

27|重复消费:高并发场景下怎么保证消息不会重复消费?

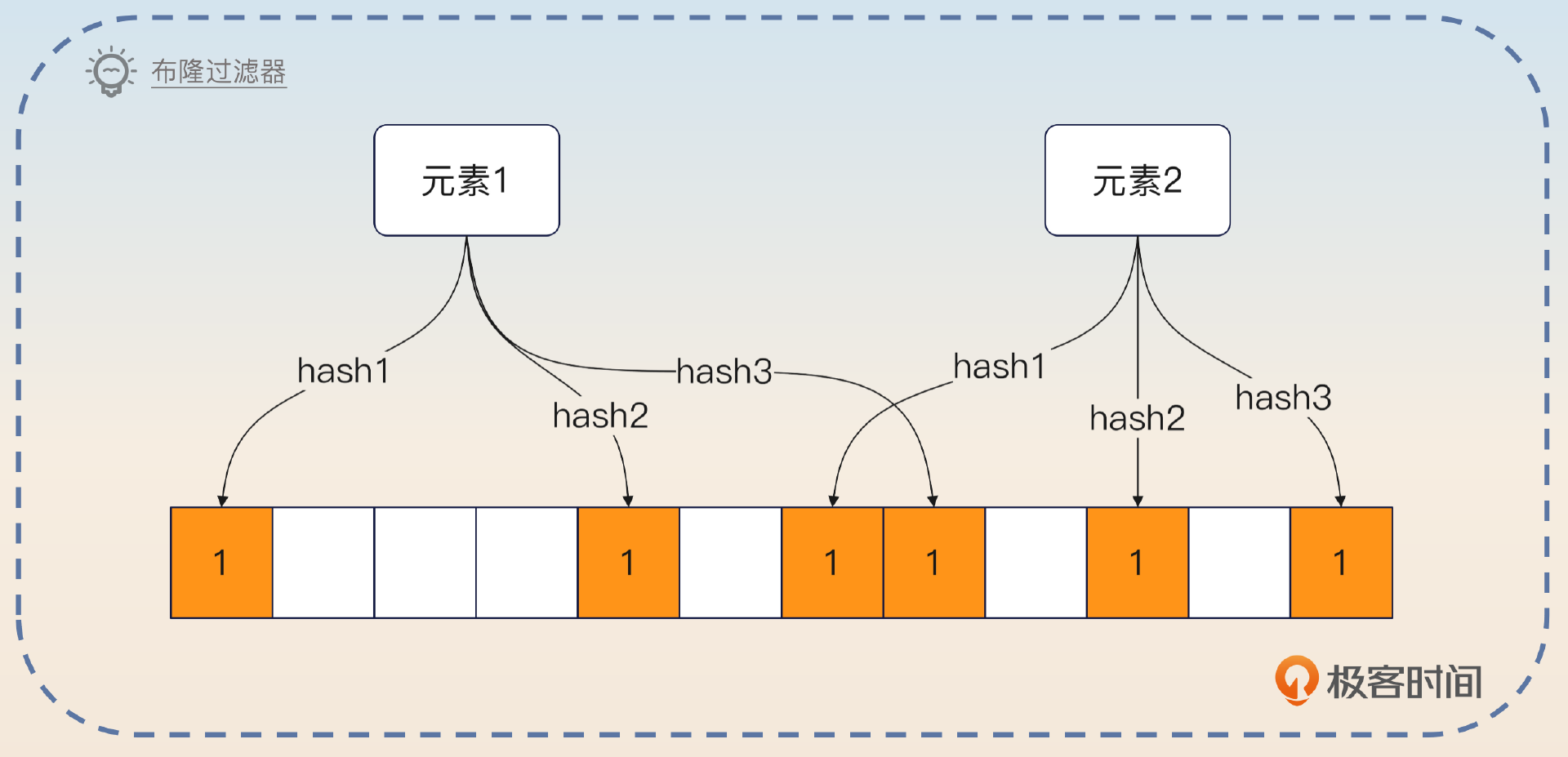
布隆过滤器
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了在高并发场景下如何保证消息不会重复消费的问题,并提出了多种解决方案。首先介绍了布隆过滤器的基本原理和优缺点,然后讨论了重复消费的可能原因,包括生产者重复发送和消费者重复消费。作者强调了将消费逻辑设计成幂等的重要性,并提出了在面试前需要了解的问题。此外,文章还介绍了基于本地布隆过滤器、Redis和唯一索引的高级方案,以确保到达数据库的流量最小化。同时,还提出了使用布隆过滤器的替代品——bit array,以提高性能并节省内存。总的来说,本文内容丰富,涵盖了技术细节和实际应用,对于需要解决高并发场景下消息队列相关问题的读者具有一定的借鉴意义。文章还提出了思考题,引发读者对于不同隔离级别下的操作阻塞和方案效果的思考,为读者提供了进一步思考和讨论的空间。
《后端工程师的高阶面经》,新⼈⾸单¥59

全部留言(17)
- 最新
- 精选
- shuff1e之前遇到过类似场景,QPS不高,用了一个分布式的悲观锁,同一个key的请求都会竞争这个分布式锁,只有竞争成功的才会继续往下执行。 没有想到过布隆过滤机,bit array,再加上redis的方案,可能是场景也不太一样。 不过也不得不感叹一句,人外有人,天外有天,大明老师还是对这种case做了一个系统的分析。
作者回复: 嘿嘿,感谢感谢。你还可以考虑将同一个 Key 的都打过去一个分区,然后直接就不需要锁了。小心 rebalance 问题就可以。
2023-08-18归属地:北京4  humor布隆过滤器 + 唯一索引的方案,不管走不走布隆过滤器,都会校验是否发生唯一冲突,那么布隆过滤器的意义是什么呢?因为每个消息都还会校验一下数据库的唯一性,有没有布隆过滤器对数据库来说都一样啊
humor布隆过滤器 + 唯一索引的方案,不管走不走布隆过滤器,都会校验是否发生唯一冲突,那么布隆过滤器的意义是什么呢?因为每个消息都还会校验一下数据库的唯一性,有没有布隆过滤器对数据库来说都一样啊作者回复: 好处就是挡住绝大部分重复请求。也就是说,如果你基本没有重复请求,那么这个方案就没啥用。
2023-08-18归属地:浙江84 江 Nina感觉布隆过滤器的假阳性坑挺大的,面试的时候能否这么设计呢:bitmap数组 + redis + mysql唯一索引,作为两点方案呢,因为大多数业务的用的唯一约束都是数字感觉。
