

24|消息顺序:保证消息有序,一个 topic 只能有一个 partition 吗?

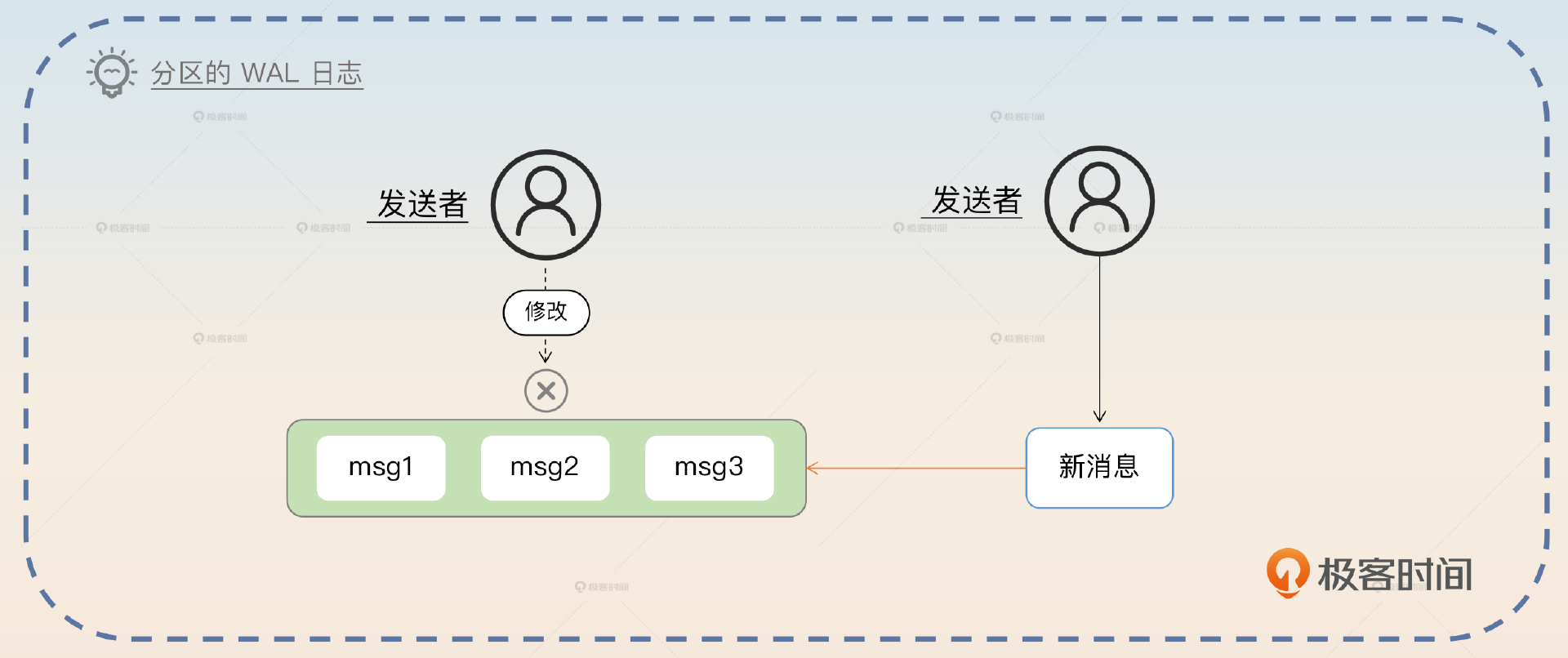
消息在分区上的组织方式
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了消息队列中的有序消息处理技术,重点讨论了有序消息的概念、问题和解决方案。在Kafka中,消息以分区为单位进行存储,每个分区都是有序且不可变的消息日志。文章介绍了有序消息的定义和跨topic的有序消息问题,以及解决方案。作者提到了单分区解决方案的缺陷,即性能较差,因为所有消息都发送到同一个分区,导致压力集中。针对这一问题,文章提出了异步消费和多分区方案作为改进方案。此外,还强调了业务内有序与全局有序的区别,指出大部分业务场景更注重业务内有序。文章还介绍了多分区方案可能出现的数据不均匀和消息失序问题,并提出了相应的解决方案。总的来说,本文对有序消息的概念、问题和解决方案进行了深入的探讨,对于理解消息队列中的有序消息具有重要的参考价值。
《后端工程师的高阶面经》,新⼈⾸单¥59

全部留言(16)
- 最新
- 精选
 sheepZhiguoXue_IT的留言中,老师这里回复了“你只需要检测有没有这个订单,或者状态是否符合,不符合你就丢回去原本的 topic 里面”,这里是丢回到原来的分区尾部?还是说创建一个生产者往对应topic发送原来的消息呢?
