

17|分库分表分页查询:为什么你的分页查询又慢又耗费内存?

该思维导图由 AI 生成,仅供参考
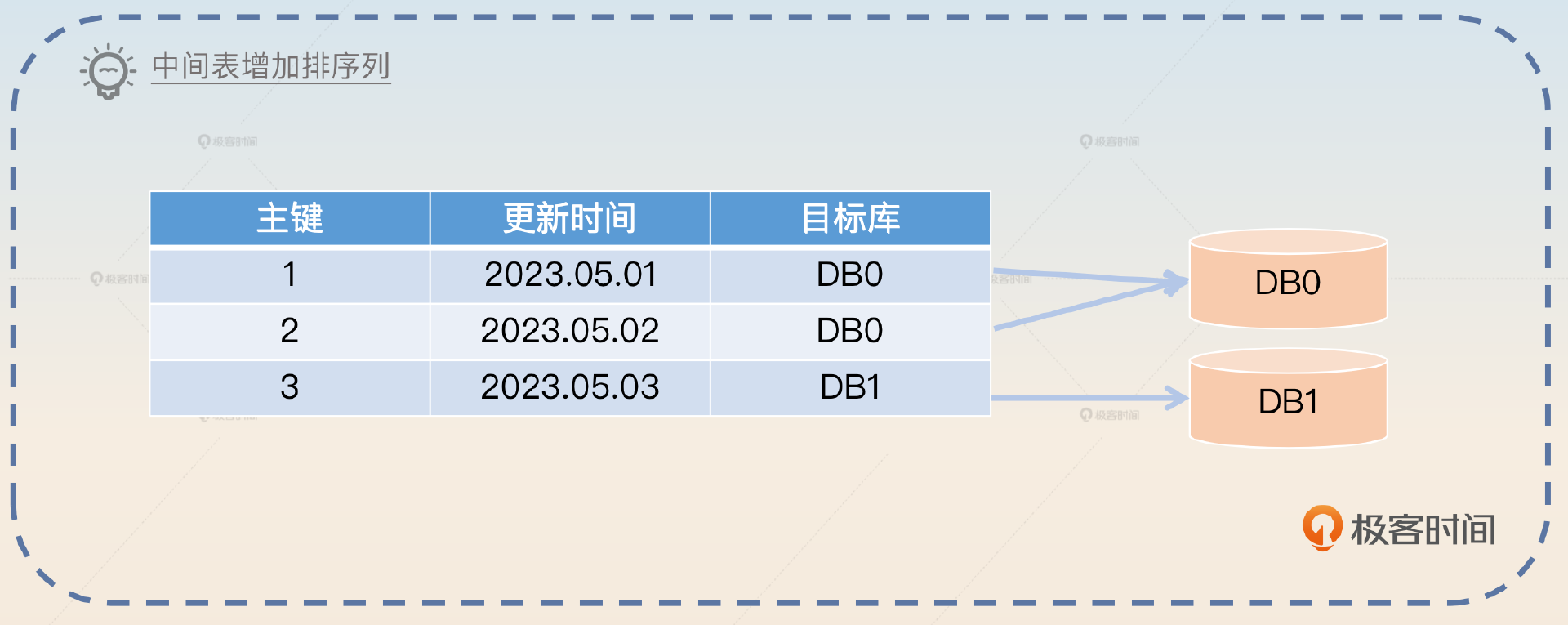
分库分表的一般做法
分库分表中间件的形态
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了分库分表分页查询的技术细节和优化方案,对于需要深入了解该领域的读者具有一定的参考价值。文章介绍了分库分表的一般做法,包括哈希分库分表、范围分库分表和中间表,以及分库分表中间件的形态,包括SDK形态、Proxy形态和Sidecar形态。此外,还介绍了分页查询的基本思路和优化方法,以及在面试中如何展现自己的能力。文章还提到了换用其他中间件的思路,包括使用NoSQL或分布式关系型数据库来解决分页困难的问题。另外,还介绍了两个亮点方案,包括二次查询和引入中间表,这些方案在实践中具有一定的特色和应用价值。文章内容涉及技术性较强,对于准备面试或者对分库分表分页查询感兴趣的读者有一定参考价值。
《后端工程师的高阶面经》,新⼈⾸单¥59

