

20|分库分表容量预估:分库分表的时候怎么计算需要多少个库多少个表?

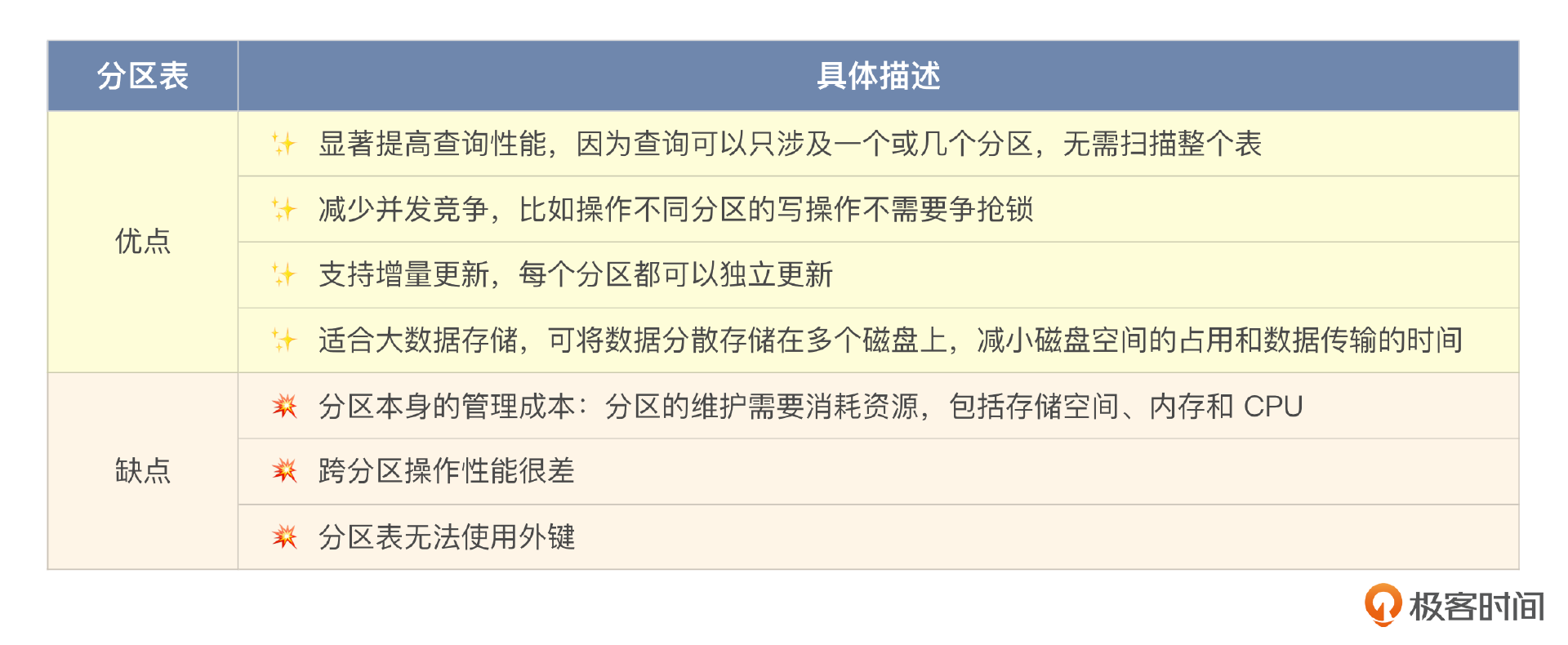
分区表
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

分库分表容量预估是数据库设计中的关键环节,本文深入探讨了分区表、2 的幂与数据迁移、面试准备和基本思路等内容。首先,分区表适用于与时间相关的业务场景,而容量规划时常采用 2 的幂,便于使用位运算进行分库分表。在面试准备方面,建议了解公司的分库分表情况、核心业务数据量和使用分区表情况,以展现自身竞争力。基本思路围绕面试官可能提出的问题展开,包括为何分库分表、何时需要分库分表、分库分表的方式和计算方法等。文章还探讨了分库分表与分区表、读写分离的对比,以及分库分表的原因和扩容亮点。此外,还介绍了高级的数据迁移校验方案,包括流量复制与重放,以及解决方案中的问题和优势。总的来说,本文为读者提供了深入了解分库分表容量预估的基本知识和面试准备建议,以及高级的数据迁移校验方案。
《后端工程师的高阶面经》,新⼈⾸单¥59

