

31|新一代流处理框架:Batch mode和Continuous mode哪家强?

计算模型
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

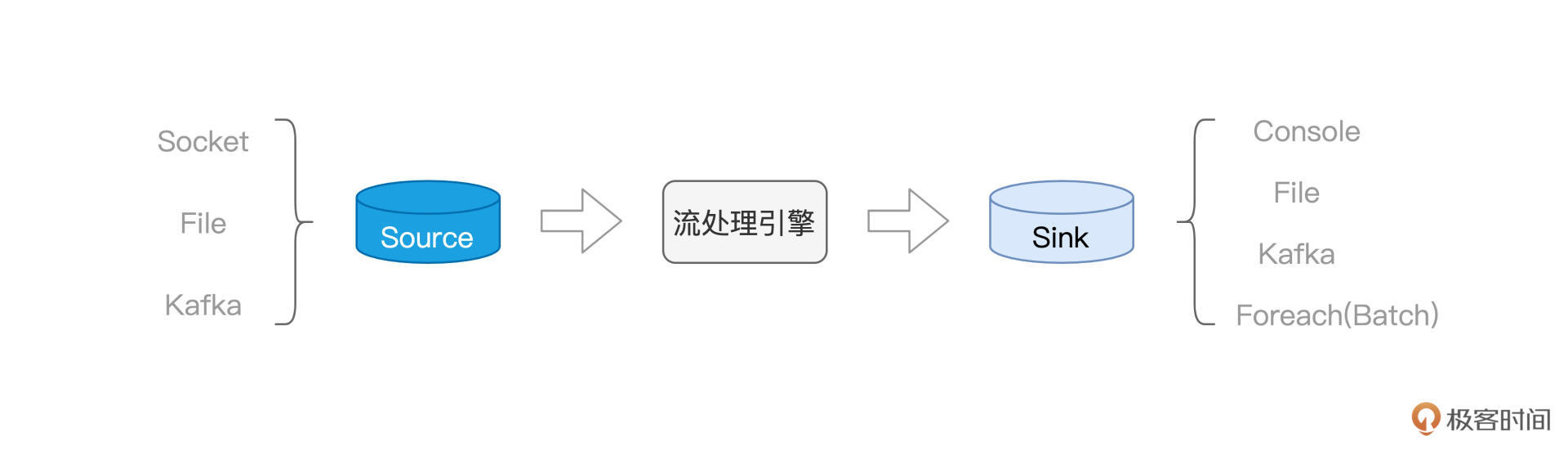
Structured Streaming是Spark的重要子框架之一,具有良好的执行性能和扩展性。文章介绍了Structured Streaming的计算模型和容错机制。在计算模型方面,Structured Streaming支持Batch mode和Continuous mode两种计算模型。Batch mode将连续的数据流切割为离散的数据微批,触发Spark Job进行处理,适用于高吞吐量但延迟较高的场景;而Continuous mode以事件/消息为粒度,采用常驻作业来处理数据流,具有低延迟但吞吐量较低。在容错机制方面,Structured Streaming结合幂等的Sink,能够提供Exactly once的容错能力,保证数据的不重不漏。Batch mode利用Checkpoint机制实现容错,将Micro-batch的元信息存储到文件系统路径,以恢复数据流的“断点续传”,但会带来一定的处理延迟。Continuous mode则采用不同的实现方式来实现容错。总的来说,Structured Streaming适用于不同的实时计算需求,读者可以根据具体场景选择合适的计算模型和容错机制。Continuous mode通过Epoch Marker机制实现容错,避免微批处理带来的延迟,提供更低的处理延迟。Continuous mode还支持非聚合类操作,但暂时不支持聚合类操作,这一点需要读者特别注意。整体来看,文章深入浅出地介绍了Structured Streaming的计算模型和容错机制,为读者提供了全面的了解和选择指南。
《零基础入门 Spark》,新⼈⾸单¥59

