

03|熔断:熔断-恢复-熔断-恢复,抖来抖去怎么办?

该思维导图由 AI 生成,仅供参考
前置知识
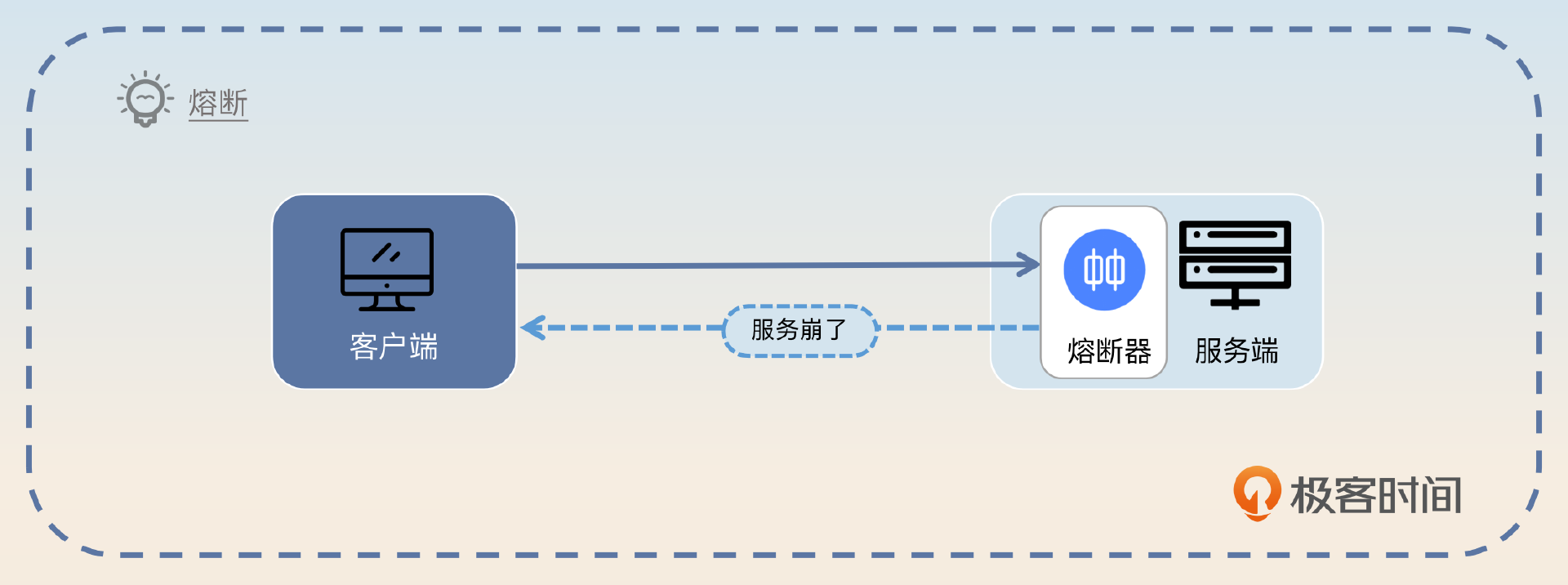
判定服务的健康状态
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文介绍了微服务架构中熔断的重要性以及相关的技术实践和面试准备建议。作者从熔断的基本定义出发,探讨了如何判断微服务出现问题以及如何判断微服务恢复正常的方法。文章提到了熔断策略中需要考虑的阈值选择、持续时间和恢复策略,以及如何避免抖动问题。此外,还提供了面试准备建议,包括公司的熔断实践情况和面试策略。在技术实践方面,作者分享了两种熔断方案,分别基于响应时间和缓存崩溃。另外,还介绍了一个结合负载均衡和熔断的方案,强调了客户端控制流量的重要性。总的来说,本文以技术实践和面试准备为主线,为读者提供了全面的熔断知识和面试策略,适合想要深入了解微服务架构熔断机制的读者。
《后端工程师的高阶面经》,新⼈⾸单¥59

全部留言(27)
- 最新
- 精选

 penbox在负载均衡和熔断两节课都提到了一个关键点,如何判断一个服务是否处于健康状态,这方面你有什么自己的思考? 学习了目前这两节课,我感觉服务端节点目前是什么状态,都是靠猜测或试探来得到的。 在负载均衡算法里面,靠连接数或响应时间来判断服务器权重,这两个指标都是客户端对服务端状态的猜测,并不是服务端的真实情况。动态调整权重里面的成加败减,要反复试探多次,才能把权重调整为正确的服务端状态。 在熔断这里,熔断之后到底恢复没有,不管是服务端和客户端都不知道,只能放点流量过去试一试。 目前好像还缺少手段来判断服务端当前的真实情况。有没有可能类似注册中心一样,在微服务框架中引入一个”健康中心“。每个服务端根据若干个指标,对自己打一个分,定时上报给健康中心。不管是客户端还是服务端自己,发现不对劲的时候,去健康中心里找到服务端对应的分数,就能直接判断出这个服务端的真实情况。
penbox在负载均衡和熔断两节课都提到了一个关键点,如何判断一个服务是否处于健康状态,这方面你有什么自己的思考? 学习了目前这两节课,我感觉服务端节点目前是什么状态,都是靠猜测或试探来得到的。 在负载均衡算法里面,靠连接数或响应时间来判断服务器权重,这两个指标都是客户端对服务端状态的猜测,并不是服务端的真实情况。动态调整权重里面的成加败减,要反复试探多次,才能把权重调整为正确的服务端状态。 在熔断这里,熔断之后到底恢复没有,不管是服务端和客户端都不知道,只能放点流量过去试一试。 目前好像还缺少手段来判断服务端当前的真实情况。有没有可能类似注册中心一样,在微服务框架中引入一个”健康中心“。每个服务端根据若干个指标,对自己打一个分,定时上报给健康中心。不管是客户端还是服务端自己,发现不对劲的时候,去健康中心里找到服务端对应的分数,就能直接判断出这个服务端的真实情况。作者回复: 赞!基本上就是靠猜和试探,试探也是固定套路,你已经总结得很对了。 你考虑得非常深远了。 