全部留言(7)
- 最新
- 精选
 Johar1.需要迁走2/3的数据 2.一般页的大小是16KB,每行数据大小按照1KB,B+树按照三层,主键按照8byte,地址是6byte,所以第一,二层大小为16*1024 / (8+6) = 1170,总体大小就是1170*1170*16=21902400,大概就是2000万 在扩容的时候,我说 2 的幂翻倍扩容的话,只需要迁走一半的数据。如果改成用 3 的幂,原本你的数据是按照除以 3 的余数分库分表,现在变成除以 9 的余数分库分表,那么要迁走多少数据? 网络上有一种说法是超过 2000 万行数据就要分表了,你知道这个 2000 万是怎么来的吗?
Johar1.需要迁走2/3的数据 2.一般页的大小是16KB,每行数据大小按照1KB,B+树按照三层,主键按照8byte,地址是6byte,所以第一,二层大小为16*1024 / (8+6) = 1170,总体大小就是1170*1170*16=21902400,大概就是2000万 在扩容的时候,我说 2 的幂翻倍扩容的话,只需要迁走一半的数据。如果改成用 3 的幂,原本你的数据是按照除以 3 的余数分库分表,现在变成除以 9 的余数分库分表,那么要迁走多少数据? 网络上有一种说法是超过 2000 万行数据就要分表了,你知道这个 2000 万是怎么来的吗?作者回复: 赞!
2023-07-31归属地:重庆2- Geek8004逻辑数据库引起的性能瓶颈,这个怎么理解呀。能举个例子吗
作者回复: 比如说数据库使用的 Innodb 引擎的 buffer pool 这种整个实例共享的资源出现瓶颈。
2023-08-30归属地:上海21  humor如果是逻辑数据库引起的性能瓶颈,那么你就只需要在逻辑数据库这个层面进一步分库就可以了。 逻辑数据库可能有什么性能瓶颈呢?
humor如果是逻辑数据库引起的性能瓶颈,那么你就只需要在逻辑数据库这个层面进一步分库就可以了。 逻辑数据库可能有什么性能瓶颈呢?作者回复: 基本上不太可能单独遇到,都是逻辑数据库出性能瓶颈了,那么所在的物理机器的瓶颈也差不多到了。 所以我个人是比较认为,如果只是逻辑上分了库,但是实际上并没有分离,其实没太大的效果。比如说是在 10.10.1.1:3306 上面创建了两个数据库,db_0 和 db_1,我觉得就没啥效果。那么 db_0 遇到了什么跟硬件有关的性能瓶颈,db_1 也肯定遇到了。
2023-08-03归属地:浙江2- humor流量复制与重放,这种数据检测机制不可能把所有的数据都检测一遍吧,肯定存在有的数据写了,但是没有去读的情况,或者历史数据大概率不会经常被请求,也就无法被检测到。
作者回复: 是的,这种检测方式更加多的是验证流程没有问题,不是验证全部数据没有问题。验证全部数据是必须要全量校验与修复的。
2023-08-01归属地:浙江  peter请教老师几个问题: Q1:“分区表”是指业务层面的分表?还是MySQL内部底层实现的概念?我认为是业务层面的分表,比如按月分,就是业务层面;但是文中有一句“分区表是表的底层组织方式。简单来说,分区表就是把一张表分成几块,每一块存储在磁盘的一个地方”,这句话让我理解成“MySQL底层的分表”。 Q2:用了Oracle就不用分库分表了吗? 小型公司,可能用Oracle不用分库分表了。但中大型公司,用Oracle以后估计还需要使用分库分表吧,只不过分得少,比如用MySQL需要100个库,但用Oracle只需要10个库。是这样吗? Q3:Nginx将HTTPS转换为HTTP,是自动转换的吗?还是需要做一些配置? Q4:流量复制与重放为什么公司很少做?不准确吗?还是因为成本高?
peter请教老师几个问题: Q1:“分区表”是指业务层面的分表?还是MySQL内部底层实现的概念?我认为是业务层面的分表,比如按月分,就是业务层面;但是文中有一句“分区表是表的底层组织方式。简单来说,分区表就是把一张表分成几块,每一块存储在磁盘的一个地方”,这句话让我理解成“MySQL底层的分表”。 Q2:用了Oracle就不用分库分表了吗? 小型公司,可能用Oracle不用分库分表了。但中大型公司,用Oracle以后估计还需要使用分库分表吧,只不过分得少,比如用MySQL需要100个库,但用Oracle只需要10个库。是这样吗? Q3:Nginx将HTTPS转换为HTTP,是自动转换的吗?还是需要做一些配置? Q4:流量复制与重放为什么公司很少做?不准确吗?还是因为成本高?作者回复: 1. MySQL 底层的分区表。你说的按月分区,事实上也是利用 MySQL 的底层分区机制。 2. 不用…… Oracle 是真的强,之前我们的支付业务就是 Oracle 打天下,没有分库分表也撑住了。 3. 你用了 nginx 配置转发流量就可以了。相当于,浏览器和 nginx 是 HTTPS,nginx 转发到你的后台服务,是 HTTP 4. 成本高,收益不是很高。而且你注意到我里面讲到一个重放的时候,数据可能已经被修改过了的问题,难以解决,所以用起来效果不是很好。
2023-08-01归属地:北京 ZhiguoXue_IT1)我理解,比如扩容的时候,之前是8张表,我们新建16张表,即使按照2的倍数,迁移数据到新的表,还是需要全量迁移,作者的意思是前8张表不变,然后新加8张表吗? 2)第二题就是从b+树的角度来衡量单表的存储量
ZhiguoXue_IT1)我理解,比如扩容的时候,之前是8张表,我们新建16张表,即使按照2的倍数,迁移数据到新的表,还是需要全量迁移,作者的意思是前8张表不变,然后新加8张表吗? 2)第二题就是从b+树的角度来衡量单表的存储量作者回复: 1. 是的。当然,你要全量迁移也可以,从研发工作量上来说没多少区别。无非就是迁移程序运行久一点还是短一点。
2023-07-31归属地:北京
 陈斌第一个问题,迁移数据2/3。 第二个问题,增加索引深度。MySQL 默认是 16K 的页面,抛开它的配置 header,大概就是 15K,因此,非叶子节点的索引页面可放 15*1024/12=1280 条数据,按照每行 1K 计算,每个叶子节点可以存 15 条数据。同理,三层就是 15*1280*1280=24576000 条数据。只有数据量达到 24576000 条时,深度才会增加为 4
陈斌第一个问题,迁移数据2/3。 第二个问题,增加索引深度。MySQL 默认是 16K 的页面,抛开它的配置 header,大概就是 15K,因此,非叶子节点的索引页面可放 15*1024/12=1280 条数据,按照每行 1K 计算,每个叶子节点可以存 15 条数据。同理,三层就是 15*1280*1280=24576000 条数据。只有数据量达到 24576000 条时,深度才会增加为 4作者回复: 赞!厉害!
2023-07-31归属地:广东