全部留言(6)
- 最新
- 精选
 刘启涛课后习题: 我觉得先消费再记录的方式是可以实现,但是如果记录的时候出现异常(hdfs写数据网络抖动),可能会导致数据重复消费,这种方式“Exactly Once”的准确性没有先记录、再消费数据高。 老师,我这里还有一个问题,Continuous mode是处理完数据异步记录日志,感觉很难保证“刚好一次”
刘启涛课后习题: 我觉得先消费再记录的方式是可以实现,但是如果记录的时候出现异常(hdfs写数据网络抖动),可能会导致数据重复消费,这种方式“Exactly Once”的准确性没有先记录、再消费数据高。 老师,我这里还有一个问题,Continuous mode是处理完数据异步记录日志,感觉很难保证“刚好一次”作者回复: 老弟思考的很到位~ 从实现上来说,先消费再记录的方式,肯定是可以实现的。不过这样一来,会有几方面的问题: 1)首先是老弟提到的,数据处理失败,就存在一个重试的问题,如果是先写WAL(数据+元数据),再消费,因为数据已经落盘(本地或是HDFS)缓存了,因此再消费一遍,很容易,也很方便。但如果反过来,先消费、再写日志,那就得从Source重新拉数据,网络开销是一方面,再者,为了确保拉取的是同一份数据,实际上也需要维护元数据,来管理offsets 2)再一个,即便是没有失败重试的问题,在batch mode下,一个批次的数据,还是以批次为粒度,来触发一个job,这中间的任务调度延迟,其实仅靠先处理数据,是去不掉的。这个跟Continuous mode很不一样,Continuous mode是常驻的job,因此不存在这个问题。 关于老弟说的“Exactly once”,严格来说,Spark自己不能保证“Exactly once”,但它可以做到“At least once”,再结合幂等的Sink,端到端可以做到“Exactly once”。但是就Structured Streaming来说,它自己只能做到“At least once”。
2021-12-025 六月的余晖老师,可以比较一下Continuous mode和Flink 吗
六月的余晖老师,可以比较一下Continuous mode和Flink 吗作者回复: 好问题,先说结论,虽然咱们的主题是Spark,不过就追求实时性的流处理来说,我还是会推荐Flink。 Flink的Kappa架构,天然对流处理友好,尤其是对于实时性的支持。因为出发点就是流计算,因此随着Flink的发展、迭代,开发API也越来越丰富,功能也越来越完善。 而Spark不同,Spark实际上是Lambda架构,天然以批处理为导向,最初的流处理,也是微批模式,也就是Micro-batch,咱们分析了,微批模式,没法保证实时性,不过对于高吞吐,倒是比较友好。尽管Spark官方推出了Continuous mode,但是目前功能、API各方面还没有那么完善,至少现在为止,Continuous mode还不支持聚合操作,仅这一点,限制就太大了,试问现在的数据处理,有多少逻辑是不需要聚合操作的呢?太少了。因此,Continuous mode,在我看来,更多的是一种尝试和探索,至于后续能否提供更多的功能与能力,还要看Spark社区对于这方面的发力。 不过,从课程内容的角度,我们还是得让大家知道,Spark社区推出了这么一种Continuous mode。一方面是让大家知道有这么回事,再者和Micro batch mode是个对比,有利于大家做对比学习,加深印象 但是就能力来说,从实时性和功能完善的角度出发, 我觉得,还是Flink更加实用
2021-11-222- Geek_995b78老师,后面课程没有spark streaming内容的讲解吗
作者回复: 课程主要围绕Structure Streaming哈
2021-11-22 - Geek_995b78老师,虽然kafka幂等性不能保证跨分区的原子写入,但是kafka还支持事务呀
作者回复: 感谢老弟提醒,上一个留言,一起回复了哈~
2021-11-22 - Geek_995b78老师,0.11版本后的kafka,引入了幂等性机制呀,文中问什么说kafka不是幂等的呢
作者回复: 感谢老弟的提醒,原文的描述确实有问题~ 新版本的Kafka确实在Producer级别支持幂等和事务性,结合transactional id + PID + sequence number,能做到跨会话、跨Topic Partition做到幂等。再结合Structured Streaming对于Event time、Late Data和Watermark的支持,以及WAL和Checkpoint机制,理论上,Structured Streaming + Kafka确实可以做到Exactly once。 原文的表述有误,当时脑子里想的是老的Spark Streaming,由于不支持事件时间,仅支持Processing time,而一般的时间窗口,都会有group by这些带状态的计算。因此即便是结合Kafka的幂等性,也很难做到Exactly once的Delivery。 再次感谢老弟,我回头抽空调整下原文的描述,谢谢~
2021-11-22  Geek1185为什么batch mode的WAL不做成异步的形式呢?2023-02-06归属地:北京
Geek1185为什么batch mode的WAL不做成异步的形式呢?2023-02-06归属地:北京

