

25|消息积压:业务突然增长,导致消息消费不过来怎么办?

消费者和分区的关系
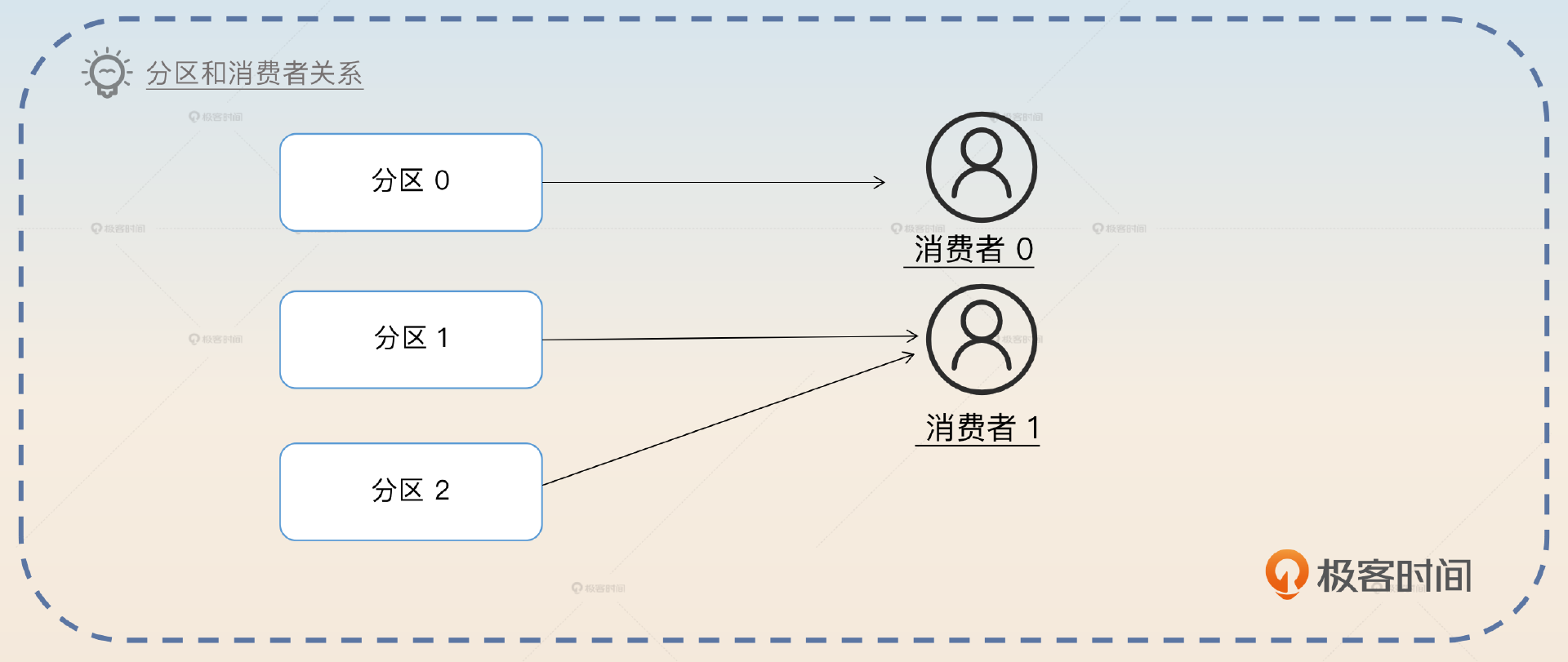
确定分区数量
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文介绍了解决消息队列中的消息积压问题的多种方法,包括确定分区数量、增加消费者、增加分区、创建新的topic、聚合消息与批量操作以及异步消费。文章首先讨论了消息积压问题的定义和影响,然后详细介绍了各种解决方案的实施过程和效果。其中,聚合消息与批量操作和异步消费被重点讨论,包括其优势、实施细节以及可能遇到的问题和解决方案。最后,文章提出了两个思考题,引发读者对解决消息积压问题的思考和讨论。整体而言,本文内容丰富,涵盖了多种解决方案,并提供了实际案例和面试准备建议,对读者解决消息积压问题具有指导意义。
《后端工程师的高阶面经》,新⼈⾸单¥59

全部留言(11)
- 最新
- 精选

 陈斌有些人认为,优化生产者性能也能解决消息积压,你觉得能还是不能?为什么? 我认为这是一个没有标准答案的问题,主要看对消息积压这个名词的理解;例如整个流程是生产者拿到消息(从前端、其他上游组件甚至说另一个消息队列中)之后处理的很慢,导致写入消息队列速度很慢,而消费者都是实时消费生产者产生的消息。从整体流程上来看好像消息积压确实是在生产者这里,但是如果你把消息积压理解的更狭隘一点,消息积压中的消息你认为是消息队列中的消息,只看最后一段流程,生产者都没有生产消息,何来消息积压之说。 在出现消息积压的时候,能不能在生产者发送的时候加个限流?毕竟,限制住了发送消息的速率,自然就解决了消息积压。 看具体业务,如果业务流程中在流量高峰期确实可以做限流操作,那确实可以限制住最高的流量生产速度,如果所有消费者的消费速度确实可以cover住所有生产者的生产速度,自然就可以解决消息积压问题。此时的消息积压一般是瞬时流量徒增导致的。
陈斌有些人认为,优化生产者性能也能解决消息积压,你觉得能还是不能?为什么? 我认为这是一个没有标准答案的问题,主要看对消息积压这个名词的理解;例如整个流程是生产者拿到消息(从前端、其他上游组件甚至说另一个消息队列中)之后处理的很慢,导致写入消息队列速度很慢,而消费者都是实时消费生产者产生的消息。从整体流程上来看好像消息积压确实是在生产者这里,但是如果你把消息积压理解的更狭隘一点,消息积压中的消息你认为是消息队列中的消息,只看最后一段流程,生产者都没有生产消息,何来消息积压之说。 在出现消息积压的时候,能不能在生产者发送的时候加个限流?毕竟,限制住了发送消息的速率,自然就解决了消息积压。 看具体业务,如果业务流程中在流量高峰期确实可以做限流操作,那确实可以限制住最高的流量生产速度,如果所有消费者的消费速度确实可以cover住所有生产者的生产速度,自然就可以解决消息积压问题。此时的消息积压一般是瞬时流量徒增导致的。作者回复: 赞! 生产者这边限流的问题就在于,违背了引入消息队列的本意。不过如果说被限流的请求,是转储到本地,后续再转发到 Kafka,那还可以接受。