这种健康中心的想法应该说之前也有人探讨过,后来就是发现监控做得好,不太需要这么一个健康中心。比如说我们的监控都会采集各个机器的 CPU,内存之类的东西。 所以现在其实是缺了一个能够综合运用各种监控指标打分的东西,但是一直以来也没有谁研究出来了通用的打分机制——适合各种业务的打分机制。 早期我还想过,能不能借助 AI 来学习人判断节点是否健康的思路,然后让 AI 来监控、打分、执行容错。还可以进一步整合日志分析、流量预判等,做得非常高级。 当然,这都是吹牛逼,我稍稍尝试过就放弃了。
2023-07-02归属地:四川38 BinWhat : 什么是「熔断」 在微服务架构里面是指当微服务本身出现问题的时候,它会拒绝新的请求,直到微服务恢复。 Why:微服务架构为什么要使用「熔断」 可以给服务端恢复的机会 个人理解: 「熔断」机制就是在系统高负载/ 服务崩溃的时候,拒绝新的请求。相当于提供给服务/系统一段“喘息”时间,“喘息”时间的意义在于: 1. 服务端不再接受新请求,服务的负载可以降低下来,防止服务雪崩 2. 服务端崩溃的情况下,可以重启服恢复务,可以理解为是一种故障转移(failover)手段 3. 上游服务收到「熔断」信息返回,可以进行兜底方案处理:例如业务补偿、请求转发、同步转异步等 When:什么时候进行和结束「熔断」 微服务本身「出现问题」的时候 「熔断」的开始和结束时机判断就在于以下问题的判断: 1. 判断微服务出现问题 2. 判断微服务恢复服务 「熔断」开启:判断出现问题 判断健康状态 1. 选择业务「指标」 每个微服务实际上都是附带着业务属性(微服务的划分是根据业务的职责和边界来划分) 所以可以根据业务来选择「指标」来代表微服务的健康状态。 常见的指标可以是:「响应时间的99线」,「错误率」等 2. 设置合适的「阈值」 这也是根据业务来决定的。 假设我们选择「响应时间」作为指标。 ● 根据业务要求的「指标」阈值设置 ● 观察业务整体的「指标」来设置 3. 设置持续多长时间才触发「熔断」 需要持续一段时间之后才触发「熔断」,因为: ● 防止「指标」 偶发性的突然增长 ● 防止「服务抖动」 「持续时间」的设置,依赖个人经验 「熔断」结束:判断恢复服务 现状:大多数是触发「熔断」后保持「一段时间」,就认为服务已经恢复正常,继续处理新请求 存在的问题:「抖动」 解决方案: 1. 「服务端控制流量」:恢复服务之后,比如说10%,20%逐步递增,不是100%恢复流量 这种做法不够好。依旧有请求因为熔断不会被处理。 2. 「客户端控制流量」:服务端熔断后,客户端不再请求这个节点,而是换一个节点。恢复之后,客户端逐步放开流量 亮点方案:客户端结合「负载均衡」控制流量,解决「抖动」问题 Question 面试中,经常在你讲完一些场景解决方案之后,面试官就会问你有自己实现吗?或者有没有落地在自己的项目中?如果回答有,面试官就会问遇到过什么问题没有?你回答没有,感觉自己给面试官的感觉又只是停留在理论上,没有实践经验。想问老师,对于类似这些问题,应该怎么去破局呢?
