

34|Spark + Kafka:流计算中的“万金油”
吴磊

你好,我是吴磊。
在前面的几讲中,咱们不止一次提到,就数据源来说,Kafka 是 Structured Streaming 最重要的 Source 之一。在工业级的生产系统中,Kafka 与 Spark 这对组合最为常见。因此,掌握 Kafka 与 Spark 的集成,对于想从事流计算方向的同学来说,是至关重要的。
今天这一讲,咱们就来结合实例,说一说 Spark 与 Kafka 这对“万金油”组合如何使用。随着业务飞速发展,各家公司的集群规模都是有增无减。在集群规模暴涨的情况下,资源利用率逐渐成为大家越来越关注的焦点。毕竟,不管是自建的 Data center,还是公有云,每台机器都是真金白银的投入。
实例:资源利用率实时计算
咱们今天的实例,就和资源利用率的实时计算有关。具体来说,我们首先需要搜集集群中每台机器的资源(CPU、内存)利用率,并将其写入 Kafka。然后,我们使用 Spark 的 Structured Streaming 来消费 Kafka 数据流,并对资源利用率数据做初步的分析与聚合。最后,再通过 Structured Streaming,将聚合结果打印到 Console、并写回到 Kafka,如下图所示。
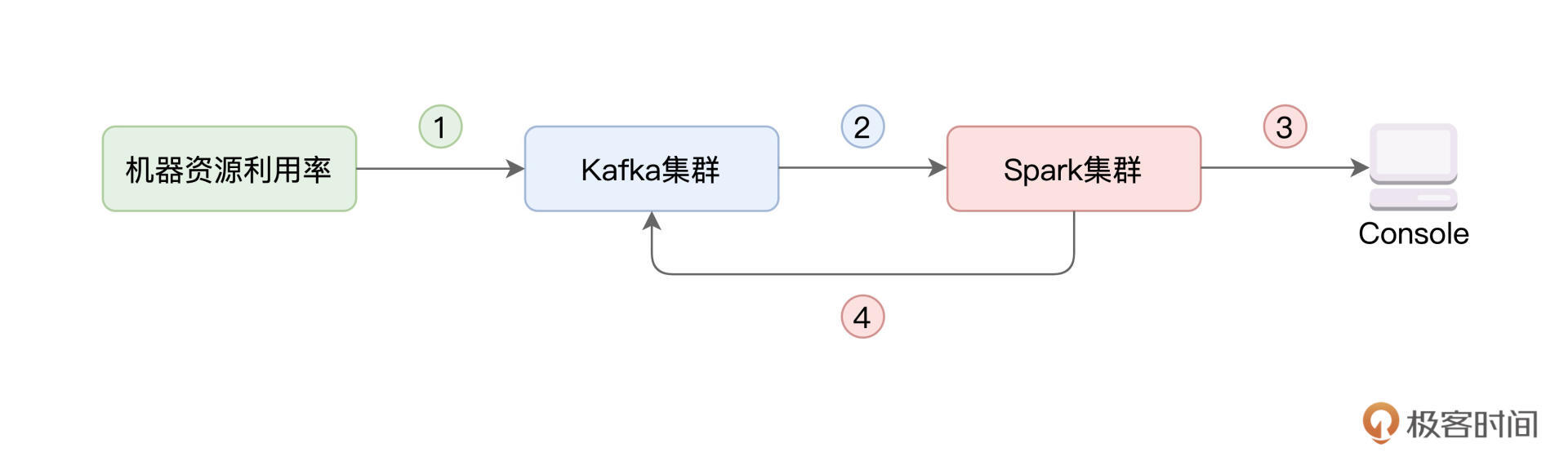
资源利用率实时计算流程图
一般来说,在工业级应用中,上图中的每一个圆角矩形,在部署上都是独立的。绿色矩形代表待监测的服务器集群,蓝色矩形表示独立部署的 Kafka 集群,而红色的 Spark 集群,也是独立部署的。所谓独立部署,它指的是,集群之间不共享机器资源,如下图所示。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文深入介绍了如何在流计算中集成Spark与Kafka,实现资源利用率的实时计算。首先详细介绍了Kafka环境的准备和配置,包括安装ZooKeeper、Kafka,以及创建Topic。然后通过示例代码展示了如何利用Java的反射机制获取CPU与内存利用率,并将数据发送给Kafka集群。重点讲解了Kafka与Spark的集成过程,包括使用Structured Streaming消费Kafka数据、进行初步聚合,并将结果打印到终端以及写回到Kafka。文章还提到了Kafka的基本概念与特性,以及Kafka与Spark集成的关键要点。整体而言,本文内容丰富,对于从事流计算方向的读者具有很高的参考价值。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《零基础入门 Spark》,新⼈⾸单¥59
《零基础入门 Spark》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(1)
- 最新
- 精选
 毕务刚老师, 有个需求是利用spark stream读kafka,分析后更新几个 mongodb表, 有几个疑问。 1. 如果利用foreach sink 更新mongodb表, foreach sink 是运行在driver侧, 还是 executor侧,如果是运行在driver侧, 那么并行处理能力是不是很差(没有利用executor的资源) 2. 如果利用 foreachBatch sink 更新mongodb表, structured-streaming-programming-guide中foreachBatch sink的Fault-tolerant是Depends on the implementation,是不是说 foreachBatch sink 不能利用checkpoint来获得已经处理的offset? 这种情况下, 如果管理 kafka的offset?
毕务刚老师, 有个需求是利用spark stream读kafka,分析后更新几个 mongodb表, 有几个疑问。 1. 如果利用foreach sink 更新mongodb表, foreach sink 是运行在driver侧, 还是 executor侧,如果是运行在driver侧, 那么并行处理能力是不是很差(没有利用executor的资源) 2. 如果利用 foreachBatch sink 更新mongodb表, structured-streaming-programming-guide中foreachBatch sink的Fault-tolerant是Depends on the implementation,是不是说 foreachBatch sink 不能利用checkpoint来获得已经处理的offset? 这种情况下, 如果管理 kafka的offset?作者回复: 一个个来说哈~ 1)一定是在Executors侧的~ 抛开流处理不说,想一想RDD的foreach,对比着来理解就可以了~ foreach更多的,是让开发者灵活地定义Actions 2)foreachBatch其实也是类似,让开发者能以Micro-batch为粒度,去定义Actions。不过,这里说的“容错取决于实现”,并不是说不能用Checkpoint,而是说,Spark本身只能做到“At least once”,要实现Exactly once,还是要看foreachBatch里面,具体写到哪个Sink去,以你的例子,是写到MongoDB。说白了,就是如果你想做到Exactly once,那么你需要自己在应用的层面,保证Structured Streaming + MongoDB端到端做到Exactly once,比如利用MongoDB提供的一些机制,在应用的代码中,争取做到Exactly Once
2021-12-132
收起评论