江 Nina感觉布隆过滤器的假阳性坑挺大的,面试的时候能否这么设计呢:bitmap数组 + redis + mysql唯一索引,作为两点方案呢,因为大多数业务的用的唯一约束都是数字感觉。作者回复: 可以啊,这就是我在后面提到的,你可以用 bitmap 取代布隆过滤器。 不过bitmap 之后其实没太大必要接 Redis 了,因为 bitmap 咩有假阳性。也就是说,Bitmap 说有就是有,没有就是没有。
2023-08-30归属地:北京22 天天有吃的老师请问下,redis中的布隆过滤器长度是默认的,还是自己设置的呢?如果是自己设置的,多少长度合适呢?我想有没有一种情况位数组所有的元素都是1,那么布隆过滤器不是没用了?redis中会自动扩容吗?
天天有吃的老师请问下,redis中的布隆过滤器长度是默认的,还是自己设置的呢?如果是自己设置的,多少长度合适呢?我想有没有一种情况位数组所有的元素都是1,那么布隆过滤器不是没用了?redis中会自动扩容吗?作者回复: 布隆过滤器是全量的,所以你有多少数据,就有多长,甚至还要长一些,因为要考虑冲突的问题(假阳性)。
2024-03-04归属地:福建1 LumRead Committed 隔离级别下:如果两个事务同时插入相同的数据,那么后提交的事务会被阻塞,等待先提交的事务完成后才能继续执行。这是因为 Read Committed 隔离级别只保证了读取到的数据是已经提交的,但是未提交的数据仍然可以被其他事务读取到。 Repeatable Read 隔离级别下:如果两个事务同时插入相同的数据,那么后提交的事务会被回滚,因为 Repeatable Read 隔离级别保证了事务在执行过程中多次读取同一个数据时,得到的结果是一致的。如果有重复的插入操作,则会破坏这个一致性,因此后提交的事务会被回滚。
LumRead Committed 隔离级别下:如果两个事务同时插入相同的数据,那么后提交的事务会被阻塞,等待先提交的事务完成后才能继续执行。这是因为 Read Committed 隔离级别只保证了读取到的数据是已经提交的,但是未提交的数据仍然可以被其他事务读取到。 Repeatable Read 隔离级别下:如果两个事务同时插入相同的数据,那么后提交的事务会被回滚,因为 Repeatable Read 隔离级别保证了事务在执行过程中多次读取同一个数据时,得到的结果是一致的。如果有重复的插入操作,则会破坏这个一致性,因此后提交的事务会被回滚。作者回复: 赞! 这边你说“但是未提交的数据仍然可以被其他事务读取到”是不是写错了?这个应该是 Read Uncommitted 吧?
2023-10-26归属地:江苏1- Geek_48fcdf布隆+redis+唯一键方案里,布隆过滤器如果使用机器内存则那么无法解决分布式问题,如果使用redis存就得查两次redis,这里的布隆过滤器怎么个部署才有意义?