BinWhat : 什么是「熔断」 在微服务架构里面是指当微服务本身出现问题的时候,它会拒绝新的请求,直到微服务恢复。 Why:微服务架构为什么要使用「熔断」 可以给服务端恢复的机会 个人理解: 「熔断」机制就是在系统高负载/ 服务崩溃的时候,拒绝新的请求。相当于提供给服务/系统一段“喘息”时间,“喘息”时间的意义在于: 1. 服务端不再接受新请求,服务的负载可以降低下来,防止服务雪崩 2. 服务端崩溃的情况下,可以重启服恢复务,可以理解为是一种故障转移(failover)手段 3. 上游服务收到「熔断」信息返回,可以进行兜底方案处理:例如业务补偿、请求转发、同步转异步等 When:什么时候进行和结束「熔断」 微服务本身「出现问题」的时候 「熔断」的开始和结束时机判断就在于以下问题的判断: 1. 判断微服务出现问题 2. 判断微服务恢复服务 「熔断」开启:判断出现问题 判断健康状态 1. 选择业务「指标」 每个微服务实际上都是附带着业务属性(微服务的划分是根据业务的职责和边界来划分) 所以可以根据业务来选择「指标」来代表微服务的健康状态。 常见的指标可以是:「响应时间的99线」,「错误率」等 2. 设置合适的「阈值」 这也是根据业务来决定的。 假设我们选择「响应时间」作为指标。 ● 根据业务要求的「指标」阈值设置 ● 观察业务整体的「指标」来设置 3. 设置持续多长时间才触发「熔断」 需要持续一段时间之后才触发「熔断」,因为: ● 防止「指标」 偶发性的突然增长 ● 防止「服务抖动」 「持续时间」的设置,依赖个人经验 「熔断」结束:判断恢复服务 现状:大多数是触发「熔断」后保持「一段时间」,就认为服务已经恢复正常,继续处理新请求 存在的问题:「抖动」 解决方案: 1. 「服务端控制流量」:恢复服务之后,比如说10%,20%逐步递增,不是100%恢复流量 这种做法不够好。依旧有请求因为熔断不会被处理。 2. 「客户端控制流量」:服务端熔断后,客户端不再请求这个节点,而是换一个节点。恢复之后,客户端逐步放开流量 亮点方案:客户端结合「负载均衡」控制流量,解决「抖动」问题 Question 面试中,经常在你讲完一些场景解决方案之后,面试官就会问你有自己实现吗?或者有没有落地在自己的项目中?如果回答有,面试官就会问遇到过什么问题没有?你回答没有,感觉自己给面试官的感觉又只是停留在理论上,没有实践经验。想问老师,对于类似这些问题,应该怎么去破局呢?作者回复: 我愿称你为课代表,总结太强了! Question:其实我在面试的也会有这种困境,毕竟有些业务我确实没有解决过,只是听说过。 这里要分情况讨论: 1. 面试官问的场景是你确实要解决的,不过你用了 A 方案,但是你面试的时候还回答了 B,C 方案。这种,我一般就是先讲自己的 A 方案,讲完之后看情况,要是面试官觉得 A 不符合口味,就接着讲自己了解的 B 方案和 C 方案。正常来说,在做方案选型的时候,我多半比较过 B 和 C,但是最终选了 A。我只需要讲完 B C 之后讲一下自己当初的决策理由就可以。因为本身我落地的是 A,B 和 C 被我放弃了,问题也不太大。 2. 如果是这个场景跟我业务没有关系,比如说我的项目经历是支付方向,问我的场景是订单方向,我也就只能把公司的解决方案拿出来说说。问到一些答不出来的细节很正常,毕竟我项目经历又不是这个地方的。不过一般要避免面试官不按套路出牌,也就是最好别让自己陷入这种境地。 你在面试前,可以提前准备一下各种方案,包括如果真落地可能遇到什么问题,又或者你去搜搜业界落地的技术博客,也能回答上来一些细节性的问题。
2023-06-28归属地:广东5 小手冰凉*^O^*老师好,业界好的熔断方案都是怎么做的呢?
