

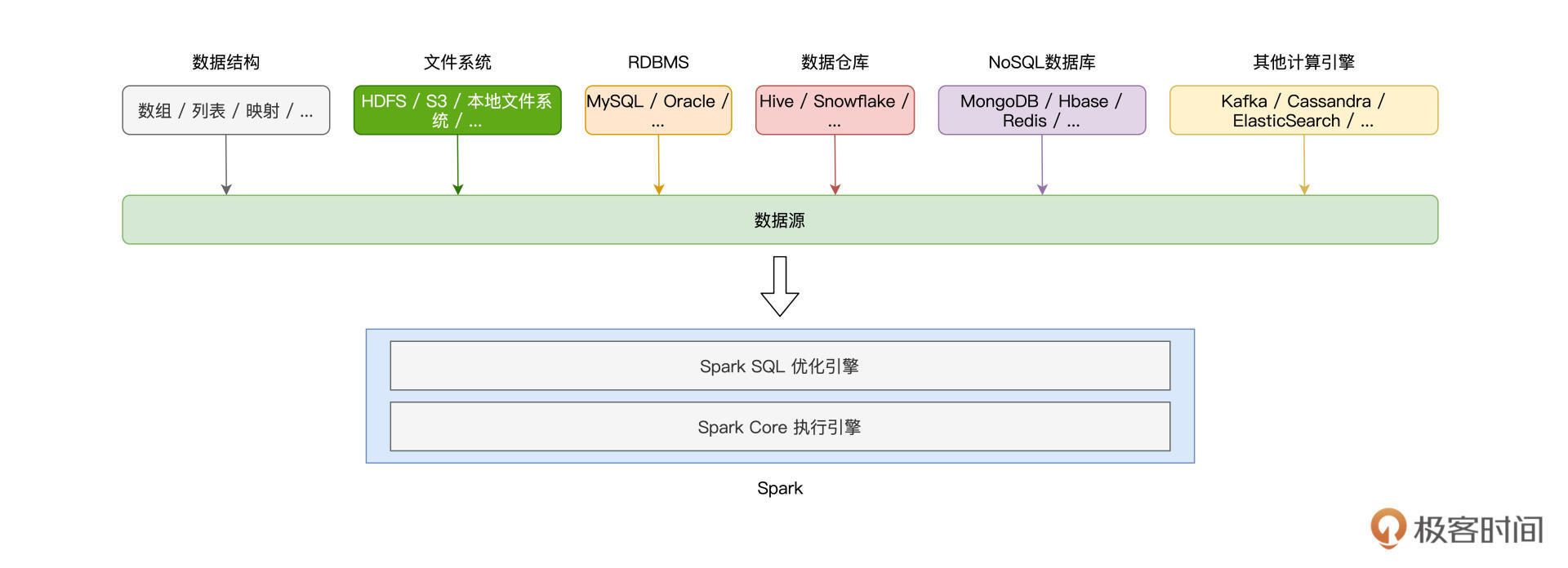
15 | 数据源与数据格式:DataFrame从何而来?

 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文详细介绍了使用Spark创建DataFrame的方法,包括从不同文件格式和关系型数据库中创建DataFrame的步骤和技巧。首先,文章介绍了从CSV、Parquet和ORC文件创建DataFrame的方法,包括加载选项和显式定义Data Schema。其次,针对关系型数据库,文章详细介绍了使用read API连接数据库并创建DataFrame的步骤,包括设置数据库连接参数和控制DataFrame的并行度。此外,文章还提到了需要手动拷贝相关数据库的Jar包到Spark安装目录下的Jars文件夹,并在spark-shell命令或spark-submit中指定相关Jar包的访问地址。最后,文章总结了DataFrame的创建方式,包括使用createDataFrame方法和read API,以及利用隐式方法和调用toDF方法创建DataFrame。总的来说,本文通过详细介绍了不同文件格式和关系型数据库下创建DataFrame的方法,为读者提供了丰富的知识和实用的技术指导。
《零基础入门 Spark》,新⼈⾸单¥59

全部留言(15)
- 最新
- 精选
 welldo老师, 对于 max=“male”同时 min=“male”的 gender 文件来说 这句话没有读懂,求解释.
