

11|SQL优化:如何发现SQL中的问题?

前置知识
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

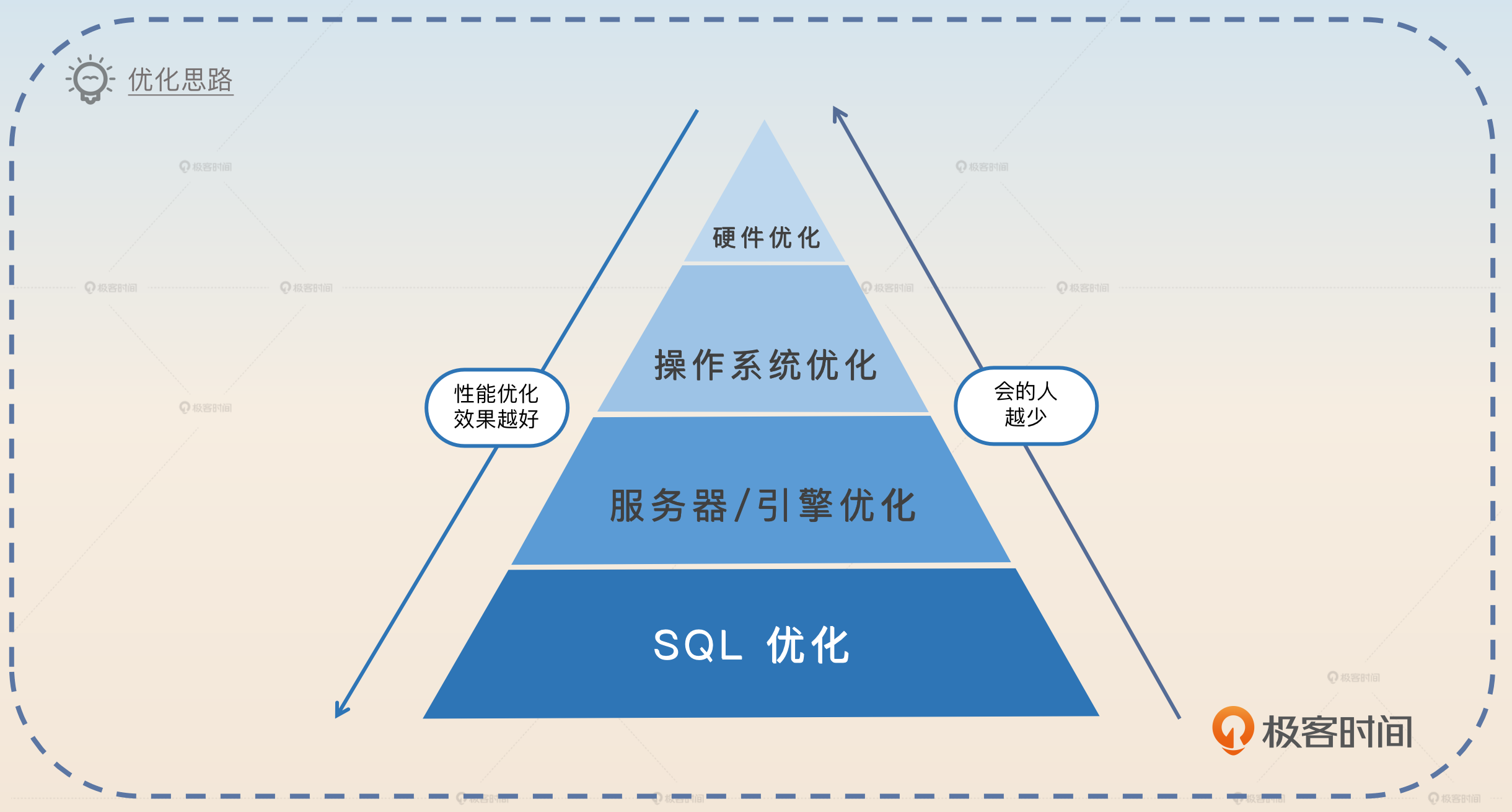
本文从数据库优化的角度出发,介绍了SQL优化的多种方案,包括硬件资源优化、操作系统优化、服务器/引擎优化和SQL优化。文章详细介绍了EXPLAIN命令的使用和重要字段的含义,以及选择索引列和大表表定义变更等优化手段。在面试准备方面,建议收集和整理业务表结构定义、慢SQL案例以及考虑面试官可能的深挖方向。总的来说,SQL优化手段繁多细碎,但在面试中只需精心设计面试节奏,展现对SQL优化的理解和应用。文章内容丰富,适合技术人员快速了解SQL优化的相关知识和面试准备要点。同时,还提供了优化案例,包括覆盖索引、优化ORDER BY、优化COUNT、索引提示优化和用WHERE替换HAVING等,为读者提供了实用的优化思路和方法。
《后端工程师的高阶面经》,新⼈⾸单¥59

全部留言(12)
- 最新
- 精选
 子休这里列一下我个人之前总结的SQL优化的思路(稍微增加了一些本章节提到了,但是我也学习到了的内容): 1. 索引的角度。 (1)根据执行计划优化索引,从type,keys,extra这几个主要字段去分析。 (2)避免返回不需要的列(覆盖索引,避免回表) 2. 架构层面。 (1)分库分表 (2)读写分离 (3)为了避免like这种,以及超级大数据量查询(没办法避免多表查询),可以借助数仓,建宽表,以及引入es等方法进行实现。 3. 分析问题角度 (1)执行sql之前,先执行“set profiling = 1;”,然后执行完查询sql之后,执行"show profiles "可以展示详细的具体执行时间。 (2)show profiles的方法已经开始被MySQL逐渐淘汰,后续会被 performance_schema代替,performance_schema是一个数据库,里面有87张表,可以通过查询这些表来查看执行情况。 4. 常见技巧 (1)深度分页问题:limit m,n分页越往后越慢的问题。 a. select * from tableA where id >=(select id from tableA limit m, 1) limit n; 这种做法有个弊端,要求主键必须自增。 b. select * from tableA a inner join (select id from tableA limit m, n)b on a.id = b.id (2)避免For循环里面查单条数据,改为一条sql查集合。 (3)建表的时候考虑增加冗余字段,尽可能保持单表查询,而非多表Join. (4)在所有的排序场景中,都应该尽量利用索引来排序. (5)算count行数的时候,如果业务场景要求不高,可以有一个偏门方法,就是执行explain select * from t where xxxx,在执行计划里面会预估出来大致的行数。 (6)where 替代 having