全部留言(8)
- 最新
- 精选

 penbox感觉分库分表太烧脑了,试着回答下老师的两道问题: 1. 如果查询里面有 GROUP BY,其实会影响到分页的执行。你可以说说假如 GROUP BY 刚好是根据分库分表键来进行的,分页可以怎么执行呢?不然的话又该怎么执行呢? 分组列如果是分库分表键,同一个分组列的值都在一张表里面,不需要改写聚合函数。 分组列如果不是分库分表键,同一个分组列的值分布在不同表里面,可能需要先改写聚合函数,比如 AVG 需要改写为 SUM 和 COUNT,再在内存中合并结果并计算。 后续分页相关的步骤应该就是上文里面的这些。 2. 这里的例子都是哈希分表,如果在使用范围分库分表的情况下,分页查询执行又有什么不同,你能说下范围查询的做法有怎样的区别吗?提示,注意 ORDER BY 和分库分表键,还要注意 GROUP BY。 在范围分库分表的情况下,如果 GROUP BY 的刚好是分库分表键,那么需要需要按分表顺序依次计算每张表的 COUNT,然后根据 OFFSET 判断返回结果起始位置在哪张表,根据 LIMIT 判断结果终止位置在哪张表,然后进行查询。 如果 ORDER BY 的是其它列,那么处理方式和上文应该就没区别了。 GROUP BY 的处理方式应该和上一题是一样的思路。
penbox感觉分库分表太烧脑了,试着回答下老师的两道问题: 1. 如果查询里面有 GROUP BY,其实会影响到分页的执行。你可以说说假如 GROUP BY 刚好是根据分库分表键来进行的,分页可以怎么执行呢?不然的话又该怎么执行呢? 分组列如果是分库分表键,同一个分组列的值都在一张表里面,不需要改写聚合函数。 分组列如果不是分库分表键,同一个分组列的值分布在不同表里面,可能需要先改写聚合函数,比如 AVG 需要改写为 SUM 和 COUNT,再在内存中合并结果并计算。 后续分页相关的步骤应该就是上文里面的这些。 2. 这里的例子都是哈希分表,如果在使用范围分库分表的情况下,分页查询执行又有什么不同,你能说下范围查询的做法有怎样的区别吗?提示,注意 ORDER BY 和分库分表键,还要注意 GROUP BY。 在范围分库分表的情况下,如果 GROUP BY 的刚好是分库分表键,那么需要需要按分表顺序依次计算每张表的 COUNT,然后根据 OFFSET 判断返回结果起始位置在哪张表,根据 LIMIT 判断结果终止位置在哪张表,然后进行查询。 如果 ORDER BY 的是其它列,那么处理方式和上文应该就没区别了。 GROUP BY 的处理方式应该和上一题是一样的思路。作者回复: 赞!!!很有天赋!! 第二个问题,GROUP BY 如果是分库分表键,其实和你第一个问题的答案差不多。ORDER BY 倒是,计算各个表的 COUNT,然后计算起始 offset。
2023-07-25归属地:四川3 进击的和和禁用跨页查询并没有解决分表分页查询问题呀 数据库这里只有二次查询真正解决了问题,但是有点复杂了...
进击的和和禁用跨页查询并没有解决分表分页查询问题呀 数据库这里只有二次查询真正解决了问题,但是有点复杂了...作者回复: 哈哈哈,应该说,跨页查询勉强算是解决了,主要是控制住了偏移量,那么网络通信和磁盘扫描都要少很多。
2023-07-24归属地:四川61- Geek_51a0ed实际上真的会这么做吗 感觉复杂度有点高。 感觉还是通过binlog同步到es里查好一点
作者回复: 早期没啥 ES 的时候用得多,后面就用得少了。 不过分库分表中间件要支持分页查询,就只能这么搞。
2023-12-28归属地:北京  斯蒂芬.赵跨页查询和全局查询发性能都很差的,当offset偏移量很大的情况下,扫描的行数增多了
斯蒂芬.赵跨页查询和全局查询发性能都很差的,当offset偏移量很大的情况下,扫描的行数增多了作者回复: 是的,难以避免。不仅仅是分库分表,但凡有 partition 概念的,差不多都有这个问题。
2023-12-27归属地:山东 大将军Leo。。老师我问下,如果是订单表和订单明细表。一个订单有多条明细。如果订单表按照月来分表,明细表按什么比较合适? 如果是一个订单1k明细,如果明细也按月来分这个时候数据差距就会越来越大。
大将军Leo。。老师我问下,如果是订单表和订单明细表。一个订单有多条明细。如果订单表按照月来分表,明细表按什么比较合适? 如果是一个订单1k明细,如果明细也按月来分这个时候数据差距就会越来越大。作者回复: 因为你本身是两张表,所以你可以说,订单表按照月,但是订单性情表按照周。核心目标是同一个订单的订单详情必然在同一个分区上就可以。
2023-12-12归属地:广东 木木夕有个问题,二次查询,比如我用的mycat,mycat屏蔽底层的查询,再返回来给客户端的,客户端怎么拿每个表的最大值,最小值?
木木夕有个问题,二次查询,比如我用的mycat,mycat屏蔽底层的查询,再返回来给客户端的,客户端怎么拿每个表的最大值,最小值?作者回复: 你用 mycat 的话,就不会自己去写二次查询了吧?
2023-10-05归属地:广东2 码小呆这个二次查询,我感觉,越来越复杂了,实际应该不会考虑使用了,直接用中间件来查询就好了
码小呆这个二次查询,我感觉,越来越复杂了,实际应该不会考虑使用了,直接用中间件来查询就好了作者回复: 实践中当然都是多快好省,面试就是啥复杂啥牛逼就用啥。
2023-08-26归属地:广东3 peter中间表,如果数据量很大,比如一千万,查询也会很慢吗?
peter中间表,如果数据量很大,比如一千万,查询也会很慢吗?作者回复: 当然会,但是要比业务表表现好很多。正常的中间表列都很少,而且你大部分列上面你都是需要创建索引的。因此你在中间表上的查询差不多都是命中索引,甚至直接是覆盖索引。 业务表因为列少,所以你单表能够放的中间表数据可以很多。
2023-07-24归属地:北京