2023-08-14归属地:广东4- TimJuly在出现消息积压的时候,能不能在生产者发送的时候加个限流? --- 这个要看是什么原因导致的积压 如果是消费方能力不足导致的那就不应该给生产者加限流 如果是生产者出 bug 了,写了个死循环拼命生产消息,那么该加限流还是要加的,毕竟 MQ 它性能再高也是需要进行保护的,更别说下游系统了。
作者回复: 好思路,防止生产者自己有坑!好思路!
2023-08-19归属地:北京2  子休有些人认为,优化生产者性能也能解决消息积压,你觉得能还是不能?为什么? 优化生产者性能可以从一定程度上缓解消息积压,比如kafak的批量读写和压缩的特性,就是提升了高吞吐,以及本文中提到的聚合消息和批量消费也是优化了生产者发送。 在出现消息积压的时候,能不能在生产者发送的时候加个限流?毕竟,限制住了发送消息的速率,自然就解决了消息积压。 如果在生产者上面加限流,那么消息中间件的削峰作用也就丧失了。虽然这样限制了发送消息的速率,看似解决了消息积压,但是消息中间件本身的削峰特性就大大丧失了,有点得不偿失。 另外,如果生产者自己做限流的话,很可能会对生产者本身造成巨大的资源负担,因为这样会导致生产者被限流限制,要持续不断地运行逻辑发消息。
子休有些人认为,优化生产者性能也能解决消息积压,你觉得能还是不能?为什么? 优化生产者性能可以从一定程度上缓解消息积压,比如kafak的批量读写和压缩的特性,就是提升了高吞吐,以及本文中提到的聚合消息和批量消费也是优化了生产者发送。 在出现消息积压的时候,能不能在生产者发送的时候加个限流?毕竟,限制住了发送消息的速率,自然就解决了消息积压。 如果在生产者上面加限流,那么消息中间件的削峰作用也就丧失了。虽然这样限制了发送消息的速率,看似解决了消息积压,但是消息中间件本身的削峰特性就大大丧失了,有点得不偿失。 另外,如果生产者自己做限流的话,很可能会对生产者本身造成巨大的资源负担,因为这样会导致生产者被限流限制,要持续不断地运行逻辑发消息。作者回复: 赞!第一个问题的角度很刁钻,受教了。
2023-08-15归属地:上海1 程序员花卷异步消费这个没太理解,比如RocketMQ默认就是使用线程池消费消息的,那这个异步消费还要怎么加,老师是否能给点具体的思路?一堆消息取出来之后再塞入某个本地队列然后进行异步的消费吗?