作者回复: 一个是结合前面的一致性哈希负载均衡,这样使用本地的布隆过滤器效果还可以。 如果使用 Redis 的话,确实是难以避免两次 Redis 操作。也可以考虑使用 lua 脚本直接封装。
2023-09-08归属地:北京1 
 陈斌问题1: 如果隔离级别不是RR,就会出现在插入成功唯一索引之后,业务操作完成之后提交事务可能会出现失败的情况,导致因为索引冲突而引起的不必要的回滚。如果隔离级别为RR的话,就不会出现上述情况。 问题2: 老师您说的最后一种方案我认为是:布隆过滤器 + redis + 唯一索引方案 重复请求占比为百分之1的话,该方案可以将近99%的流量挡在布隆过滤器 与 redis 层级,当然前提是redis的键值失效时间设置合理或者说重复请求的间隔时间很短或者说布隆过滤器没有出现假阳性,此时系统可以承受高并发流量。
陈斌问题1: 如果隔离级别不是RR,就会出现在插入成功唯一索引之后,业务操作完成之后提交事务可能会出现失败的情况,导致因为索引冲突而引起的不必要的回滚。如果隔离级别为RR的话,就不会出现上述情况。 问题2: 老师您说的最后一种方案我认为是:布隆过滤器 + redis + 唯一索引方案 重复请求占比为百分之1的话,该方案可以将近99%的流量挡在布隆过滤器 与 redis 层级,当然前提是redis的键值失效时间设置合理或者说重复请求的间隔时间很短或者说布隆过滤器没有出现假阳性,此时系统可以承受高并发流量。作者回复: 哈哈哈哈,问题 2 可能出乎你的预料,重复请求占比 1% 的话,你只能挡住这 1% 的重复请求。 你可能会奇怪,这不就是寄了吗?但是你要知道,如果你连正常的流量都处理不了,就不用谈别的了。
2023-08-19归属地:广东41- ilake> 关键点是在 RR 隔离级别下重复请求的插入操作会被阻塞。那么如果隔离级别不是 RR 的话,你觉得会发生什么? - 在 Repeatable Read(RR)隔离级别下,事务会在一开始就发现阻塞,因为在事务开始时,就会锁定读取的数据,确保了事务期间不会有其他事务修改这些数据。 - 在 Read Committed(RC)隔离级别下,事务是在稍后才发现阻塞的,因为它们在读取数据时不会锁定行,只有在稍后尝试修改数据时,如果发现有其他事务已经修改了相同的数据,才会发生阻塞 同樣都會被阻塞,只是時間點不同。 請問這樣理解正確嗎?
作者回复: 我个人认为这种说法也没问题。并且,这两者加的锁也是有差别的。
2023-12-01归属地:日本 - Geek8004布隆过滤器+redis+mysql 解决幂等消费问题的时候,假如重复的消息百分之2是不是就没多大用处? 重复消息到达百分是多少才能用这个方案.大概是什么样的场景配置可以用到这个场景;
作者回复: 对,重复请求不多效果就不好。至于比例多少,你可以自己根据业务来评估。我举个例子,如果你的数据库负载不高,那么你都不需要这个方案。如果你的数据库负载本身就很高了,那么你就算有一点点重复流量,也可以考虑加上去。
2023-11-10归属地:广东  一弦一柱思华年老师您好,请问如果用bit array,加上一致性哈希负载均衡,是不是可以不用DB兜底了呢,因为不存在假阳性问题;另外,这个布隆过滤器是不是需要定期清空啊,如果时间久了,布隆过滤器里的每一位都设置为了1,那得到的结果就永远是存在了,此时布隆过滤器就失效了。还有一个疑惑点:布隆过滤器+唯一索引的方案,布隆过滤器判断不存在的话,是不是也需要把key插入到DB,这样的话,判断存在和不存在都涉及DB更新,削流作用是怎么体现的呢
一弦一柱思华年老师您好,请问如果用bit array,加上一致性哈希负载均衡,是不是可以不用DB兜底了呢,因为不存在假阳性问题;另外,这个布隆过滤器是不是需要定期清空啊,如果时间久了,布隆过滤器里的每一位都设置为了1,那得到的结果就永远是存在了,此时布隆过滤器就失效了。还有一个疑惑点:布隆过滤器+唯一索引的方案,布隆过滤器判断不存在的话,是不是也需要把key插入到DB,这样的话,判断存在和不存在都涉及DB更新,削流作用是怎么体现的呢作者回复: 1. 使用 DB 兜底还可以有效防止节点崩溃,或者 Redis 崩溃的问题 2. 一般设计布隆过滤器的时候,都会默认这个布隆过滤器能装下所有的数据,毕竟布隆过滤器本身消耗资源不多,所以至少我是没删除过布隆过滤器。不过这算是一个很好的思路,学习了。 3. 主要是体现在重复请求的时候,可以避免 DB 操作。所以我说这个方案如果重复请求比例不高的时候,其实也没那么好用。
2023-11-07归属地:广东