sheepZhiguoXue_IT的留言中,老师这里回复了“你只需要检测有没有这个订单,或者状态是否符合,不符合你就丢回去原本的 topic 里面”,这里是丢回到原来的分区尾部?还是说创建一个生产者往对应topic发送原来的消息呢?作者回复: 丢回去原本的分区就可以了,啥也不用做。但是消息积压的时候,你这个消息就要过很久才能消费到。
2023-12-15归属地:广东1 LargeOrange老师你好,引入hash槽可以解决数据量平衡的问题,顺序消费的场景下,当某个槽被重新映射到新的partition下,怎么保证消息的顺序消费呢
LargeOrange老师你好,引入hash槽可以解决数据量平衡的问题,顺序消费的场景下,当某个槽被重新映射到新的partition下,怎么保证消息的顺序消费呢作者回复: 最简单的做法,就是重新哈希之后,目标分区暂停消费一会。举个例子来说,原本消息是哈希到 A 分区的,后面重新哈希到 B 了,那么 B 暂停一会就可以。暂停的时间就是考虑到 A 上的都被消费了的时间。如果有 A 上有消息积压就会有比较多的问题。 如果业务上能够检测出来,那么就在 B 上消费的时候,重新丢回去 B 里面。
2023-12-04归属地:北京1 H·H消息重试这个怎么保证有序?
H·H消息重试这个怎么保证有序?作者回复: 老大难的问题了,哈哈哈哈。 说实在的,我也没特别好的的办法。如果你们本身就有那种排序机制,比如说我可以通过状态来判定消息是不是失序了,比如说当状态还是未支付的时候,你收到取消消息,这肯定是乱序了。那么你就可以尝试把取消消息重新发回去原本的消息队列上。 另外一种有漏洞的做法就是借助延迟消息。比如说你 A1 消息在重试,A2 不管知不知道 A1 在重试,直接自己延迟一分钟发送。“一分钟”是假定你的 A1 肯定能在一分钟之内重试完成。 当然,如果 A2 的发送者有办法知道 A1 还没发,那么就可以优化成只有当 A1 没发,A2 才会延迟,当然 A3,A4... 显然也要跟着延迟。 比如说,你可以借助 redis,假设 key1=1 的时候,代表 A1 还没发。key1=2 的时候,A1 已经发了。那么 A2 的发送者看一眼 Redis 就知道了。 不过,我的个人看法是……除非是面试吹牛,不然实践中直接告警拉到。就是在真的发现消息失序的时候,告警,人手工微调一下就可以。可用性高的话,你可能一个月才有一个两个这种失序的问题。
2023-09-11归属地:上海1 Sampson老师这里有在使用kafka的多分区方案的时候有一个点,如果某个分区挂了,或者出发了rebalance,那消息岂不是无序了,而且对于其他业务来说也是不友好的。我之前会经常遇到这个问题,请教下这里改怎么弄呢
Sampson老师这里有在使用kafka的多分区方案的时候有一个点,如果某个分区挂了,或者出发了rebalance,那消息岂不是无序了,而且对于其他业务来说也是不友好的。我之前会经常遇到这个问题,请教下这里改怎么弄呢作者回复: 分区挂了倒还好,毕竟生产者都发不出来。要解决 rebalance,有一个不太好的办法,但是勉强能用。就是消费者这边手动指定分区。 这样做的话,就是要做好监控。一旦消费特定分区的消费者崩溃了,要及时启动另外一个消费者来消费同样地分区。
2023-08-28归属地:上海1 ZhiguoXue_IT在订单的业务场景下,有下单消息,退单退款消息,按照订单号进行分区,保证同一个订单的数据一致性,如果是分布式环境下,退单的消息比下单的消息先到,业务一般如何处理呢
ZhiguoXue_IT在订单的业务场景下,有下单消息,退单退款消息,按照订单号进行分区,保证同一个订单的数据一致性,如果是分布式环境下,退单的消息比下单的消息先到,业务一般如何处理呢作者回复: 好问题。盲猜你是用了不同的 topic 是不是?就是退单的消息用了一个 topic,但是下单的用了另外一个 topic。 如果你是这种的话,只能用我提到的跨 topic 有序的方案,要有一个协调者进来,这个协调者在收到退单的时候,要先去看看有没有收到下单的消息。 但是一般用不着这样,以为你只需要检测有没有这个订单,或者状态是否符合,不符合你就丢回去原本的 topic 里面。或者你设定一个时间,比如说三十分钟之后再处理这个退单消息,然后预期三十分钟内应该能收到下单消息。
2023-08-24归属地:北京1 Zwh对于多分区下可能会出现的消息失序问题,新增一个乱序队列,消费者判断业务前置条件是否达成,若否就放入乱序队列,考虑增加延时和重试次数控制,乱序队列消费者收到消息后根据业务状态判断是否进行处理还是继续乱序,请问老师这个方案可行吗
Zwh对于多分区下可能会出现的消息失序问题,新增一个乱序队列,消费者判断业务前置条件是否达成,若否就放入乱序队列,考虑增加延时和重试次数控制,乱序队列消费者收到消息后根据业务状态判断是否进行处理还是继续乱序,请问老师这个方案可行吗作者回复: 可以。你的思路就是,如果我前置消息不满足,我就临时放一个地方。控制住重试就可以。
2023-08-21归属地:中国台湾21 利见大人老师您好,您好像忘更了关于解决消息堆积的章节哈! 这章我有两个疑问? 异步消费方案中的队列和多分区方案中的分区有什么分别? 异步消息方案中的队列不会出现数据不均匀的问题吗?