程序员花卷异步消费这个没太理解,比如RocketMQ默认就是使用线程池消费消息的,那这个异步消费还要怎么加,老师是否能给点具体的思路?一堆消息取出来之后再塞入某个本地队列然后进行异步的消费吗?作者回复: 就是你自己再额外开线程,然后自己控制线程数量。
2023-12-08归属地:云南- kai请问老师,有个问题一直没有解决,想咨询一下您。问题是这样的: 我们有一个消费者应用(同一个消费组下有 16 个消费者),部署在上海,消费深圳的 Kafka 集群的一个 Topic(16 个分区),消费之后在内存中,取出部分字段,通过 16 个生产者将数据异步发送到上海 Kafka 集群。 去年同期,消费的性能大概在 6300 QPS,但是今年大概只有 3000QPS,深圳和上海 Kafka 集群没有变化,消费应用没有变化,消费应用所在的服务器也没有变化,CPU 内存使用率大概在 50% 左右。 比较奇怪的一点是消费带宽一直没有上去。 消费应用的消费者参数: fetch.min.bytes:100000 生产者参数: batch.size:200000 linger.ms:100 compress.type:lz4 客户端做了各种尝试也没有提高性能,怀疑是上海到深圳之间基础网络层面有问题,但是又无法证明,因为这条路上没办法抓包。 请问一下,这种情形下如何提升消费 QPS 呢?
作者回复: 1. 首先如果怀疑是网络传输的问题,有没有办法在深圳那边也部署同样地消费者,比如说部署个一台两台,看看性能,这样就能排除是否是网络传输的问题。 2. 除了排查 CPU,还要看看磁盘 IO,网络带宽这些。 我看你的说法是大半年了代码都没变过,但是消费量下降了一半。我个人是觉得这有点奇诡,你确定一下消息消费逻辑,以及消息大小有没有变过。 比如说你这边可能没变过,但是你依赖的上下游变了,也有可能导致你消费速率变慢。 如果你并不想深究问题根源,只是单纯想要提高性能,那就可以直接考虑增加分区(或者创建新 topic),或者引入异步消费。 还是得先确认问题根源。
2023-10-14归属地:美国 - chooseTime有代码实例实战吗
作者回复: 有一部分我倒是在我的训练营里面写过,不过都是比较简单的微服务部分和缓存部分,这边 MQ 部分的做起来代码量比较大,所以我就没有搞开源版本。
2023-10-12归属地:内蒙古  锅菌鱼异步消费不是一个好的方案,MQ提供重试就没用了,少了一层业务保证
锅菌鱼异步消费不是一个好的方案,MQ提供重试就没用了,少了一层业务保证作者回复: 异步和重试并不冲突的。比如说在批量异步里面。你完全可以在某一条消息失败之后,重新丢回去消息队列,而后再批量提交。 不过确实要比非异步,用起来麻烦很多,要做一些额外的工作。
2023-09-28归属地:广东 浩仔是程序员最后总结的思维导图,增加分区那里有两个点重复了,都是根据消费者速率计算新的分区数量
浩仔是程序员最后总结的思维导图,增加分区那里有两个点重复了,都是根据消费者速率计算新的分区数量编辑回复: 感谢提醒,我们更新一下🌹
2023-09-02归属地:广东- Geek8004假如批量消费10条数据,第9条数据消费失败,采用异步重新执行的方案,那成功执行的剩下9条数据会提前先提交吗?假如异步这个线程充实了好多次都没成功咋办,这会不会造成了消息丢失了呀~ 第二个问题,老师您能分享一节幂等方案的课程吗?
作者回复: 好问题。 这也是你架构要考虑的问题。第一个是其它 9 条都不提交,停下来等重试。如果重试都失败了就告警,这个时候也会提交。 第二种做法是,只要执行一次就提交,你失败了的话,后面自己再异步重试。这种做法是首先要保证能够持续向后消费。 幂等方案,你是指啥分享?
2023-08-30归属地:中国香港  peter对于消息重复消费,业务有不是幂等的情况吗? 如果不是幂等,该怎么处理?
peter对于消息重复消费,业务有不是幂等的情况吗? 如果不是幂等,该怎么处理?作者回复: 业务不是幂等的话,坦白来说你只能考虑将消息 ID 做成唯一索引,然后封装和业务一样的本地事务里面。 而且,我个人经验表名大部分业务都是可以改造成幂等的。
2023-08-14归属地:北京