子休这里列一下我个人之前总结的SQL优化的思路(稍微增加了一些本章节提到了,但是我也学习到了的内容): 1. 索引的角度。 (1)根据执行计划优化索引,从type,keys,extra这几个主要字段去分析。 (2)避免返回不需要的列(覆盖索引,避免回表) 2. 架构层面。 (1)分库分表 (2)读写分离 (3)为了避免like这种,以及超级大数据量查询(没办法避免多表查询),可以借助数仓,建宽表,以及引入es等方法进行实现。 3. 分析问题角度 (1)执行sql之前,先执行“set profiling = 1;”,然后执行完查询sql之后,执行"show profiles "可以展示详细的具体执行时间。 (2)show profiles的方法已经开始被MySQL逐渐淘汰,后续会被 performance_schema代替,performance_schema是一个数据库,里面有87张表,可以通过查询这些表来查看执行情况。 4. 常见技巧 (1)深度分页问题:limit m,n分页越往后越慢的问题。 a. select * from tableA where id >=(select id from tableA limit m, 1) limit n; 这种做法有个弊端,要求主键必须自增。 b. select * from tableA a inner join (select id from tableA limit m, n)b on a.id = b.id (2)避免For循环里面查单条数据,改为一条sql查集合。 (3)建表的时候考虑增加冗余字段,尽可能保持单表查询,而非多表Join. (4)在所有的排序场景中,都应该尽量利用索引来排序. (5)算count行数的时候,如果业务场景要求不高,可以有一个偏门方法,就是执行explain select * from t where xxxx,在执行计划里面会预估出来大致的行数。 (6)where 替代 having作者回复: 赞!
2023-07-19归属地:上海13
 徐石头1. 按前台业务和后台业务分表,前台业务表不包含各种审核状态,只包含纯粹的业务数据,所以表数据更少,字段更小,每次读到buffer pool 中能读更多的数据,性能更好 2. 避免like查询,搜索功能使用专业的搜索引擎,而且还能更加为业务提供更多发展空间,比如es的分词,权重打分等 3. 避免循环中查询单条数据的错误,写的时候要思考如果该接口高并发时会不会挂 4. 适当冗余少量字段,做一定的反范式设计,尽量使用单表查询 5. 索引是有代价的,在上千万的数据中,有时候索引占的空间比表数据更大,一定要避免滥用,不要为了sql建索引,而是从业务角度考虑索引
徐石头1. 按前台业务和后台业务分表,前台业务表不包含各种审核状态,只包含纯粹的业务数据,所以表数据更少,字段更小,每次读到buffer pool 中能读更多的数据,性能更好 2. 避免like查询,搜索功能使用专业的搜索引擎,而且还能更加为业务提供更多发展空间,比如es的分词,权重打分等 3. 避免循环中查询单条数据的错误,写的时候要思考如果该接口高并发时会不会挂 4. 适当冗余少量字段,做一定的反范式设计,尽量使用单表查询 5. 索引是有代价的,在上千万的数据中,有时候索引占的空间比表数据更大,一定要避免滥用,不要为了sql建索引,而是从业务角度考虑索引作者回复: 赞!这些优化手段都可以拿去面试。 1. 可以总结为就是尽可能查询少的字段,以及按照查询频率进行垂直分表。 3. 可以说是新手研发的常见坑了,大部分都是为了偷懒而引起的。 4. 是,冗余都好说,就是又要解决一致性问题,也挺麻烦的
2023-07-13归属地:湖南9 江 Nina[WHERE id > max_id ] 具体实操过程中,max_id是如何获取的呢?假如直接点击第1000页的内容,是不是就没法实现了?