小手冰凉*^O^*老师好,业界好的熔断方案都是怎么做的呢?作者回复: 现在的主流是根据错误率来判断要不要熔断,这个错误可以是业务错误,也可以是系统错误(比如中间件本身的错误)。当错误率比较高的时候就会触发熔断。 我之前就用过这种策略,比较好实现。
2023-06-21归属地:北京25 小晨是否存在这种场景,通过客户端控制流量,熔断某个服务,将原本应该给这个服务的流量给其他节点,导致其他节点因为流量增加也导致也触发熔断,即原本可能只要熔断一个节点,但因为这个节点熔断了,流量分给了其他节点,其他节点的压力增加,进而触发熔断,造成"雪崩"?
小晨是否存在这种场景,通过客户端控制流量,熔断某个服务,将原本应该给这个服务的流量给其他节点,导致其他节点因为流量增加也导致也触发熔断,即原本可能只要熔断一个节点,但因为这个节点熔断了,流量分给了其他节点,其他节点的压力增加,进而触发熔断,造成"雪崩"?作者回复: 会!你已经领悟到了面试另外一个可以提及的亮点。正常来说,你后端的节点处理能力是有冗余的,那么一两个节点熔断,这些冗余的处理能力刚好够用。 但是如果你要是大部分节点都已经快要撑不住流量了,那么你这时候一两台机器熔断,就会导致其它节点也撑不住。 所以这种流量的场景,用限流会更好。
2023-07-04归属地:江苏3- TimJuly引申一个问题,发现故障时(可能是自身引起,也可能是下游引起),怎么判断是单机故障还是集群故障
作者回复: 严格来说,如果你的异常机制(Go 中的错误机制)设计得好,你是知道的。比如说,你们有严格的错误码机制,每一个业务都有自己的错误码前缀,那么你根据错误码就知道究竟是谁出错了,也就是你能区别是自身、还是下游。 而如果没有这种机制,你基本上判断不出来是自身,还是下游引起的。这时候对你来说已经不重要了,你直接将自身熔断了就可以。 而单机故障还是集群故障,你站在调用者角度永远都是认为下游是单机故障。比如说 A 调用 B,如果 A 调不通,它只会认为是它调用的 B 的那个节点崩了,而不会认为 B 整个集群都崩了。 集群故障是需要第三方来监控的。比如说你有 prometheus 监控,你发现所有的节点都各种超时,或者异常很多,这样你才能判定是整个集群都出问题了。 如果你利用的是负载均衡 fail-over 机制,或者你的客户端会给服务端发送心跳,那么服务端所有节点都调不通,也可以认为是集群崩溃了。
2023-06-28归属地:北京3 - Geek_948740同问 这篇文章里的客户端是指什么 app和电脑的话做这些策略成本很高吧
作者回复: 这里的客户端基本上都是指服务调用中的客户端。比如说 A 调用 B 的接口,那么 A 就是客户端。 整个专栏,基本上都是这种语义,如果是APP 之类的,我一般都会直接说 APP,或者用户。
2023-06-27归属地:浙江3 - Alex请教一下大明老师 在亮点一节 是否可以用网关来解决? 由网关(比如kong)不管是检测各个服务节点的主要指标也好 还是服务端主动上报需要熔断信息也好。 如果节点健康就允许开放节点 如果不健康就下架节点保护服务。
作者回复: 可以的。而且网关做这种还更加合适,因为网关知道有多少个节点,也知道每一个节点的负载,调度的灵活性和准确性都很好。唯一的缺陷就是查询经过网关会有性能损耗,并且网关本身容易成为性能和可用性的瓶颈,
2023-09-30归属地:江苏2  xyu为什么说客户端利用负载均衡来控制流量相比服务端逐步放开流量是亮点方案? 我说一下我的理解,不知道对不对: 从整个系统来看,使用客户端控制流量的方案使得整个系统的可用性更好;客户端通过调用返回情况来调整权重,交互的过程实际上也是一个考察对方恢复情况的过程,然后根据你的恢复情况来加大流量,从而避免服务器又再次陷入熔断;如果使用服务端逐步放开流量的方案,机械地按比例的放开很可能会让服务器再次陷入熔断。
xyu为什么说客户端利用负载均衡来控制流量相比服务端逐步放开流量是亮点方案? 我说一下我的理解,不知道对不对: 从整个系统来看,使用客户端控制流量的方案使得整个系统的可用性更好;客户端通过调用返回情况来调整权重,交互的过程实际上也是一个考察对方恢复情况的过程,然后根据你的恢复情况来加大流量,从而避免服务器又再次陷入熔断;如果使用服务端逐步放开流量的方案,机械地按比例的放开很可能会让服务器再次陷入熔断。作者回复: 对的!按比例是偷懒的做法,你讲的这是基于反馈的流量恢复,是更加高级的方案。