利见大人老师您好,您好像忘更了关于解决消息堆积的章节哈! 这章我有两个疑问? 异步消费方案中的队列和多分区方案中的分区有什么分别? 异步消息方案中的队列不会出现数据不均匀的问题吗?作者回复: 1. 你是说那个内存队列?就是载体不同。如果是内存队列,那么宕机就没了。 2. 一样会有数据不均匀的问题,但是更加容易解决,因为你开启队列的时候,自己应用一下一致性哈希之类的算法就可以解决了。 不过其实你可以考虑只用一个队列,线程都从这里面取。就是在最后要协调大家停下来批量提交麻烦一点,倒也还可以接受。
2023-08-11归属地:上海1 黑客不够黑我有两点疑问: 1. 使用一致性哈希解决数据倾斜问题,但无法解决单个用户的热点,比如同一个用户,使用用户ID来选择分区,短时间内这个用户的qps激增一样会出现热点以及数据倾斜 2. 增加分区导致消息失序的解决方案怎么看都不靠谱,因为消息积压了才要增加分区,说明积压消息的分区一直处于满载且缓慢流动的状态,等待3分钟可能解决了msg2和msg1的顺序问题,但会增加msg15和msg16失序的问题,本质上没有解决问题。 以上是个人浅见。
黑客不够黑我有两点疑问: 1. 使用一致性哈希解决数据倾斜问题,但无法解决单个用户的热点,比如同一个用户,使用用户ID来选择分区,短时间内这个用户的qps激增一样会出现热点以及数据倾斜 2. 增加分区导致消息失序的解决方案怎么看都不靠谱,因为消息积压了才要增加分区,说明积压消息的分区一直处于满载且缓慢流动的状态,等待3分钟可能解决了msg2和msg1的顺序问题,但会增加msg15和msg16失序的问题,本质上没有解决问题。 以上是个人浅见。作者回复: 1. 确实,极端情况会出现你说的问题。但是并不影响我这里的方案解决了大部分的数据倾斜问题。而且短时间的 QPS 激增不需要去管它,本身 Kafka 就能削峰。而如果你说长时间持续性的单个用户 QPS 激增,你给它一个白名单,让它自己独享一个 topic,彻底隔离掉; 2. 它只会引起新分区上的消息短暂积压,不会引起失序。当你都积压了一大堆数据,比如说要好几个小时才能消费完的时候,你需要的不是增加分区,而是考虑先用异步消费的方案解决。
2024-02-26归属地:江苏 Qualifor你好,请问下老师,如何做到新增的分区不让消费者消费呢?kafka 有对应的功能吗?
Qualifor你好,请问下老师,如何做到新增的分区不让消费者消费呢?kafka 有对应的功能吗?作者回复: 有一个简单的做法,你可以尝试,就是这个特定的分区,你会消费,但是你只是读了消息之后啥也不干。等到你确定老分区上的老数据消费之后,你可以重置这个分区的偏移量,这一次消费就是真的执行业务逻辑了。
2024-01-04归属地:北京- sheep“手工调整槽的映射关系或者哈希环上节点的分布”, 1. 这里使用一致性哈希算法时候,采用插入几个分区节点来分散数据较多的分区 1.1 这里多几个分区后,是不是一致性哈希算法的计算方法也要调整,否则只会定位在之前的分区所组成的哈希环上? 1.2 那这里我可以不插入几个分区,转为调整发布者的一致性哈希算法,让指定分区的哈希范围变长或变短来分散数据。这样子的话,除了每个发布者都要调整算法之外,还会有其他什么问题? 2. 手工调整槽的映射关系 2.1 会出现被调整的槽上有数据的情况吗(比如: 槽5属于分区2,然后上有槽上5个数据,这时候要调整到分区1),这时候是否需要等待数据消费完,再进行调整呢? 2.2 调整槽所属的分区,也会出现消息失序的情况吧?
作者回复: 1.1 不需要调整。你可以认为,你的环是不变的,变的是上面的节点; 1.2 也可以。 2 看你业务有没有这个要求。在有序消息的场景下,就是需要的。最好就是调整后的新分区,暂时停止一段时间消费。
2023-12-14归属地:广东

