技术,以减少竞争和提高性能。例如,在并发数据结构中,可以使用无锁算法(如 CAS)来实现原子操作,从而避免锁竞争和死锁。
Lum锁分离(Lock Separation):在高并发环境下,锁竞争可能会成为瓶颈。锁分离是一种将锁拆分成多个细粒度锁的技术,以减少锁竞争和提高并发性能。例如,在数据库中,可以将表锁拆分为行锁或列锁。 数据分片(Data Sharding):数据分片是一种将数据拆分成多个分片的技术,以提高并发性能和可扩展性。每个分片可以独立处理请求,从而减少竞争和提高吞吐量。例如,在分布式数据库中,可以将数据按照某种规则(如哈希或范围)划分到不同的节点上。 缓存(Caching):缓存是一种将数据存储在内存中,以加速读写操作和减少对后端存储系统的访问的技术。例如,在 Web 应用中,可以使用缓存来缓存页面、结果集或对象,以减少数据库访问和提高响应速度。 异步处理(Asynchronous Processing):异步处理是一种将请求和响应分离的技术,以提高并发性能和可扩展性。例如,在 Web 应用中,可以使用异步 Servlet 或异步消息处理器来处理请求,从而释放线程资源和提高吞吐量。 无锁编程(Lock-free Programming):无锁编程是一种不使用锁的并发编程技术,以减少竞争和提高性能。例如,在并发数据结构中,可以使用无锁算法(如 CAS)来实现原子操作,从而避免锁竞争和死锁。作者回复: 赞赞赞!如果是面试的话,比较建议用自己业务的例子,这样会有更好的说服力。
2023-10-27归属地:北京- Geek_icecream老师在讲解“零拷贝”时,提到的“四次内核态与用户态的切换”那张图里面,出现了两次“系统调用写操作”,是不是写错了?在进行第一次用户态与内核态切换时,不应该是“系统调用读操作”吗?先将内核态的数据“读”到用户态
编辑回复: 多谢提醒,已经改好啦🌹
2023-10-17归属地:广东2  ZhiguoXue_IT请教一下老师,kafka高性能的原因是这些,阿里的rocketmq的高性能有相似的吗
ZhiguoXue_IT请教一下老师,kafka高性能的原因是这些,阿里的rocketmq的高性能有相似的吗作者回复: 基本类似,但是我研究不够深入,哈哈哈,没怎么看过源码。
2023-09-29归属地:北京- Geek_43dc82发现了一些语言层面为了减少并发粒度的,减少锁并发竞争的优化,比如Golang GMP调度模型中的有global queue还有每个P本地的queue,实际P本地的queue的存在也是为了减少并发竞争
作者回复: 赞!这就是典型的全局竞争优化为局部竞争!
2023-09-20归属地:北京  五号特派员请问老师kafka和pulsar对比如何呢
五号特派员请问老师kafka和pulsar对比如何呢作者回复: 问到我的知识盲区了,我没怎么用过 plusar。之前我做技术选型的时候,我差不多就是无脑选 Kafka。
2023-09-13归属地:四川 peter请教老师几个问题: Q1:应用进入内核态,以Java为例,是什么语句? 文中有这一句:“这一步应用就是发了一个指令,然后是 DMA 来完成的”,这里的“应用发指令”,从Java代码的角度,什么代码的效果是普通的两次拷贝?什么代码可以做到零拷贝(即该代码可以控制DMA来完成数据拷贝)? (附:如果是C语言,又是哪一个语句?这个和专栏有点距离,可以不答) Q2:kafa是用Java写的,kafka可以控制Page Cache,那么,什么Java代码可以控制Page Cache? Q3:kafka的批量处理,是可以设置的吗?比如:是否采用批量处理,批量处理的数量等。应用可以设置吗? Q4:电商的topic按什么分类? 比如京东,首页左边是商品分类,会按商品类型来设置topic吗? Q5:生产者和消费者的压缩,并不是应用压缩,而是kafka客户端的压缩,对吗? 即生产者和消费者的开发人员并不需要开发压缩、解压缩功能,而是调用kafka的客户端的库,由库来完成压缩和解压缩功能。 Q6:kafka功能强大,那其他三种MQ就没有必要用了,只选kafka就可以了。是这样吗?
peter请教老师几个问题: Q1:应用进入内核态,以Java为例,是什么语句? 文中有这一句:“这一步应用就是发了一个指令,然后是 DMA 来完成的”,这里的“应用发指令”,从Java代码的角度,什么代码的效果是普通的两次拷贝?什么代码可以做到零拷贝(即该代码可以控制DMA来完成数据拷贝)? (附:如果是C语言,又是哪一个语句?这个和专栏有点距离,可以不答) Q2:kafa是用Java写的,kafka可以控制Page Cache,那么,什么Java代码可以控制Page Cache? Q3:kafka的批量处理,是可以设置的吗?比如:是否采用批量处理,批量处理的数量等。应用可以设置吗? Q4:电商的topic按什么分类? 比如京东,首页左边是商品分类,会按商品类型来设置topic吗? Q5:生产者和消费者的压缩,并不是应用压缩,而是kafka客户端的压缩,对吗? 即生产者和消费者的开发人员并不需要开发压缩、解压缩功能,而是调用kafka的客户端的库,由库来完成压缩和解压缩功能。 Q6:kafka功能强大,那其他三种MQ就没有必要用了,只选kafka就可以了。是这样吗?作者回复: 1. 在 JAVA 层面上其实你是感知不到的,你只知道你调用了一个JAVA 方法。如果这个 JAVA 方法最终在 JDK 里面发起了系统调用,那么你就要进入内核态了。在 Java 里面有一部分方法都是依赖native 方法来实现的。 2. 说起来,这就是我的知识盲点了,以前JAVA我也没直接操作过 Page Cache,但是我之前记得就是有不同的文件相关的 OutputStream 实现,就是没特意写明就是写到了 page cache。 3. 都是可以设置的。 4. 这个每个公司,甚至一个公司的不同部门设计方案都不一样,要看具体的场景。这个topic 和商品分类没什么关系,一般是指什么业务场景。 5. 对的 6. 也不是,因为别的 MQ 有一些 Kafka 没有的功能。不过如果你技术选项,无脑选 Kafka 就是了。这样做最大的好处就是,万一出问题了,别人也不能说 kafka 选得不对。
2023-08-23归属地:北京 Johar不过之前阿里云中间件团队测试过,在一个 topic 八个分区的情况下,超过 64 个 topic 之后,Kafka 性能就开始下降了。 老师,这个测试数据是部署了多少broker节点?换句话说,一个broker节点分配多少分区比较合适?
Johar不过之前阿里云中间件团队测试过,在一个 topic 八个分区的情况下,超过 64 个 topic 之后,Kafka 性能就开始下降了。 老师,这个测试数据是部署了多少broker节点?换句话说,一个broker节点分配多少分区比较合适?作者回复: 我给你找找原文,应该是这篇 https://developer.aliyun.com/article/62832。 我个人的话对一个 Broker 节点该分配多少分区,没有研究,这个得去找 Kafka 运维的同学了解一下了。
2023-08-23归属地:重庆