welldo老师, 对于 max=“male”同时 min=“male”的 gender 文件来说 这句话没有读懂,求解释.作者回复: 就是说,某个文件分区,其中的gender字段,最大值是male、最小值也是male,其实,这意味着文件里面的gender字段,都是male,没有female,所以,当查询中有where gender = “female”的时候,这个文件分区可以被直接跳过,不扫描、不产生磁盘I/O,从而提升文件读取效率~
2021-11-103 火炎焱燚Python 代码: # 下面是我在notebook上运行的,可以得到结果,拿出来分享 from pyspark import SparkContext, SparkConf from pyspark.sql.session import SparkSession sc = SparkContext() spark = SparkSession(sc) seq=[('Bob',14),('Alice',18)] rdd=sc.parallelize(seq) column = ['name','age'] dataframe=spark.createDataFrame(seq,column) seq=[('Bob',14),('Alice',18)] rdd=sc.parallelize(seq) column = ['name','age'] df2=rdd.toDF(column) csvFilePath='file:///home/ray/DataSet/learn-spark/chapter15/info.txt' df=spark.read.format('csv').option('header',True).load(csvFilePath) from pyspark.sql.types import (StringType,StructField,StringType,IntegerType) schema = StructType([ StructField("name", StringType(), True), StructField("age", IntegerType(), True), ]) df2=spark.read.format('csv').option('header',True).load(csvFilePath) df3=spark.read.format('csv').schema(schema).option('header',True).option('mode','dropMalformed').load(csvFilePath) parquetFilePath='file:///home/RawData/lucky/batchNum=201705/part-00000-a4ecpy.parquet' df1=spark.read.format('parquet').load(parquetFilePath) # or df2=spark.read.parquet(parquetFilePath) from pyspark import SparkContext, SparkConf from pyspark.sql.session import SparkSession sc = SparkContext() spark = SparkSession(sc) df=spark.read.format("jdbc").option("driver", "com.mysql.cj.jdbc.Driver").option("url", "jdbc:mysql://localhost:3306/DBName").option("user", "username").option("password","password").option("numPartitions", 20).option("dbtable", "tableName").load() sqlQuery='(select * from django_content_type where app_label = "auth")T' df2=spark.read.format("jdbc").option("driver", "com.mysql.cj.jdbc.Driver").option("url", "jdbc:mysql://localhost:3306/DBName").option("user", "username").option("password","password").option("numPartitions", 20).option("dbtable", sqlQuery).load()
火炎焱燚Python 代码: # 下面是我在notebook上运行的,可以得到结果,拿出来分享 from pyspark import SparkContext, SparkConf from pyspark.sql.session import SparkSession sc = SparkContext() spark = SparkSession(sc) seq=[('Bob',14),('Alice',18)] rdd=sc.parallelize(seq) column = ['name','age'] dataframe=spark.createDataFrame(seq,column) seq=[('Bob',14),('Alice',18)] rdd=sc.parallelize(seq) column = ['name','age'] df2=rdd.toDF(column) csvFilePath='file:///home/ray/DataSet/learn-spark/chapter15/info.txt' df=spark.read.format('csv').option('header',True).load(csvFilePath) from pyspark.sql.types import (StringType,StructField,StringType,IntegerType) schema = StructType([ StructField("name", StringType(), True), StructField("age", IntegerType(), True), ]) df2=spark.read.format('csv').option('header',True).load(csvFilePath) df3=spark.read.format('csv').schema(schema).option('header',True).option('mode','dropMalformed').load(csvFilePath) parquetFilePath='file:///home/RawData/lucky/batchNum=201705/part-00000-a4ecpy.parquet' df1=spark.read.format('parquet').load(parquetFilePath) # or df2=spark.read.parquet(parquetFilePath) from pyspark import SparkContext, SparkConf from pyspark.sql.session import SparkSession sc = SparkContext() spark = SparkSession(sc) df=spark.read.format("jdbc").option("driver", "com.mysql.cj.jdbc.Driver").option("url", "jdbc:mysql://localhost:3306/DBName").option("user", "username").option("password","password").option("numPartitions", 20).option("dbtable", "tableName").load() sqlQuery='(select * from django_content_type where app_label = "auth")T' df2=spark.read.format("jdbc").option("driver", "com.mysql.cj.jdbc.Driver").option("url", "jdbc:mysql://localhost:3306/DBName").option("user", "username").option("password","password").option("numPartitions", 20).option("dbtable", sqlQuery).load()作者回复: 棒棒棒!!!