江 Nina[WHERE id > max_id ] 具体实操过程中,max_id是如何获取的呢?假如直接点击第1000页的内容,是不是就没法实现了?作者回复: max_id 是前端继续往后传。 理论上来说,这个优化不适合做跳页。所以这个优化适合在 APP 这种下拉刷新的环境下。
2023-07-10归属地:北京75 第一装甲集群司令克莱斯特SQL查询分页偏移量大的问题,又名深度分页。
第一装甲集群司令克莱斯特SQL查询分页偏移量大的问题,又名深度分页。作者回复: 学到了!居然还有专业名词!
2023-07-11归属地:北京4 浩仔是程序员老师你好,如果一个表单管理,有很多的筛选条件,超过10个,需要怎么设置索引比较合理,好像也避免不了回表的问题
浩仔是程序员老师你好,如果一个表单管理,有很多的筛选条件,超过10个,需要怎么设置索引比较合理,好像也避免不了回表的问题作者回复: 回表其实是很正常的事情,只是说在性能苛刻的场景下,要避免回表。目前的数据库回表一次不到 10ms,基本都能接受。 我觉得你是想问这种动态筛选怎么设置索引吧?一般我建议是用 ES 比较好,如果用 MySQL,我建议你在最频繁的几个查询条件里面设置索引。又或者,可以通过业务折中来达成目标,比如说要求某些字段是必填。
2023-07-28归属地:广东3 sheep"SHOW TABLE STATUS 也能看到一个 TABLE_ROWS 列,代表表的行数,那么能不能用这个来优化 COUNT(*)?" 不太行,索引统计的值是通过采样来估算的。实际上,TABLE_ROWS 就是从这个采样估算得来的,因此它也很不准。有多不准呢,官方文档说误差可能达到 40% 到 50%。 《MySQL实战45讲》的第14章,也有介绍这一点
sheep"SHOW TABLE STATUS 也能看到一个 TABLE_ROWS 列,代表表的行数,那么能不能用这个来优化 COUNT(*)?" 不太行,索引统计的值是通过采样来估算的。实际上,TABLE_ROWS 就是从这个采样估算得来的,因此它也很不准。有多不准呢,官方文档说误差可能达到 40% 到 50%。 《MySQL实战45讲》的第14章,也有介绍这一点作者回复: 确实,哈哈哈,不过糊弄老板的时候可以用用。
2023-09-26归属地:广东2- sheep"优化 COUNT"这里"考虑使用 Redis 之类的 NoSQL 来直接记录总数",这里不太好记录吧,像MySQL有一致性视图就很难模拟吧,市场有啥成熟的案例咩
作者回复: 也没你想象中的那么麻烦,就是业务层面上,操作数据库的时候,顺便操作一下redis。不过如果 COUNT 的 WHERE 条件很复杂,就很难处理。
2023-09-25归属地:广东1  humor修改索引或者说表定义变更的核心问题是数据库会加表锁,直到修改完成。 好像mysql是支持online ddl的吧。那如果支持的话,是不是对大表也可以直接ddl了
humor修改索引或者说表定义变更的核心问题是数据库会加表锁,直到修改完成。 好像mysql是支持online ddl的吧。那如果支持的话,是不是对大表也可以直接ddl了作者回复: 风险还是很大的……因为虽然online DDL 不会阻塞增删改查,但是对服务器的压力还是存在的。也就是你这段时间 mysql 的负载还是很高。所以要看你能不能接受这种性能损耗。
2023-07-19归属地:浙江2 ZhiguoXue_IT在之前的团队中用过强制force指定索引,之所以这样做是为了在mysql表的数据量特别大的时候,mysql自己的内部优化器会给推荐别的索引,现实中发现强制有另一个索引,查询的性能会很大,也就是可以理解为mysql自己的查询优化器有时候会选择错误的索引
ZhiguoXue_IT在之前的团队中用过强制force指定索引,之所以这样做是为了在mysql表的数据量特别大的时候,mysql自己的内部优化器会给推荐别的索引,现实中发现强制有另一个索引,查询的性能会很大,也就是可以理解为mysql自己的查询优化器有时候会选择错误的索引作者回复: 确实,我以前也做过这种优化,不过还是挺罕见的场景
2023-07-18归属地:北京- ZhiguoXue_IT1)请教一下老师,select count(distinct(name)) from user 这条sql如何优化,能用group by优化吗?select name from user group by name;
作者回复: GROUP BY 应该不行。不过要是 name 上有单独的索引,那么查询效果还可以。 有一种不精确的做法,就是线下计算一次,count(distinct(name)) 和 count(name),确认两者的比率。而后线上就只需要用 count(name) 乘以比例就可以了。又或者在 Redis 里面维护总数。
2023-07-18归属地:北京