2023-06-29归属地:浙江22 sheep有两个问题: 1. "这个持续三十秒是如何计算出来的?这个问题其实可以坦白回答是基于个人经验,然后你解释一下过长或者过短的弊端就可以了。",面试官要是问,从哪些经验了解到要怎么设计的呢,15秒或者35秒不行吗,这时候该怎么回答呢 2. 熔断是服务端去提示客户端的话,现在也就有普遍使用的熔断中间件么,还是说是在服务器代码内实现的呢
sheep有两个问题: 1. "这个持续三十秒是如何计算出来的?这个问题其实可以坦白回答是基于个人经验,然后你解释一下过长或者过短的弊端就可以了。",面试官要是问,从哪些经验了解到要怎么设计的呢,15秒或者35秒不行吗,这时候该怎么回答呢 2. 熔断是服务端去提示客户端的话,现在也就有普遍使用的熔断中间件么,还是说是在服务器代码内实现的呢作者回复: 1. 35 秒也可以,差个 5 秒又没多大影响。至于 15 秒,看看效果怎样就可以。如果大部分时候 15 秒之后机器都还没恢复过来,那就要调大了。 2. 不是……现在的熔断,都是服务端直接熔断,根本不通知。你要利用类似于 grpc 的header 的机制,返回一个 Header 给客户端,客户端要配合检查;又或者你返回一个特定的错误码,也要客户端检测。
2023-08-28归属地:广东1 牧童倒拔垂杨柳在负载均衡和熔断两节课里面都提到一个关键点,即如何判定一个服务是否处于健康状态,这方面你有什么自己的思考? 这个关键点是服务端都相对被动,都需要等待客户端或者其他服务来检测状态 在负载均衡中,静态负载均衡算法是不考虑服务端的状态的,算法决定选谁就是谁,所以会出现各个服务端节点负载不可控的情况。动态负载均衡算法会去探测服务端状态,最少连接数是看连接数量,最少活跃请求是客户端看有多少请求还没回来,最短响应时间是客户端观察平均最短响应时间,在几种算法中,服务端都相对被动,不能主动做什么 在熔断这一课中也是这样,在熔断恢复时,不管是服务端控流量,还是客户端控流量,都是服务端基本都是被动等待 所以我在思考是不是可以借鉴负载均衡课程中的亮点方案,在某个服务端节点熔断之后,客户端收到熔断请求,此服务端节点被移出可用列表,此服务端节点在注册中心肯定也是不可用的,那么是不是可以谁都不去探测,等服务端恢复后,主动向注册中心上报自己恢复了。客户端要做的是等待一段时间后,定时向注册中心询问,某个服务端节点是不是恢复了。如果注册中心出问题了,这个时候客户端是一定要根据可用节点列表探测服务端是否可用的,顺带着就可以把触发熔断的服务端节点探测一下
牧童倒拔垂杨柳在负载均衡和熔断两节课里面都提到一个关键点,即如何判定一个服务是否处于健康状态,这方面你有什么自己的思考? 这个关键点是服务端都相对被动,都需要等待客户端或者其他服务来检测状态 在负载均衡中,静态负载均衡算法是不考虑服务端的状态的,算法决定选谁就是谁,所以会出现各个服务端节点负载不可控的情况。动态负载均衡算法会去探测服务端状态,最少连接数是看连接数量,最少活跃请求是客户端看有多少请求还没回来,最短响应时间是客户端观察平均最短响应时间,在几种算法中,服务端都相对被动,不能主动做什么 在熔断这一课中也是这样,在熔断恢复时,不管是服务端控流量,还是客户端控流量,都是服务端基本都是被动等待 所以我在思考是不是可以借鉴负载均衡课程中的亮点方案,在某个服务端节点熔断之后,客户端收到熔断请求,此服务端节点被移出可用列表,此服务端节点在注册中心肯定也是不可用的,那么是不是可以谁都不去探测,等服务端恢复后,主动向注册中心上报自己恢复了。客户端要做的是等待一段时间后,定时向注册中心询问,某个服务端节点是不是恢复了。如果注册中心出问题了,这个时候客户端是一定要根据可用节点列表探测服务端是否可用的,顺带着就可以把触发熔断的服务端节点探测一下作者回复: 是的,熔断也可以这么做。应该说,熔断、限流、降级都可以这么做。推而广之,任何原因导致服务端不可用,或者说有性能问题,都可以在负载均衡里面的将它暂时挪出可用列表。
2023-08-14归属地:河北1