2021-10-233- 姚礼垚老师,RDD[Row]怎么理解,和RDD[String]这些有啥区别呢
作者回复: RDD[Row],RDD[String],都是RDD,但是元素类型不同,Row实际上是对象,Class,是带Schema的Tuple;而String就是字符串。
2021-12-172  GAC·DU老师,感觉最近更新的Spark SQL没有Spark core有深度了?是我直觉性错误,还是我没有get到老师聊的点呢
GAC·DU老师,感觉最近更新的Spark SQL没有Spark core有深度了?是我直觉性错误,还是我没有get到老师聊的点呢作者回复: 其实入门课的4部分,深度都没有太深,主要是考虑确实有不少零基础的同学,需要照顾到~ 老弟有这种感觉,说明你Spark SQL的底子比较好,哈哈 性能篇的话,会深入很多,其实也是因为很多同学反馈性能篇难度偏高,我这边才会考虑出个入门篇,去满足不同同学的需求。 确实,入门篇对于不少同学来说,可能会偏浅,先跟老弟说声抱歉吧。不过也是好事,说明老弟在Spark这方面还是有不少积累的~
2021-10-131- Geek_f09d5e发现小失误,CSV文件分隔列数据的分隔符不是“seq”,是“sep”
作者回复: 感谢老弟提醒~ 这里确实typo了,回头让编辑帮忙修改一下,感谢!
2022-02-13  我爱夜来香老师,我连接oracle时dbtable选项指定表名成功了,指定的是个sqlquery报错:表名无效
我爱夜来香老师,我连接oracle时dbtable选项指定表名成功了,指定的是个sqlquery报错:表名无效作者回复: 讲道理应该是没问题的,老弟check一下,是不是sql query里的表名字,没有带database前缀,就是像这样:“your_database.table_name”
2022-01-22 王璀璨老师 sql语句查询后面默认加where 1=0的报错: java.sql.SQLSyntaxErrorException: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'select * from HaoDF_article limit 2000 WHERE 1=0' at line 1
王璀璨老师 sql语句查询后面默认加where 1=0的报错: java.sql.SQLSyntaxErrorException: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'select * from HaoDF_article limit 2000 WHERE 1=0' at line 1作者回复: 问题同上,需要提供更多信息哈~
2021-10-29- 王璀璨老师,sql语句后面默认加where 1=0的报错 java.sql.SQLSyntaxErrorException: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'select * from HaoDF_article limit 2000 WHERE 1=0' at line 1
作者回复: 能给下上下文吗?SQL语句通过什么提交的?spark.sql() API?另外,这个表HaoDF_article,是createTempView来的,还是existing的Hive表? 再者,想问后面加了个WHERE 1=0,这个是手工加的,还是为了保证SQL语句,代码自动加的?
2021-10-293 - 王璀璨老师请问一下spark.default.parallelism和numPartitions分别是什么意思,我看都有分块的意思,但是不懂其中的原理。
作者回复: spark.default.parallelism这个是RDD的默认并行度,比如你用parallelize创建RDD,默认并行度就是这个配置项的设置。 而numPartitions是RDD的属性之一,它指的是,当前RDD的并行度是多少~
2021-10-29  东围居士我在 spark-shell 中使用 failFast 模式的时候,并不会在 load 语句处出错,而是在执行 df.show 的时候才会报错
东围居士我在 spark-shell 中使用 failFast 模式的时候,并不会在 load 语句处出错,而是在执行 df.show 的时候才会报错作者回复: 可能原文说的不严谨,是的,你说的没错,应该在Action的地方才会抛运行时异常~ 毕竟Spark是Lazy evaluation,惰性计算,只有Action的时候,才会触发从头至尾的计算~
2021-10-29

